インスタンスデータの同期遅延
Download
フォーカスモード
フォントサイズ
現象の説明
TencentDB for MySQLのデフォルトのスレーブデータベース、ディザスタリカバリインスタンス、読み取り専用インスタンスはいずれもMySQLのネイティブbinlogレプリケーションテクノロジーを使用しており、データのレプリケーション方式が非同期または準同期レプリケーションの時、いずれも遅延が発生する恐れがあります。
故障の影響
スレーブデータベース に遅延が存在する場合、マスター/スレーブインスタンスが短時間で切り替えを完了できなくなり、これにより業務にも影響が出て、短時間で正常にリストアできなくなります。
ディザスタリカバリインスタンス に遅延が発生した場合、溜まったbinlogの適用が完了するまで、ディザスタリカバリインスタンスはマスターインスタンスに昇格できず、その間の業務の継続性に影響が与えられます。
読み取りサービスがデータの整合性に対して高い要求がある場合、読み取り専用グループが遅延削除ポリシーを設定することができます。読み取り専用インスタンスとマスターインスタンスの遅延時間がしきい値を超えた時、対応する読み取り専用インスタンスは自動的に削除され、それにより読み取りサービスは読み取り専用インスタンスに正常にアクセスすることができなくなります。
考えられる原因
非プライマリキーまたはセカンダリインデックス
binlogがrow形式でかつテーブルが非プライマリキーまたはセカンダリインデックスの場合、ビッグテーブルに対してDML操作(例:delete、update、insert)を行い、スレーブデータベースでbinlogアプリケーションを行う時、プライマリキーまたはセカンダリインデックスに基づき変更する必要のある行を検索します。対応するテーブルがプライマリキーまたはセカンダリインデックスを作成していない場合、大量の全テーブルスキャンが発生することによりログ応用の速度が低下し、その結果、データ遅延が発生します。
処理手順については、 非プライマリキーまたはセカンダリインデックスをご参照ください。
**大規模トランザクション
大規模トランザクション:特に、データを追加、削除、変更するinsert、update、delete、replcaeなどの文を指します。1つのトランザクションに数百万行のデータに対する操作が含まれること、または1つのSQL文が数百万行のデータを変更することが原因で、実行時間が30sを超えます。
マスターインスタンスがビッグデータを含むDML操作を実行し、大量のbinlogがスレーブデータベースに送信される際、スレーブデータベースはマスターインスタンスと同等の時間を費やして対応するトランザクションを完了する必要があり、それによりスレーブデータベースにデータ遅延が発生します。処理手順については、大規模トランザクションをご参照ください。
DDL操作
読み取り専用ノード上でユーザーのクエリーが上層で実行されるため、読み取り専用ノード上で実行時間が非常に長いクエリーが実行されると、このクエリーは、実行が完了するまでマスターデータベースからのDDLをブロックし、これにより読み取り専用ノードのデータ遅延が発生します。処理手順については、DDL操作をご参照ください。
インスタンスの仕様が小さすぎる
ディザスタリカバリインスタンス、読み取り専用インスタンスの規格がマスターインスタンスよりも小さく、かつ負荷が高いと、ディザスタリカバリインスタンス、読み取り専用インスタンスのデータ遅延が発生します。
処理手順については、インスタンス仕様が小さすぎるをご参照ください。
Waiting for table metadata lockのエラー
大規模トランザクションを実行すると、DDLがブロックされ、これが続くと同一テーブルのすべての後続の操作に支障が出ます。また、トランザクションを送信しない場合もDDLがブロックされ、これが続くと同一テーブルのすべての後続の操作に支障が出ます。
処理手順については、Waiting for table metadata lockのエラーをご参照ください。
処理手順
非プライマリキーまたはセカンダリインデックス
非プライマリキーまたはセカンダリインデックス
1. DBbrain コンソールにログインし、左側のナビゲーションウィンドウで診断最適化を選択し、上側で対応するデータベースを選択し、空間分析を選択します。
2. 空間分析画面の下側でプライマリキーなしテーブルを選択し、リストのプライマリキーなしテーブルをクリックすると、テーブルのフィールドとインデックス情報を表示することができます。
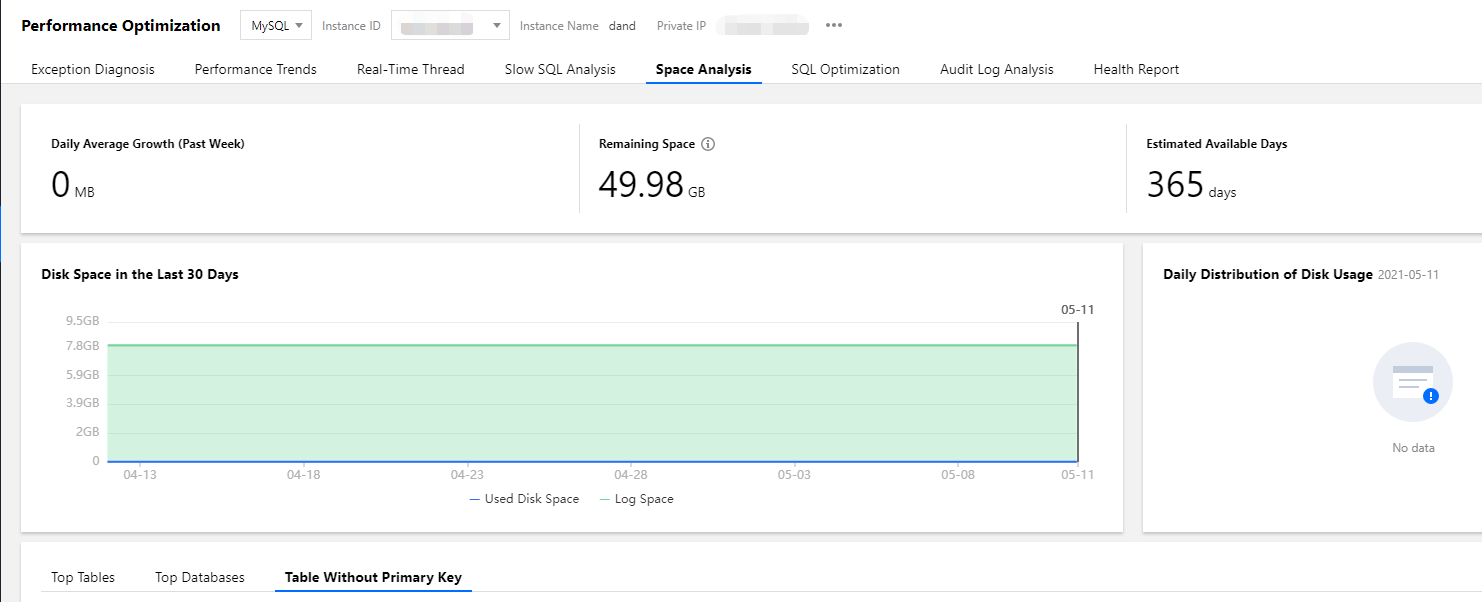
説明:
非プライマリキーテーブルリストは定期的なスキャン(スキャンの頻度は1日1回)と手動リフレッシュの2つの形式をサポートしており、実際の状況に応じて選択することができます。
3. 手順2の非プライマリキーテーブルにプライマリキーを作成します。テーブルにプライマリキーを作成できない場合、基数が高い列を選択してセカンダリインデックスを作成することをお勧めします。
大規模トランザクション
大規模トランザクション
1. DBbrain コンソールにログインし、異常アラーム画面で対応するデータベースとリージョンを選択し、診断項目でトランザクションによるレプリケーションの遅延にチェックを入れると、インスタンスの大規模トランザクションを絞り込んで表示することができます。
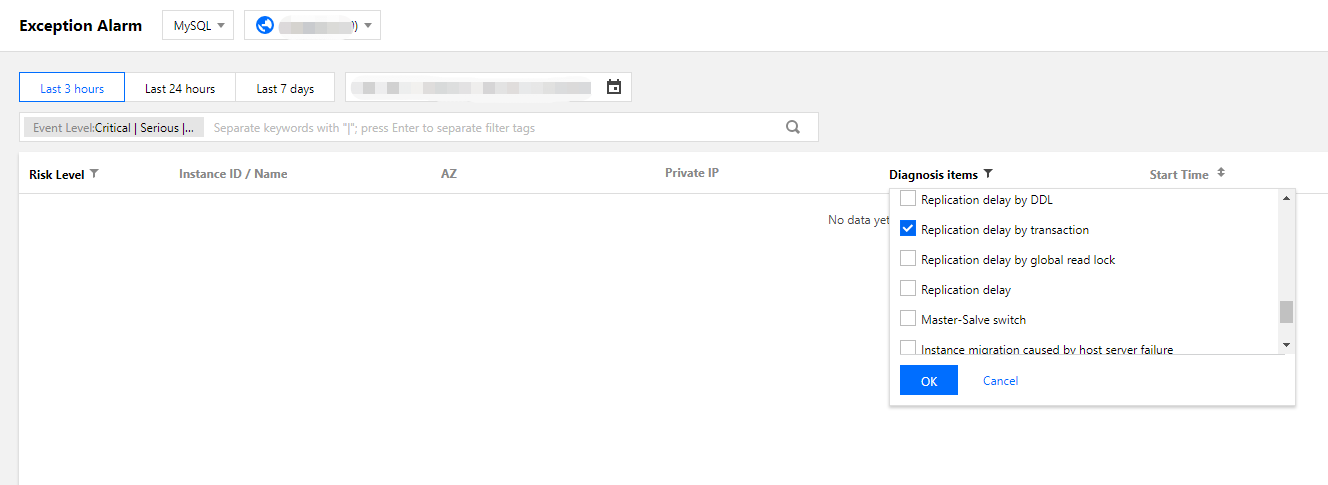
2. 大規模トランザクションを小さく分割し、where条件によって毎回処理するデータ量を制限します。
説明:
DBbrainによって大規模トランザクションを特定し、大規模トランザクションを小さく分割して実行すれば、読み取り専用ノードが迅速にトランザクションを完了でき、データ遅延が発生することはありません。
DDL操作
DDL操作
1. DBbrainコンソールにログインし、異常アラーム画面で対応するデータベースとリージョンを選択し、診断項目でDDLによるレプリケーションの遅延にチェックを入れると、インスタンスに対応するDDL操作を絞り込んで表示することができます。
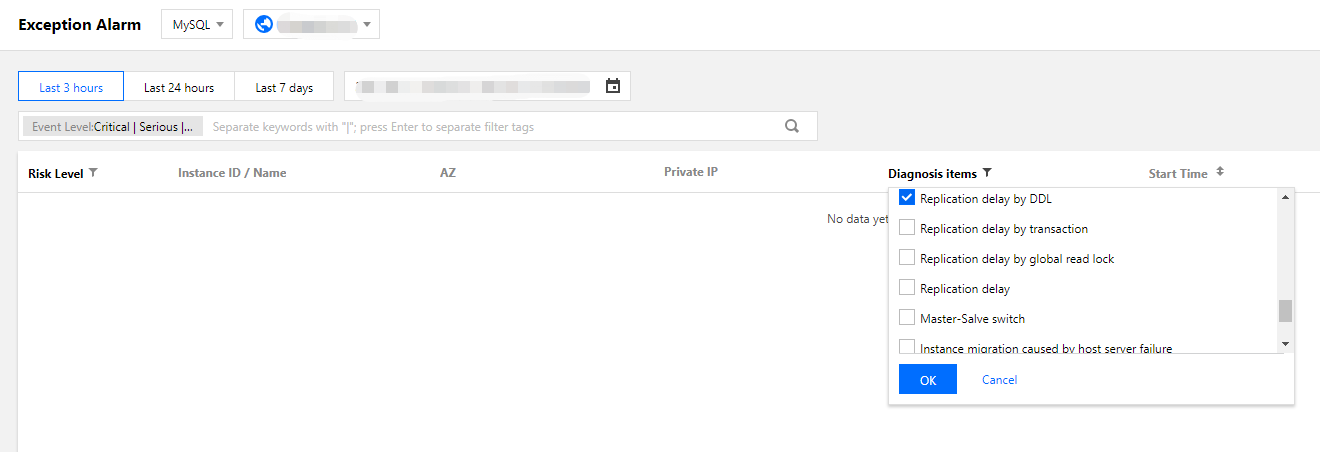
2. アラームリストで操作列の詳細をクリックすると、イベントの詳細画面に遷移して対処することができます。
イベントの詳細:診断項目、開始・終了時間、リスクレベル、持続時間、概要などの情報が含まれます。
現場の説明:異常イベント(またはヘルスチェックイベント)の外部パフォーマンス現象のスナップショットとパフォーマンスの傾向。
インテリジェント分析:パフォーマンス異常を引き起こす根本的な原因を分析し、具体的な操作を特定します。
最適化の提案:SQL最適化(インデックスの提案、書き換えの提案)、リソース設定の最適化およびパラメータのチューニングなどを含む最適化のガイダンスと提案を行います。
1. 読み取り専用インスタンスと災害復旧インスタンスの仕様をマスターインスタンス以上にすることをお勧めします。インスタンスの仕様はMySQLコンソール にログインし、インスタンスリストで確認できます。
2. 大量の分析型トランザクションの処理により、読み取り専用インスタンスと災害復旧インスタンスの負荷が過剰になった場合、そのインスタンスの仕様を適切なスペックに拡張するか、低パフォーマンスのSQL文を最適化する必要があります。
非効率性の最適化については、SQLの最適化をご参照ください。
インスタンス仕様のアップグレードについては、データベースインスタンスの仕様の調整をご参照ください。
[Waiting for table metadata lockのエラー](id:wftmlbc)
TencentDB for DBbrain を使用して実際の業務およびインスタンスに対する診断を行い、スロークエリーなどの指標を調査して、大規模トランザクションを特定することをお勧めします。
1. DBbrain コンソールにログインし、異常アラーム画面で対応するデータベースとリージョンを選択し、診断項目で**以下の項目にチェックを入れて、時間がかかる大規模トランザクションを特定します。
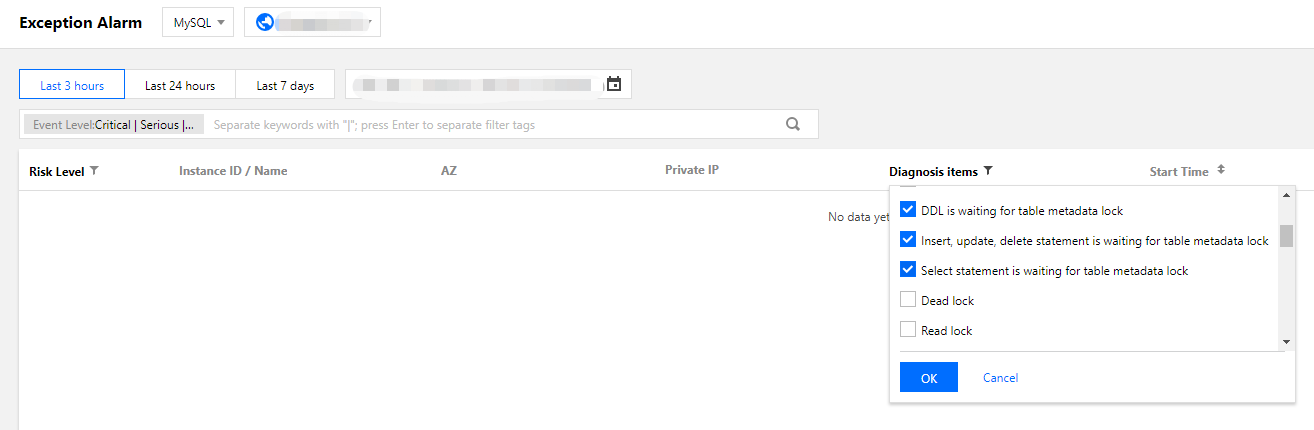
2. 次の各種故障シナリオへの対策を講じます:
大規模トランザクションを実行すると、DDLがブロックされ、これが続くと同一テーブルのすべての後続の操作に支障が出るため、DBbrainの異常診断プロンプトに基づき、大規模トランザクションのIDを見つけ出し、kill(強制終了) します。
トランザクションが送信されていないとDDLがブロックされ、これが続くと同一テーブルのすべての後続の操作に支障が出るため、DBbrainの異常診断に基づき、送信されていないトランザクションのIDを見つけ出し、kill(強制終了) すると同時にプログラムをチェックし、直ちにトランザクションを送信します。
明示的なトランザクションでは、 TableAに対して失敗した操作(存在しないフィールドをクエリーするなど)が実行されます。この時点でトランザクションは開始されていませんが、失敗したセンテンスによって取得されたロックは引き続き有効であり、解放されません。DBbrainの異常診断に基づき、sessionのIDを見つけ出し、 kill(強制終了)します。
フィードバック