- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Best Practices
- Message Queue Model
- Message Topic Model
- Migration Description
- Solutions and Cases
- API Documentation
- SDK
- Service Level Agreement
- Glossary
- Product Introduction
- Purchase Guide
- Getting Started
- Operation Guide
- Best Practices
- Message Queue Model
- Message Topic Model
- Migration Description
- Solutions and Cases
- API Documentation
- SDK
- Service Level Agreement
- Glossary
The first step in big data processing is to mine and analyze massive amounts of data in order to extract useful results and guide future business models. For example, Dianping.com and Didi Chuxing have made in-depth practices in Tencent Cloud services: the mobile app of Dianping.com pushes restaurants that are frequently shared by users on WeChat and Mobile QQ to its own consumers as recommendations.
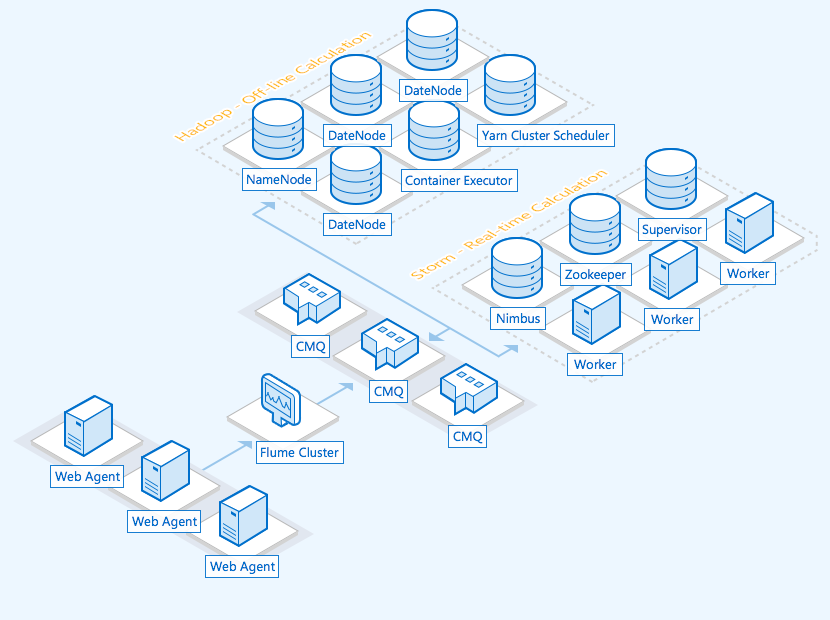
The data analysis system features can be mainly divided into the following modules: data collection, data ingestion, stream computing, offline computing, and data persistence.
- Data collection
It collects data from all nodes in real time by using open-source Flume. Data such as logs of all business servers will flow to the CMQ pipeline in the form of a funnel. - Data ingestion
As data collection and processing may be async in speed, to ensure stability and reliability of data write and analysis, the CMQ messaging middleware can be added as a buffer. - Stream computing and offline data analysis
Collected data is analyzed in real time with Apache Storm. Data mining is performed through offline data analysis based on Spark. - Data output
Analysis results can be persistently stored in services such as TencentDB for MySQL.
In data processing scenarios, the input of massive amounts of log data is the message producer, and the Storm cluster for online analysis is the message consumer. Practical experience shows that the message processing business logic of Storm as the message consumer may be complicated (which involves real-time computing, data stream processing, and topology data processing). Moreover, faults occur at a relatively high probability on Storm, which results in temporary consumption failures or instability. In summary, the efficiency of the message producer is much higher than that of the message consumer.
In the push model, the server cannot know the current status of the consumer, so it will continuously push the generated data. The consumer may have a heavier load and even crash if the push model is used when the Storm cluster is under high load, unless it has an appropriate mechanism that can inform the server of its status. In the pull model, this problem becomes much simpler. As the consumer actively pulls data from the server, it only needs to reduce its access frequency.
CMQ will launch the topic model with the pull and push data acquisition modes in the future. As a buffer between producer data and consumer data, CMQ enables data to be read only when the consumer is available and ready, which alleviates the out-of-sync issues between message producer and consumer.

 Yes
Yes
 No
No
Was this page helpful?