Regular Expressions for Subscription
Download
Focus Mode
Font Size
What is a regular expression?
A regular expression is used to search for a specific pattern from text.
A regular expression matches a string from left to right. "Regular expression" is often referred to as "regex" or "regexp" for short.
A regex can be used to replace text in strings, validate forms, extract a substring from a string based on a pattern match, and much more.
If you are developing an application, you may want to set rules on eligible usernames, which can contain letters, digits, underscores, and hyphens.
You may also want to limit the number of characters in a username for better display effect. The following regex can be used to validate a username:
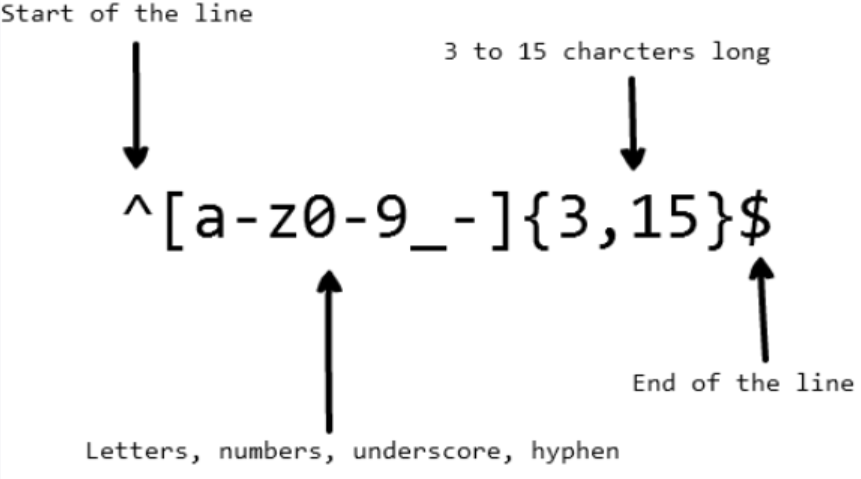
The above regex can match the strings
john_doe, jo-hn\\_doe, and john12\\_as, but not Jo as it contains an uppercase letter and is too short.Contents
Period
Asterisk
Braces
Anchors
Flags
Basic Matchers
A regex is just a pattern of characters used to perform a search in text. For example, the regex
cat means: the letter c, followed by the letter a , followed by the letter t."cat" => The cat sat on the mat
The regex
123 can match the string "123". A regex is matched against the input string by comparing each character in the regex with each character in the input string one by one.
Regexes are normally case-sensitive, so the regex Cat would not match the string "cat"."Cat" => The cat sat on the Cat
Metacharacters
Metacharacters are the building blocks of regexes. They do not stand for themselves; instead, they need to be interpreted in certain special ways. Some metacharacters enclosed in square brackets have special meaning.
Below are the metacharacters:
Metacharacter | Description |
. | Matches any character except a line break. |
[ ] | Character class, which matches any character enclosed in square brackets. |
[^ ] | Negated character class, which matches any character not enclosed in square brackets. |
* | Matches zero or more repetitions of the preceding subexpression. |
+ | Matches one or more repetitions of the preceding subexpression. |
? | Matches zero or one repetition of the preceding subexpression or specifies a non-greedy qualifier. |
{n,m} | Braces, which matches the preceding character at least n times but not more than m times. |
(xyz) | Capturing group, which matches the character "xyz" in an exact order. |
| | Alternation, which matches the characters before or after the symbol. |
\ | Escape character, which can restore the original meaning of metacharacters and allows you to match reserved characters [ ] ( ) { } . * + ? ^ $ \\ | |
^ | Matches the beginning-of-line character. |
$ | Matches the end-of-line character. |
Period
The simplest example of metacharacters is the period
., which can match any single character but not a line break or newline character. For example, the regex .ar means: any character, followed by the letter a,
followed by the letter r.".ar" => The car parked in the garage.
Character Set
A character set is also known as a character class, which is specified by square brackets. A hyphen in a character set is used to specify the character range. The order of the character range inside square brackets does not matter.
For example, the regex
[Tt]he means: the uppercase letter T or the lowercase letter t, followed by the letter h, followed by the letter e."[Tt]he" => The car parked in the garage.
However, the period in character sets is what it means literally. For example, the regex
ar[.] means: the lowercase letter a, followed by the letter r, followed by the period ."ar[.]" => A garage is a good place to park a car.
Negated Character Set
Generally, the caret symbol
^ represents the start of a string, but when enclosed in square brackets, it negates the character set. For example, the regex [^c]ar means: any character except the letter c, followed by the character a,
followed by the letter r."[^c]ar" => The car parked in the garage.
Repetition
The metacharacters
+, *, and ? are used to specify how many times a subpattern can appear. These metacharacters act differently in different situations.Asterisk
The symbol
* matches zero or more repetitions of the preceding matcher. For example, the regex a* matches zero or more repetitions of the preceding lowercase letter a. However, if it appears after a character set, then it finds the repetitions of the whole character set.
For example, the regex [a-z]* means: any number of lowercase letters in a row."[a-z]*" => The car parked in the garage.
The symbol
*can be used together with the metacharacter . to match the arbitrary string .*. It can also be used together with the whitespace character \\s to match a string of whitespace characters.
For example, the regex \\s*cat\\s* means: zero or more whitespaces, followed by the lowercase letter c , followed by the lowercase letter a, followed by the lowercase character t, followed by zero or more whitespaces."\\s*cat\\s*" => The fat cat sat on the cat.
Plus Sign
The symbol
+ matches one or more repetitions of the preceding character. For example, the regex c.+t means: the lowercase letter c, followed by at least one character, followed by the lowercase letter t."c.+t" => The fat cat sat on the mat.
Question Mark
The metacharacter
? makes the preceding character optional and matches zero or one repetition of the preceding character.
For example, the regex [T]?he means: the optional uppercase character T, followed by the lowercase letter h, followed by the lowercase letter e."[T]he" => The car is parked in the garage.
"[T]?he" => The car is parked in the garage.
Braces
In regexes, braces, aka quantifiers, are used to specify how many times a character or a group of characters can be repeated. For example, the regex
[0-9]{2,3} means: match at least 2 digits but not more than 3 digits (characters in the range of 0 to 9)."[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
The second number can be left out. For example, the regex
[0-9]{2,} means: match 2 or more digits. If the comma is also removed, the regex [0-9]{2} means: match exactly 2 digits."[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
"[0-9]{2}" => The number was 9.9997 but we rounded it off to 10.0.
Capturing Group
A capturing group is a group of subpatterns enclosed in parentheses and is denoted as
(...). If a quantifier is placed after a character, it will repeat the preceding character.
However, if a quantifier is placed after a capturing group, it will repeat the whole capturing group.
For example, the regex (ab)* matches zero or more repetitions of the string "ab". The metacharacter | can be used in a capturing group. For example, the regex (c|g|p)ar means: the lowercase letter c, g, or p, followed by the letter a, followed by the letter r."(c|g|p)ar" => The car is parked in the garage.
Alternation
The vertical bar
| is used to define alternation that is like a condition between multiple expressions. Alternation seems to work in the same way as character set.
However, the great difference is that alternation can be used at the expression level, while character set at the character level.
For example, the regex (T|t)he|car means: the uppercase character T or the lowercase letter t, followed by h, followed by e or c, followed by a, followed by r."(T|t)he|car" => The car is parked in the garage.
Escape Character
The backslash
\\ is used to escape the next character, allowing you to specify a symbol as a matching character including reserved characters { } [ ] / \\ + * . $ ^ | ?. To use a special character as a matching character, prepend \\ before it.
For example, the regex . is used to match any character except a line break. To match the character . in the input string, the regex (f|c|m)at\\.? means: the lowercase letter f, c, or m, followed by the lowercase letter a, followed by the lowercase letter t, followed by the optional . character."(f|c|m)at\\.?" => The fat cat sat on the mat.
Anchors
Anchors in regexes are used to check whether the matching symbol is the starting or ending symbol of the input string.
There are two types of anchors:
^ (which checks whether the matching character is the start character of the input string) and $ (which checks whether the matching character is the end character).Caret
The caret
^ is used to check whether a matching character is the first character of the input string. If the regex ^a (if a is the starting symbol) is used to match the string abc, it matches a.
However, if the regex ^b is used, it does not match anything, because "b" in the string abc is not the start character.
The regex ^(T|t)he means that the uppercase character T or the lowercase letter t is the starting symbol of the input string, followed by the letter h, followed by the lowercase letter e."(T|t)he" => The car is parked in the garage.
"^(T|t)he" => The car is parked in the garage.
Dollar Sign
The dollar sign
$ is used to check whether a matching character is the last character of the input string. For example, the regex (at\\.)$ means: the lowercase letter a, followed by the lowercase letter t, followed by the character ., and the matcher must be the end of the string."(at\\.)" => The fat cat. sat. on the mat.
"(at\\.)$" => The fat cat sat on the mat.
Shorthand Character Sets
There are shorthands for commonly used character sets and regexes. The shorthand character sets are as follows:
Shorthand | Description |
. | Matches any character except a line break |
\\w | Matches alphanumeric characters: [a-zA-Z0-9_] |
\\W | Matches non-alphanumeric characters: [^\\w] |
\\d | Matches digits: [0-9] |
\\D | Matches non-digits: [^\\d] |
\\s | Matches whitespace character: [\\t\\n\\f\\r\\p{Z}] |
\\S | Matches non-whitespace character: [^\\s] |
Lookaround
Lookbehind and lookahead (also called lookaround) are specific types of non-capturing groups (used to match the pattern but not included in the matching list). Lookarounds are used when there is the condition that this pattern is preceded or followed by another certain pattern.
For example, to get all the numbers and the
. character that are preceded by the character $ in the input string $4.44 and $10.88, the regex (?<=\\$)[0-9\\.]* can be used.
Below are the lookarounds used in regexes:Symbol | Description |
?= | Positive lookahead |
?! | Negative lookahead |
?<= | Positive lookbehind |
?<! | Negative lookbehind |
Positive Lookahead
A positive lookahead asserts that the first part of the expression must be followed by the lookahead expression. The returned match only contains the text that is matched by the first part of the expression.
To define a positive lookahead, parentheses are used. Within those parentheses, a question mark with equal sign is denoted as
(?=...). The lookahead expression is written after the equal sign inside parentheses.
For example, the regex (T|t)he(?=\\sfat) means: the uppercase letter T or lowercase letter t, followed by the letter h, followed by the lowercase letter e or c.
In parentheses, the positive lookahead is defined, which tells the regex engine to match The or the which is followed by the word fat."(at\\.)$" => The fat cat sat on the mat.
Negative Lookahead
A negative lookahead is used to get the content that does not match the expression from the input string and is defined in the same way as positive lookahead.
The only difference lies in that a negative lookahead uses the negation symbol
! instead of the equal sign =, such as (?!...).
For example, the regex (T|t)he(?!\\sfat) means: get all the words The or the and add a whitespace character before the unmatched fat word from the input string."(T|t)he(?!\\sfat)" => The fat cat sat on the mat.
Positive Lookbehind
A positive lookbehind is used to get all the matches that are preceded by a specific pattern and is denoted as
(?<=...). For example, the regex (?<=(T|t)he\\s)(fat|mat) means: get all the words fat and mat after the word The or the from the input string."(?<=(T|t)he\\s)(fat|mat)" => The fat cat sat on the mat.
Negative Lookbehind
A negative lookbehind is used to get all the matches that are not preceded by a specific pattern and is denoted as
(?<!...). For example, the regex (?<!(T|t)he\\s)(cat) means: get all the cat words that are not after the word The or the from the input string."(?<!(T|t)he\\s)(cat)" => The cat sat on cat.
Flags
Flags are also called modifiers as they modify the output of regexes. They can be used in any order or combination and are an integral part of a regex.
Flag | Description |
i | Case-insensitive: Sets matching to be case-insensitive. |
g | Global search: Searches for all the matches throughout the input string. |
m | Multiline match: Matches every line of the input string. |
Case Insensitivity
The modifier
i is used to perform a case-insensitive match. For example, the regex /The/gi means: the uppercase letter T, followed by the lowercase letter h, followed by the lowercase letter e.
At the end of the regex, the flag i tells the regex to ignore the case. As can be seen, the flag g is also used so as to search for matches in the whole input string."The" => The fat cat sat on the mat.
"/The/gi" => The fat cat sat on the mat.
Global Search
The modifier
g is used to perform a global match (find all matches rather than stopping after the first match).
For example, the regex /.(at)/g means: any character except a line break, followed by the lowercase letter a, followed by the lowercase letter t.
As the flag g is used at the end of the regex, it will find all matches in the input string.".(at)" => The fat cat sat on the mat.
"/.(at)/g" => The fat cat sat on the mat.
Multiline
The modifier
m is used to perform multiline matching. As discussed earlier, anchors (^, $) are used to check whether the matched character is the beginning or end of the input string. To have anchors work on each line, the flag m should be used.
For example, the regex /at(.)?$/gm means: the lowercase letter a, followed by the lowercase letter t, and optionally zero or one repetition of any character except line break. Because the modifier m is at the end of the regex, the regex engine matches pattern at the end of each line in a string."/.at(.)?$/" => The fatcat saton the mat.
"/.at(.)?$/gm" => The fatcat saton the mat.
Common Regexes
Type | Expression |
Positive integer | ^-\\d+$ |
Negative integer | ^-\\d+$ |
Phone number | ^+?[\\d\\s]{3,}$ |
Phone code | ^+?[\\d\\s]+(?[\\d\\s]{10,}$ |
Integer | ^-?\\d+$ |
Username | ^[\\w\\d_.]{4,16}$ |
Alphanumeric character | ^[a-zA-Z0-9]*$ |
Alphanumeric character with whitespace | ^[a-zA-Z0-9 ]*$ |
Password | ^(?=^.{6,}$)((?=.*[A-Za-z0-9])(?=.*[A-Z])(?=.*[a-z]))^.*$ |
Email | ^([a-zA-Z0-9._%-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,4})*$ |
IPv4 address | ^((?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?))*$` |
Lowercase letters | ^([a-z])*$ |
Uppercase letter | ^([A-Z])*$ |
Username | ^[\\w\\d_.]{4,16}$ |
URL | ^(((http|https|ftp):\\/\\/)?([[a-zA-Z0-9]\\-\\.])+(\\.)([[a-zA-Z0-9]]){2,4}([[a-zA-Z0-9]\\/+=%&_\\.~?\\-]*))*$ |
Visa credit card number | ^(4[0-9]{12}(?:[0-9]{3})?)*$ |
Date (MM/DD/YYYY) | ^(0?[1-9]|1[012])[- /.](0?[1-9]|[12][0-9]|3[01])[- /.](19|20)?[0-9]{2}$ |
Date (YYYY/MM/DD) | ^(19|20)?[0-9]{2}[- /.](0?[1-9]|1[012])[- /.](0?[1-9]|[12][0-9]|3[01])$ |
Mastercard credit card number | ^(5[1-5][0-9]{14})*$ |
Help and Support
Was this page helpful?
You can also Contact sales or Submit a Ticket for help.
Help us improve! Rate your documentation experience in 5 mins.
Feedback