产品动态
公告
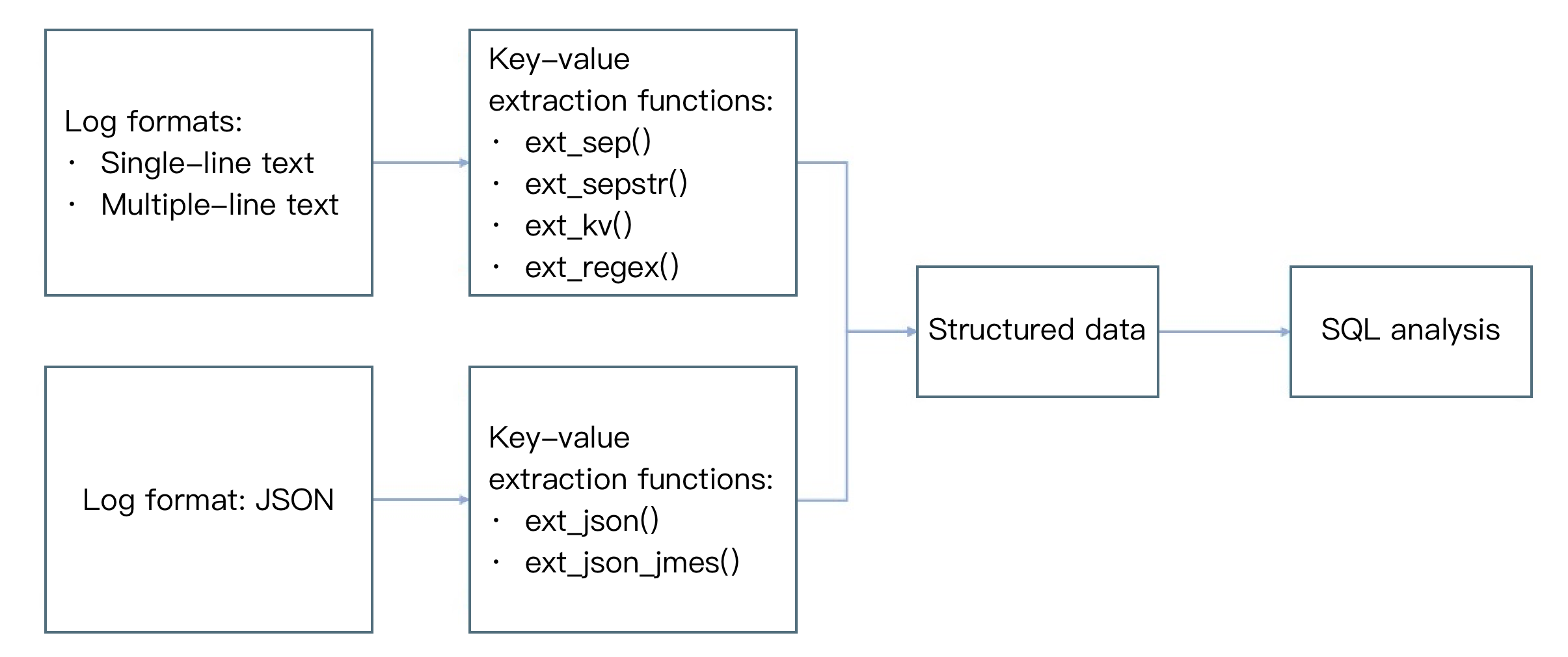
基于分隔符(单字符)提取字段值内容
ext_sep("源字段名", "目标字段1,目标字段2,目标字段...", sep="分隔符", quote="不参与分割的部分"", restrict=False, mode="overwrite")
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
field | 待提取的字段名 | string | 是 | - | 用户日志中已存在的字段名 |
output | 单个字段名或以英文半角逗号拼接的多个新字段名 | string | 是 | - | - |
sep | 分隔符 | string | 否 | , | 任意单字符 |
quote | 将值包括起来的字符 | string | 否 | - | - |
restrict | 默认为 False。当提取的值个数与用户输入的目标字段数不一致时: True:忽略,不进行任何提取处理 False:尽量匹配前几个字段 | bool | 否 | False | - |
mode | 新字段的写入模式。默认强制覆盖 | string | 否 | overwrite | - |
{"content": "hello Go,hello Java,hello python"}
//使用逗号作为分割符号,将content字段值分割为三段,分别对应f1,f2,f3三个字段。ext_sep("content", "f1, f2, f3", sep=",", quote="", restrict=False, mode="overwrite")//丢弃content字段fields_drop("content")
{"f1":"hello Go","f2":"hello Java","f3":"hello python"}
{"content": " Go,%hello ,Java%,python"}
ext_sep("content", "f1, f2", quote="%", restrict=False)
//%hello ,Java%虽然也有逗号,但它作为一个整体,就不参与分隔符提取。{"content":" Go,%hello ,Java%,python","f1":" Go","f2":"hello ,Java"}
restrict=True, 表示当分割的值的个数和目标字段不同时,函数不执行。原始日志:{"content": "1,2,3"}
ext_sep("content", "f1, f2", restrict=True)
{"content":"1,2,3"}
ext_sepstr("源字段名","目标字段1,目标字段2,目标字段...", sep="abc", restrict=False, mode="overwrite")
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
field | 待提取的字段名 | string | 是 | - | 用户日志中已存在的字段名 |
output | 单个字段名或以英文半角逗号拼接的多个新字段名 | string | 是 | - | - |
sep | 分隔字符(串) | string | 否 | , | - |
restrict | 默认为False。当提取的值个数与用户输入的目标字段数不一致时: True:忽略,不进行任何提取处理。 False:尽量匹配前几个字段 | bool | 否 | False | - |
mode | 新字段的写入模式。默认强制覆盖 | string | 否 | overwrite | - |
{"message":"1##2##3"}
//使用“##”作为分割符,提取键值。ext_sepstr("message", "f1,f2,f3,f4", sep="##")
//当目标字段的个数超出了分隔出的值,超出的字段返回"".{"f1":"1","f2":"2","message":"1##2##3","f3":"3","f4":""}
ext_json("源字段名",prefix="",suffix="",format="full",exclude_node="不平铺的JSON节点")
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
field | 待提取的字段名 | string | 是 | - | - |
prefix | 新字段前缀 | string | 否 | - | - |
suffix | 新字段后缀 | string | 否 | - | - |
format | full:字段名格式为全路径(parent + sep + prefix + key + suffix) simple:非全路径(prefix + key + suffix) | string | 否 | simple | - |
sep | 拼接符,用来拼接节点名使用 | string | 否 | # | - |
depth | 最大展开层级深度,超过此层级的节点不再展开 | number | 否 | 100 | 1-500 |
expand_array | 数组节点是否展开 | bool | 否 | False | - |
include_node | 基于正则匹配节点名称的白名单 | string | 否 | - | - |
exclude_node | 基于正则匹配节点名称的黑名单 | string | 否 | - | - |
include_path | 基于正则匹配节点路径的白名单 | string | 否 | - | - |
exclude_path | 基于正则匹配节点路径的黑名单 | string | 否 | - | - |
retain | 保留某些特殊字符不做转义,例如:\\n、\\t | string | 否 | - | - |
escape | 是否需要对数据进行转义,默认值 True,有特殊字符时不能转义 | bool | 否 | True | - |
{"data": "{ \\"k1\\": 100, \\"k2\\": { \\"k3\\": 200, \\"k4\\": { \\"k5\\": 300}}}"}
ext_json("data")
{"data":"{ \\"k1\\": 100, \\"k2\\": { \\"k3\\": 200, \\"k4\\": { \\"k5\\": 300}}}","k1":"100","k3":"200","k5":"300"}
{"content": "{\\"sub_field1\\":1,\\"sub_field2\\":\\"2\\"}"}
//exclude_node=subfield1意思就是这个节点不提取ext_json("content", format="full", exclude_node="sub_field1")
{"sub_field2":"2","content":"{\\"sub_field1\\":1,\\"sub_field2\\":\\"2\\"}"}
{"content": "{\\"sub_field1\\":{\\"sub_sub_field3\\":1},\\"sub_field2\\":\\"2\\"}"}
//sub_field2被提取出来时,自动加上前缀udf\\_,成为udf\\_\\_sub\\_field2ext_json("content", prefix="udf_", format="simple")
{"content":"{\\"sub_field1\\":{\\"sub_sub_field3\\":1},\\"sub_field2\\":\\"2\\"}","udf_sub_field2":"2","udf_sub_sub_field3":"1"}
//format=full表示提取的字段名自带层级关系,sub_field2被提取出来时,自动加上它的父节点名称,成为#content#__sub_field2ext_json("content", prefix="__", format="full")
{"#content#__sub_field2":"2","#content#sub_field1#__sub_sub_field3":"1","content":"{\\"sub_field1\\":{\\"sub_sub_field3\\":1},\\"sub_field2\\":\\"2\\"}"}
{"content": "{\\"sub_field1\\":1,\\"sub_field2\\":\\"\\\\n2\\"}"}
ext_json("content",retain="\\n")
{"sub_field2":"\\\\n2","content":"{\\"sub_field1\\":1,\\"sub_field2\\":\\"\\\\n2\\"}","sub_field1":"1"}
{"content": "{\\"sub_field1\\":1,\\"sub_field2\\":\\"\\\\n2\\\\t\\"}"}
ext_json("content",retain="\\n,\\t")
{"sub_field2":"\\\\n2\\\\t","content":"{\\"sub_field1\\":1,\\"sub_field2\\":\\"\\\\n2\\\\t\\"}","sub_field1":"1"}
{"message":"{\\"ip\\":\\"183.6.104.157\\",\\"params\\":\\"[{\\\\\\"tokenType\\\\\\":\\\\\\"RESERVED30\\\\\\",\\\\\\"otherTokenInfo\\\\\\":{\\\\\\"unionId\\\\\\":\\\\\\"123\\\\\\"},\\\\\\"unionId\\\\\\":\\\\\\"adv\\\\\\"}]\\"}"}
ext_json("message", escape=False)fields_drop("message")
{"ip":"183.6.104.157", "params":"[{\\"tokenType\\":\\"RESERVED30\\",\\"otherTokenInfo\\":{\\"unionId\\":\\"123\\"},\\"unionId\\":\\"adv\\"}]"}
ext_json_jmes(“源字段名”, jmes= "提取JSON的公示", output="目标字段", ignore_null=True, mode="overwrite")
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
field | 待提取的字段名 | string | 是 | - | - |
jmes | jmes 表达式,请参考 JMESPath | string | 是 | - | - |
output | 输出字段名,仅支持单个字段 | string | 是 | - | - |
ignore_null | 是否忽略节点值为 null 的节点,默认 True,忽略 null 字段值,否则当提取结果为 null 时,将输出空字符串 | bool | 否 | True | - |
mode | 新字段的写入模式。默认强制覆盖 | string | 否 | overwrite | - |
{"content": "{\\"a\\":{\\"b\\":{\\"c\\":{\\"d\\":\\"value\\"}}}}"}
//jmes="a.b.c.d"的意思是取a.b.c.d的值。ext_json_jmes("content", jmes="a.b.c.d", output="target")
{"content":"{\\"a\\":{\\"b\\":{\\"c\\":{\\"d\\":\\"value\\"}}}}","target":"value"}
{"content": "{\\"a\\":{\\"b\\":{\\"c\\":{\\"d\\":\\"value\\"}}}}"}
//jmes="a.b.c.d"的意思是取a.b.c的值。ext_json_jmes("content", jmes="a.b.c", output="target")
{"content":"{\\"a\\":{\\"b\\":{\\"c\\":{\\"d\\":\\"value\\"}}}}","target":"{\\"d\\":\\"value\\"}"}
ext_regex(“源字段名”, regex="正则表达式", output=“目标字段1,目标字段2,目标字段.......”, mode="overwrite")
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
field | 待提取的字段名 | string | 是 | - | - |
regex | regex 表达式,如果包含了特殊字符,用户输入时需要进行转义,否则提示语法错误 | string | 是 | - | - |
output | 单个字段名或以英文半角逗号拼接的多个新字段名 | string | 否 | - | - |
mode | 新字段的写入模式。默认强制覆盖 | string | 否 | overwrite | - |
{"content": "1234abcd5678"}
ext_regex("content", regex="\\d+", output="target1,target2")
{"target2":"5678","content":"1234abcd5678","target1":"1234"}
{"content": "1234abcd"}
ext_regex("content", regex="(?<target1>\\d+)(.*)", output="target2")
{"target2":"abcd","content":"1234abcd","target1":"1234"}
ext_kv("源字段名", pair_sep=r"\\s", kv_sep="=", prefix="", suffix="", mode="fill-auto")
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
field | 待提取的字段名 | string | 是 | - | - |
pair_sep | 一级分隔符,分割多个键值对 | string | 是 | - | - |
kv_sep | 二级分隔符,分割键和值 | string | 是 | - | - |
prefix | 新字段前缀 | string | 否 | - | - |
suffix | 新字段后缀 | string | 否 | - | - |
mode | 新字段的写入模式。默认强制覆盖 | string | 否 | - | - |
{"content": "a=1|b=2|c=3"}
ext_kv("content", pair_sep="|", kv_sep="=")
{"a":"1","b":"2","c":"3","content":"a=1|b=2|c=3"}
ext_first_notnull(值1, 值2, ...)
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
可变参列表 | 参与计算的参数或表达式 | string | 是 | - | - |
{"data1": null, "data2": "", "data3": "first not null"}
fields_set("result", ext_first_notnull(v("data1"), v("data2"), v("data3")))
{"result":"first not null","data3":"first not null","data2":"","data1":"null"}
ext_grok(字段值, grok="", extend="")
参数名称 | 参数描述 | 参数类型 | 是否必须 | 参数默认值 | 参数取值范围 |
field | 字段值 | string | 是 | - | - |
grok | 表达式 | string | 是 | - | - |
extend | 用户自定义的 GROK 表达式 | string | 是 | - | - |
{"content":"2019 June 24 \\"I am iron man\\""}
ext_grok("content", grok="%{YEAR:year} %{MONTH:month} %{MONTHDAY:day} %{QUOTEDSTRING:motto}")fields_drop("content")
{"day":"24", "month":"June", "motto":"I am iron man", "year":"2019"}
{"content":"Beijing-1104,Beijing-Beijing"}
ext_grok("content", grok="%{ID1:user_id1},%{ID2:user_id2}",extend="ID1=%{WORD}-%{INT},ID2=%{WORD}-%{WORD}")fields_drop("content")
{"user_id1":"Beijing-1104", "user_id2":"Beijing-Beijing"}
文档反馈