- Release Notes and Announcements
- Product Introduction
- Purchase Guide
- Getting Started
- EMR on CVM Operation Guide
- Planning Cluster
- Configuring Cluster
- Managing Cluster
- Instance Information
- Node Specification Management
- Checking and Updating Public IP
- Cluster Scale-Out
- Cluster Scale-in
- Auto Scaling
- Repairing Disks
- Graceful Scale-In
- Disk Update Check
- Scaling up Cloud Disks
- Changing Configurations
- Automatic Replacement
- Exporting Software Configuration
- Cluster Scripts
- Cluster Termination
- Operation Logs
- Task Center
- Managing Service
- Managing Users
- Adding Components
- Restarting Service
- Starting/Stopping Services
- WebUI Access
- Resetting WebUI Password
- Software WebUI Entry
- Operation Guide for Access to WebUI over Private Network
- Role Management
- Client Management
- Configuration Management
- YARN Resource Scheduling
- HBase RIT Fixing
- Component Port Information
- Service Operation
- HBase Table-Level Monitoring
- Component Health Status
- Monitoring and Alarms
- Cluster Overview
- Node Status
- Service Status
- Cluster Event
- Log
- Application Analysis
- Cluster Inspection
- Monitoring Metrics
- Node Monitoring Metrics
- HDFS Monitoring Metrics
- YARN Monitoring Metrics
- ZooKeeper Monitoring Metrics
- HBase Monitoring Metrics
- Hive Monitoring Metrics
- Spark Monitoring Metrics
- Presto Monitoring Metrics
- Trino Monitoring Metrics
- ClickHouse Monitoring Metrics
- Druid Monitoring Metrics
- Kudu Monitoring Metrics
- Alluxio Monitoring Metrics
- PrestoSQL Monitoring Metrics
- Impala Monitoring Metrics
- Ranger Monitoring Metrics
- COSRanger Monitoring Metrics
- Doris Monitoring Metrics
- Kylin Monitoring Metrics
- Zeppelin Monitoring Metrics
- Oozie Monitoring Metrics
- Storm Monitoring Metrics
- Livy Monitoring Metrics
- Kyuubi Monitoring Metrics
- StarRocks Monitoring Metrics
- Kafka Monitoring Metrics
- Alarm Configurations
- Alarm Records
- Container-Based EMR
- EMR Development Guide
- Hadoop Development Guide
- HDFS Common Operations
- HDFS Federation Management Development Guide
- HDFS Federation Management
- Submitting MapReduce Tasks
- Automatically Adding Task Nodes Without Assigning ApplicationMasters
- YARN Task Queue Management
- Practices on YARN Label Scheduling
- Hadoop Best Practices
- Using API to Analyze Data in HDFS and COS
- Dumping YARN Job Logs to COS
- Spark Development Guide
- Hbase Development Guide
- Phoenix on Hbase Development Guide
- Hive Development Guide
- Presto Development Guide
- Sqoop Development Guide
- Hue Development Guide
- Oozie Development Guide
- Flume Development Guide
- Kerberos Development Guide
- Knox Development Guide
- Alluxio Development Guide
- Kylin Development Guide
- Livy Development Guide
- Kyuubi Development Guide
- Zeppelin Development Guide
- Hudi Development Guide
- Superset Development Guide
- Impala Development Guide
- ClickHouse Development Guide
- Druid Development Guide
- TensorFlow Development Guide
- Jupyter Development Guide
- Kudu Development Guide
- Ranger Development Guide
- Doris Development Guide
- Kafka Development Guide
- Iceberg Development Guide
- StarRocks Development Guide
- Flink Development Guide
- RSS Development Guide
- Hadoop Development Guide
- Best Practices
- API Documentation
- FAQs
- Service Level Agreement
- Contact Us
- Release Notes and Announcements
- Product Introduction
- Purchase Guide
- Getting Started
- EMR on CVM Operation Guide
- Planning Cluster
- Configuring Cluster
- Managing Cluster
- Instance Information
- Node Specification Management
- Checking and Updating Public IP
- Cluster Scale-Out
- Cluster Scale-in
- Auto Scaling
- Repairing Disks
- Graceful Scale-In
- Disk Update Check
- Scaling up Cloud Disks
- Changing Configurations
- Automatic Replacement
- Exporting Software Configuration
- Cluster Scripts
- Cluster Termination
- Operation Logs
- Task Center
- Managing Service
- Managing Users
- Adding Components
- Restarting Service
- Starting/Stopping Services
- WebUI Access
- Resetting WebUI Password
- Software WebUI Entry
- Operation Guide for Access to WebUI over Private Network
- Role Management
- Client Management
- Configuration Management
- YARN Resource Scheduling
- HBase RIT Fixing
- Component Port Information
- Service Operation
- HBase Table-Level Monitoring
- Component Health Status
- Monitoring and Alarms
- Cluster Overview
- Node Status
- Service Status
- Cluster Event
- Log
- Application Analysis
- Cluster Inspection
- Monitoring Metrics
- Node Monitoring Metrics
- HDFS Monitoring Metrics
- YARN Monitoring Metrics
- ZooKeeper Monitoring Metrics
- HBase Monitoring Metrics
- Hive Monitoring Metrics
- Spark Monitoring Metrics
- Presto Monitoring Metrics
- Trino Monitoring Metrics
- ClickHouse Monitoring Metrics
- Druid Monitoring Metrics
- Kudu Monitoring Metrics
- Alluxio Monitoring Metrics
- PrestoSQL Monitoring Metrics
- Impala Monitoring Metrics
- Ranger Monitoring Metrics
- COSRanger Monitoring Metrics
- Doris Monitoring Metrics
- Kylin Monitoring Metrics
- Zeppelin Monitoring Metrics
- Oozie Monitoring Metrics
- Storm Monitoring Metrics
- Livy Monitoring Metrics
- Kyuubi Monitoring Metrics
- StarRocks Monitoring Metrics
- Kafka Monitoring Metrics
- Alarm Configurations
- Alarm Records
- Container-Based EMR
- EMR Development Guide
- Hadoop Development Guide
- HDFS Common Operations
- HDFS Federation Management Development Guide
- HDFS Federation Management
- Submitting MapReduce Tasks
- Automatically Adding Task Nodes Without Assigning ApplicationMasters
- YARN Task Queue Management
- Practices on YARN Label Scheduling
- Hadoop Best Practices
- Using API to Analyze Data in HDFS and COS
- Dumping YARN Job Logs to COS
- Spark Development Guide
- Hbase Development Guide
- Phoenix on Hbase Development Guide
- Hive Development Guide
- Presto Development Guide
- Sqoop Development Guide
- Hue Development Guide
- Oozie Development Guide
- Flume Development Guide
- Kerberos Development Guide
- Knox Development Guide
- Alluxio Development Guide
- Kylin Development Guide
- Livy Development Guide
- Kyuubi Development Guide
- Zeppelin Development Guide
- Hudi Development Guide
- Superset Development Guide
- Impala Development Guide
- ClickHouse Development Guide
- Druid Development Guide
- TensorFlow Development Guide
- Jupyter Development Guide
- Kudu Development Guide
- Ranger Development Guide
- Doris Development Guide
- Kafka Development Guide
- Iceberg Development Guide
- StarRocks Development Guide
- Flink Development Guide
- RSS Development Guide
- Hadoop Development Guide
- Best Practices
- API Documentation
- FAQs
- Service Level Agreement
- Contact Us
Practices on Dynamic Scheduling of Spark Resources
Last updated: 2021-10-08 11:23:06
Preparations for Development
Confirm that you have activated Tencent Cloud and created an EMR cluster. When creating the EMR cluster, you need to select the spark_hadoop component on the software configuration page.
Spark is installed in the /usr/local/service/ path (/usr/local/service/spark) in the CVM instance for the EMR cluster.
Copying JAR Package
You need to copy spark-<version>-yarn-shuffle.jar to the /usr/local/service/hadoop/share/hadoop/yarn/lib directory of all nodes in the cluster.
Method 1. Use the SSH Console
- In Cluster Service > YARN, select Operation > Role Management and confirm the IP of the node where NodeManager resides.
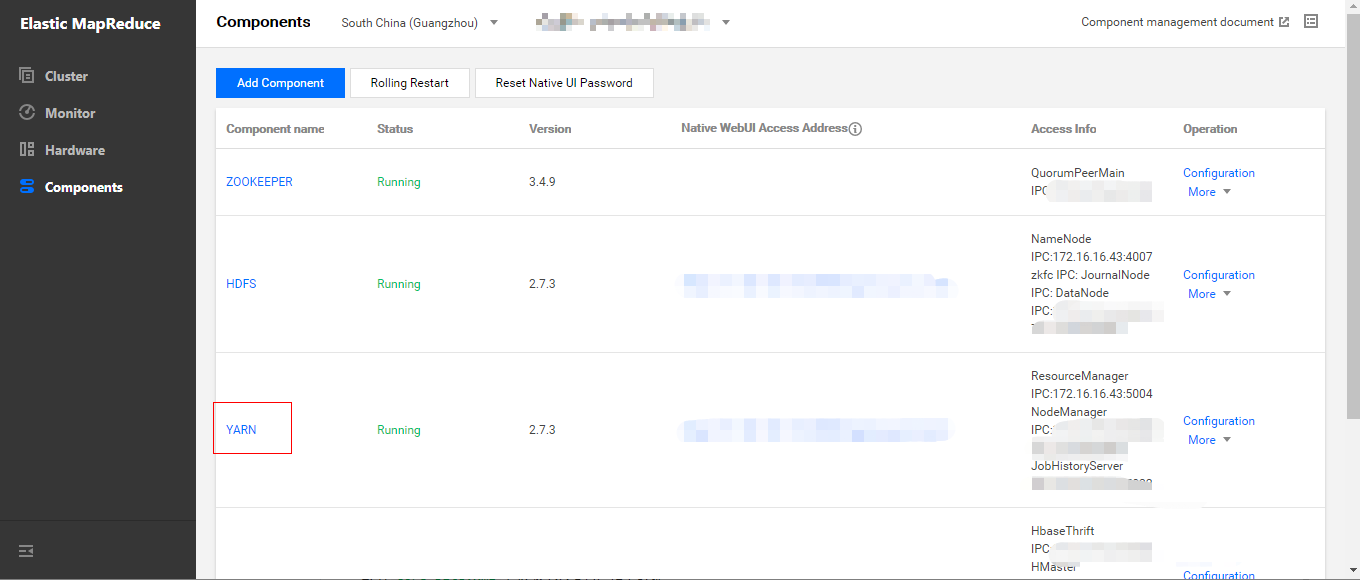
- Log in to the nodes where NodeManager resides one by one.
- You need to log in to any node (preferably a master one) in the EMR cluster. For more information on how to log in to EMR, please see Logging in to Linux Instance. Here, you can log in by using XShell.
- Use SSH to log in to other nodes where NodeManager resides. The used command is
ssh $user@$ip, where$useris the login username, and$ipis the remote server IP (i.e., IP address confirmed in step 1).
- Verify that the switch is successful.
- Search for the path of the
spark-<version>-yarn-shuffle.jarfile.
- Copy
spark-<version>-yarn-shuffle.jarto/usr/local/service/hadoop/share/hadoop/yarn/lib.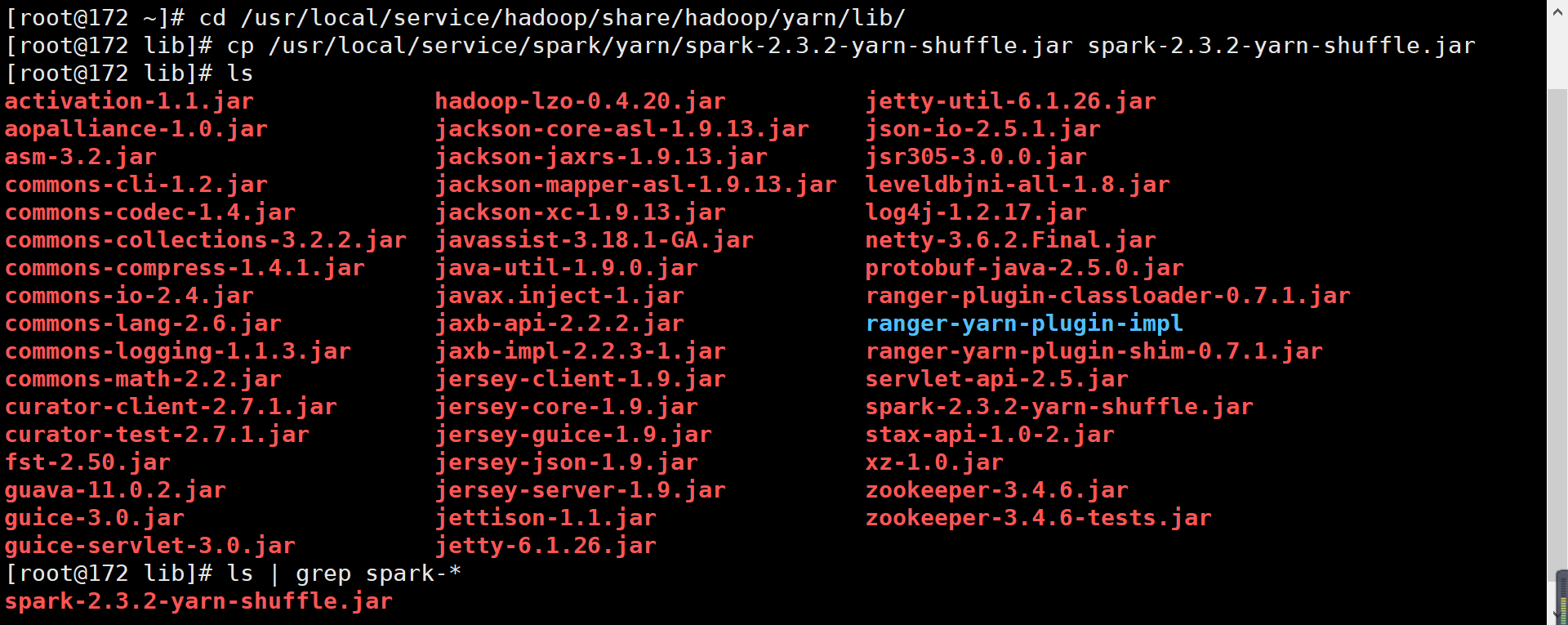
- Log out and switch to other nodes.

Method 2. Use batch deployment script
You need to log in to any node (preferably a master one) in the EMR cluster. For more information on how to log in to EMR, please see Logging in to Linux Instance. Here, you can log in by using XShell.
Write the following Shell script for batch file transfer. When there are many nodes in a cluster, to avoid entering the password for multiple times, you can use sshpass for file transfer. sshpass provides password-free transfer to eliminate your need to enter the password repeatedly; however, the password plaintext is prone to disclosure and can be found with the history command.
- Install sshpass for password-free transfer.
[root@172 ~]# yum install sshpass#!/bin/bash nodes=(ip1 ip2 … ipn) # List of IPs of all nodes in the cluster separated by spaces len=${#nodes[@]} password=<your password> file=" spark-2.3.2-yarn-shuffle.jar " source_dir="/usr/local/service/spark/yarn" target_dir="/usr/local/service/hadoop/share/hadoop/yarn/lib" echo $len for node in ${nodes[*]} do echo $node; sshpass -p $password scp "$source_dir/$file"root@$node:"$target_dir"; done - Transfer files in a non-password-free manner.
Write the following script:#!/bin/bash nodes=(ip1 ip2 … ipn) # List of IPs of all nodes in the cluster separated by spaces len=${#nodes[@]} password=<your password> file=" spark-2.3.2-yarn-shuffle.jar " source_dir="/usr/local/service/spark/yarn" target_dir="/usr/local/service/hadoop/share/hadoop/yarn/lib" echo $len for node in ${nodes[*]} do echo $node; scp "$source_dir/$file" root@$node:"$target_dir"; done
Modifying YARN Configuration
- In Cluster Service > YARN, select Operation > Configuration Management. Select the configuration file
yarn-site.xmland select "cluster level" as the level (modifications of configuration items at the cluster level will be applied to all nodes in the cluster).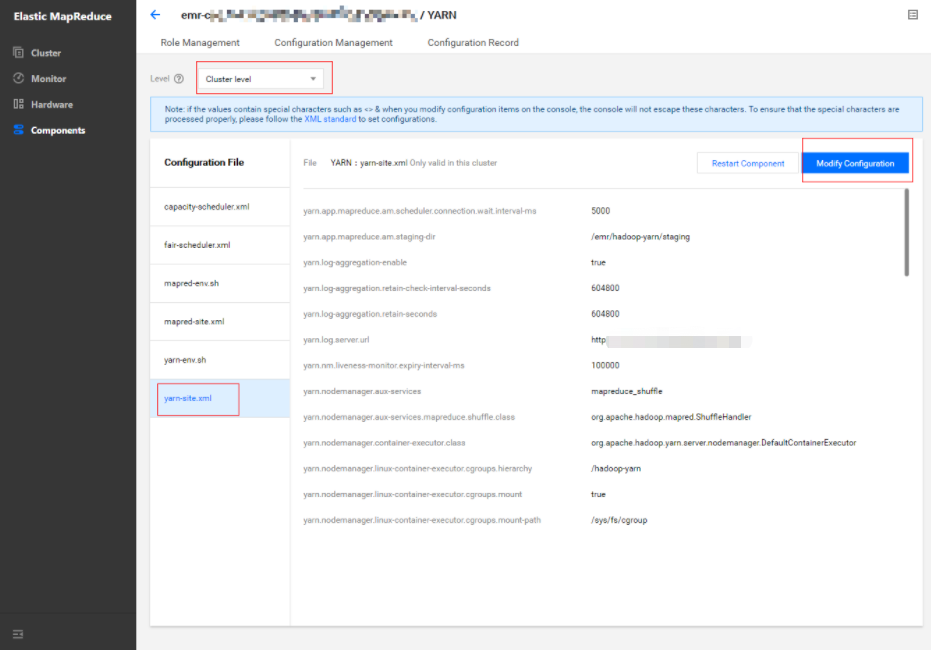
- Modify the
yarn.nodemanager.aux-servicesconfiguration item and addspark_shuffle.
- Add the configuration item
yarn.nodemanager.aux-services.spark_shuffle.classand set it toorg.apache.spark.network.yarn.YarnShuffleService.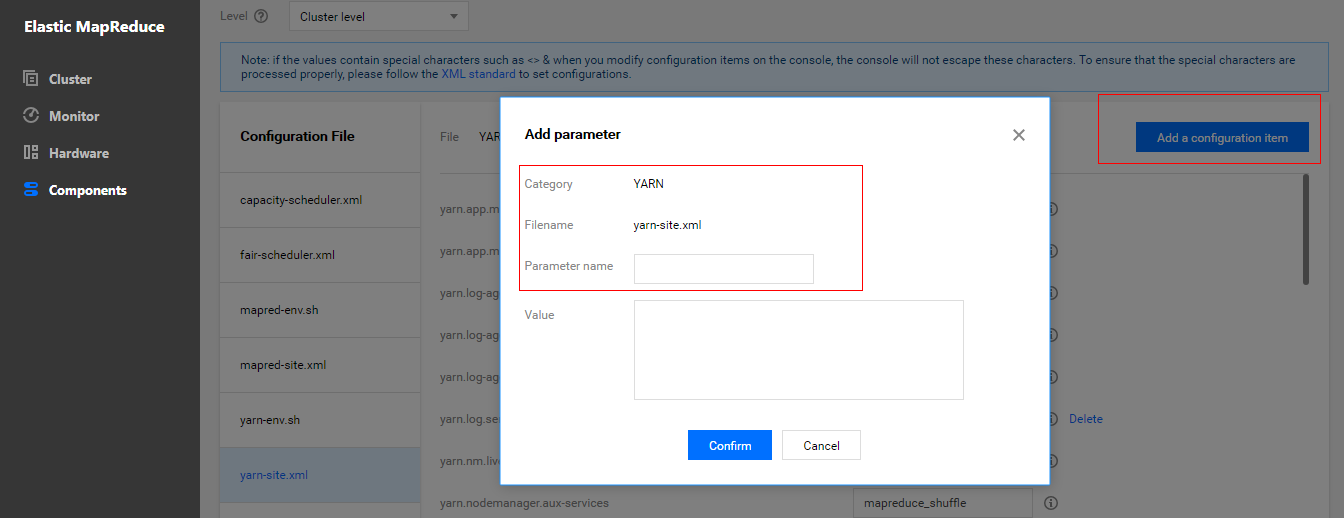
- Add the configuration item
spark.yarn.shuffle.stopOnFailureand set it tofalse.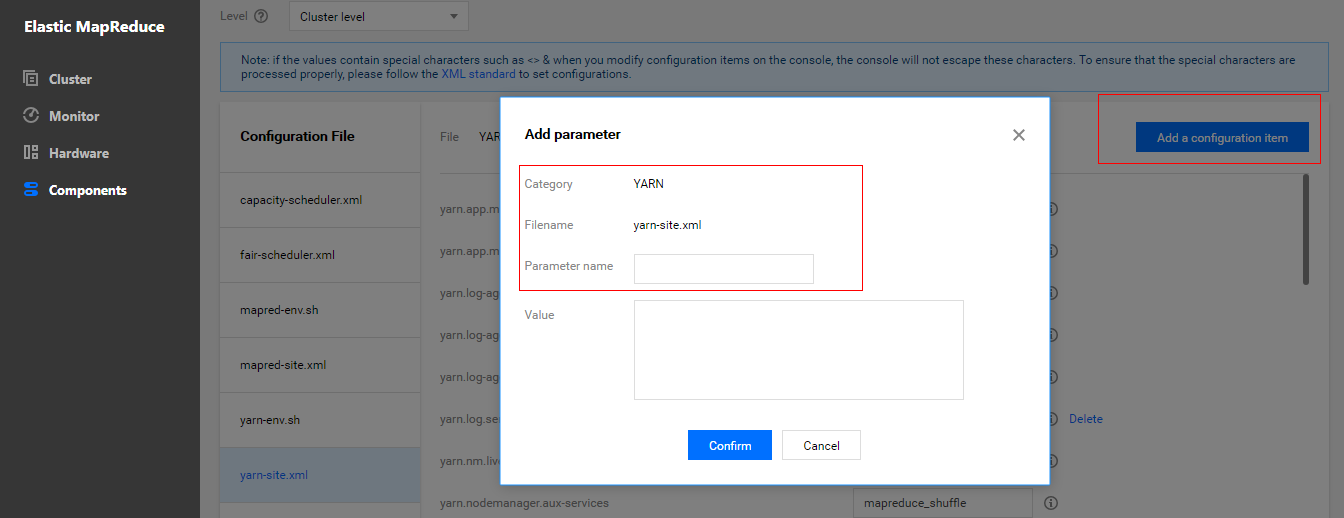
- Save and distribute the settings. Restart the YARN component for the configuration to take effect.
Modifying Spark Configuration
In Cluster Service > SPARK, select Operation > Configuration Management.
Select the configuration file spark-defaults.conf, click Modify Configuration, and create configuration items as shown below:
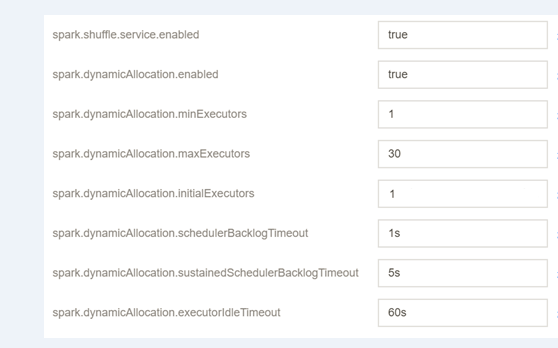
Configuration Item Value Remarks spark.shuffle.service.enabled true It starts the shuffle service. spark.dynamicAllocation.enabled true It starts dynamic resource allocation. spark.dynamicAllocation.minExecutors 1 It specifies the minimum number of executors allocated for each application. spark.dynamicAllocation.maxExecutors 30 It specifies the maximum number of executors allocated for each application. spark.dynamicAllocation.initialExecutors 1 Generally, its value is the same as that of `spark.dynamicAllocation.minExecutors`. spark.dynamicAllocation.schedulerBacklogTimeout 1s If there are pending jobs backlogged for more than this duration, new executors will be requested. spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s If the queue of pending jobs still exists, it will be triggered again once every several seconds. The number of executors requested per round grows exponentially compared to the previous round. spark.dynamicAllocation.executorIdleTimeout 60s If an executor has been idle for more than this duration, it will be deleted by the application. Save and distribute the configuration and restart the component.
Testing Dynamic Scheduling of Spark Resources
1. Resource configuration description of the testing environment
In the testing environment, there are two nodes where NodeManager is deployed, and each node has a 4 CPU cores and 8 GB memory. The total resources of the cluster are 8 CPU cores and 16 GB memory.
2. Testing job description
Test 1
- In the EMR Console, enter the
/usr/local/service/sparkdirectory, switch to the "hadoop" user, and runspark-submitto submit a job. The data needs to be stored in HDFS.[root@172 ~]# cd /usr/local/service/spark/ [root@172 spark]# su hadoop [hadoop@172 spark]$ hadoop fs -put ./README.md / [hadoop@172 spark]$ spark-submit --class org.apache.spark.examples.JavaWordCount --master yarn-client --num-executors 10 --driver-memory 4g --executor-memory 4g --executor-cores 2 ./examples/jars/spark-examples_2.11-2.3.2.jar /README.md /output - In the "Application" panel of the WebUI of the YARN component, you can view the container and CPU allocation before and after the configuration.

- Before dynamic resource scheduling is configured, at most 3 CPUs can be allocated.

- After dynamic resource scheduling is configured, up to 5 CPUs can be allocated.
Conclusion: after dynamic resource scheduling is configured, the scheduler will allocate more resources based on the real-time needs of applications.
Test 2
- In the EMR Console, enter the
/usr/local/service/sparkdirectory, switch to the "hadoop" user, and runspark-sqlto start the interactive SparkSQL Console, which is set to use most of the resources in the testing cluster. Configure dynamic resource scheduling and check resource allocation before and after the configuration.[root@172 ~]# cd /usr/local/service/spark/ [root@172 spark]# su hadoop [hadoop@172 spark]$ spark-sql --master yarn-client --num-executors 5 --driver-memory 4g --executor-memory 2g --executor-cores 1 - Use the example for calculating the pi that comes with Spark 2.3.0 as the testing job. When submitting the job, set the number of executors to 5, the driver memory to 4 GB, the executor memory to 4 GB, and the number of executor cores to 2.
[root@172 ~]# cd /usr/local/service/spark/ [root@172 spark]# su hadoop [hadoop@172 spark]$ spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --num-executors 5 --driver-memory 4g --executor-memory 4g --executor-cores 2 examples/jars/spark-examples_2.11-2.3.2.jar 500
- The resource utilization when only the SparkSQL job is running is 90.3%.

- After the SparkPi job is submitted, the resource utilization of SparkSQL becomes 27.8%.
Conclusion: although the SparkSQL job applies for a large amount of resources during submission, no analysis jobs are executed; therefore, there are a lot of idle resources actually. When the idle duration exceeds the limit set by spark.dynamicAllocation.executorIdleTimeout, idle executors will be released, and other jobs will get resources. In this test, the cluster resource utilization of the SparkSQL job decreases from 90% to 28%, and idle resources are allocated to the pi calculation job; therefore, automatic scheduling is effective.
Note:The value of the configuration item
spark.dynamicAllocation.executorIdleTimeoutaffects the speed of dynamic resource scheduling. In the test, it is found that the resource scheduling duration is basically the same as this value. You are recommended to adjust this value based on your actual needs for optimal performance.

 Yes
Yes
 No
No
Was this page helpful?