Zeppelin 简介
Download
聚焦模式
字号
Apache Zeppelin 是一款基于 Web 的 Notebook 产品,能够交互式数据分析。使用 Zeppelin,您可以使用丰富的预构建语言后端(或解释器)制作交互式的协作文档,例如 Scala(Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、Shell 等。
说明
EMR-V3.3.0及以上、EMR-V2.6.0及以上,已默认配置了 flink、hbase、kylin、livy、spark 的 Interpreter,其他版本和组件可参考 官方文档 根据 Zeppelin 版本进行配置。
前提条件
已创建集群,并选择 Zeppelin 服务,详情参见 创建 EMR 集群。
在集群的 EMR 安全组中,开启22、30002和18000端口(新建集群默认开启22和30002)及必要的内网通信网段,新安全组以 emr-xxxxxxxx_yyyyMMdd 命名,请勿手动修改安全组名称。
按需添加所需服务,如,Spark、Flink、HBase、Kylin。
登录 Zeppelin
1. 创建集群,选择 Zeppelin 服务,详情参见 创建 EMR 集群。
2. 在 EMR 控制台 左侧的导航栏,选择集群服务。
3. 单击 Zeppelin 所在的卡片,单击 Web UI 地址,访问 Web UI 页面。
4. 在 EMR-V2.5.0 及以前版本、EMR-V3.2.1 及以前版本,设置了默认登录权限,用户名密码为 admin:admin。如需更改密码,可修改配置文件/usr/local/service/zeppelin-0.8.2/conf/shiro.ini 中的 users 和 roles 选项。更多配置说明,可参见 文档。
5. 在 EMR-V2.6.0 及以后版本、 EMR-V3.3.0 及以后版本,Zeppelin 登录已集成 OpenLDAP 账户,只能用 Openldap 账户密码登录,新建集群后 Openldap 默认账户是 root 和 hadoop,默认密码是集群密码,且只有 root 账户拥有 Zeppelin 管理员权限,有权访问解析器配置页面。
使用 spark 功能完成 wordcount
1. 单击页面左侧 Create new note,在弹出页面中创建 notebook。
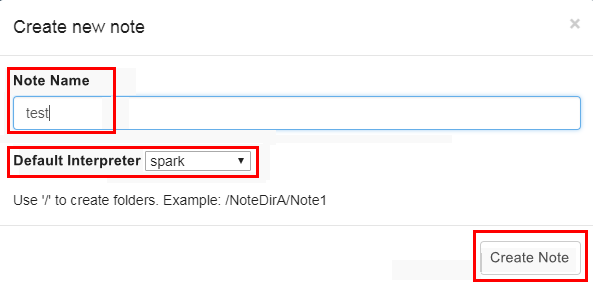
2. 2.EMR-V3.3.0 及以上、EMR-V2.6.0 及以上,已默认配置 Spark 对接 EMR 的集群(Spark On Yarn)。
如果您的版本是 EMR-V3.1.0、EMR-V2.5.0、EMR-V2.3.0,请参考 文档 进行 Spark 解释器配置。
如果您的版本是 EMR-V3.2.1,请参考 文档 进行 Spark 解释器配置。
3. 进入自己的 notebook。
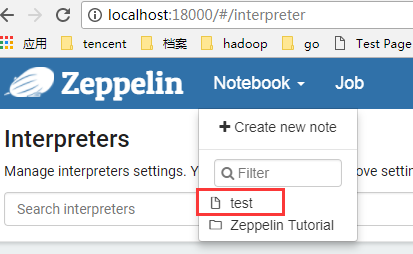
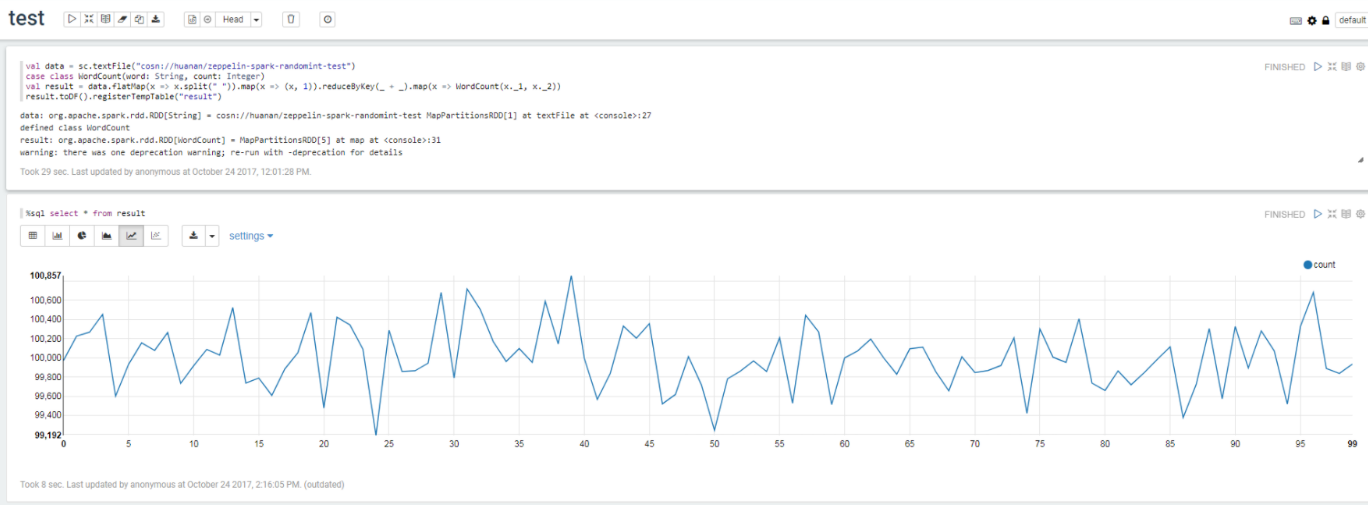
4. 编写 wordcount 程序,并运行如下命令:
val data = sc.textFile("cosn://huanan/zeppelin-spark-randomint-test")case class WordCount(word: String, count: Integer)val result = data.flatMap(x => x.split(" ")).map(x => (x, 1)).reduceByKey(_ + _).map(x => WordCount(x._1, x._2))result.toDF().registerTempTable("result")%sql select * from result
文档反馈