Spark on YARN uses YARN as the resource scheduler. Since Hadoop 2.7.2, YARN provides label-based scheduling on top of Capacity Scheduler.
Capacity Scheduler is a multi-tenant resource scheduler. It enables organizations in a Hadoop cluster to share available resources and provide computing power to the cluster based on their respective computing needs. Capacity Scheduler supports features such as hierarchical queue, capacity guarantee, security, resource elasticity, multi-tenancy, resource-based scheduling, and mapping. All resources of a cluster are allocated to queues, so that all applications submitted to a queue can use the resources allocated to the queue. Idle resources of organizations can be non-preemptively allocated to applications in queues running below the capacity. This ensures that an application runs with the minimum resource capacity while idle resources are elastically allocated to other applications as needed.
Capacity Scheduler roughly allocates cluster resources to queues, without specifying the location of applications in queues. Label-based scheduling is provided to allocate resources at a more refined granularity by assigning a node label to each node of the cluster, so that the location of applications can be specified. Node labels have the following characteristics:
1. A node has only one node label, which means that a node belongs to only one partition. A cluster is divided into multiple disjoint subclusters by node partition.
2. Node partitions are classified into exclusive and non-exclusive partitions based on their matching strategies. An exclusive node partition allocates containers only to nodes that exactly match the partition. A non-exclusive node partition shares idle resources to containers that request the default partition.
3. You can set accessible node labels for each queue to specify the node partitions in which applications can run.
4. You can set the resource percentage for different queues in each node partition.
5. If the required node label is specified in a resource request, the resource is allocated only from nodes with the specified label. If no node label is specified (the default label name of a queue can be modified by using a configuration item), the resource is allocated only from nodes that belong to the default partition.
Configuration
1. Setting ResourceManager to enable Capacity Scheduler
Label-based scheduling can be used only in conjunction with Capacity Scheduler. Capacity Scheduler is the default scheduler of YARN. If you are using another scheduler, specify the following settings in ${HADOOP_HOME}/etc/hadoop/yarn-site.xml to enable Capacity Scheduler first:
Set yarn.scheduler.capacity.root to specify the predefined root queue of Capacity Scheduler in ${HADOOP_HOME}/etc/hadoop/capacity-scheduler.xml. All other queues are subqueues of the root queue. All queues are organized in a tree structure. Set yarn.scheduler.capacity.<queue-path>.queues to specify subqueues under queue-path and separate different subqueues by commas (,).
<value>centralized or delegated-centralized or distributed</value>
</property>
Note:
1. Make sure that yarn.node-labels.fs-store.root-dir is created and that ResourceManager has access to it.
2. You can store node labels in the local file system of ResourceManager in paths such as file://home/yarn/node-label. However, to ensure high availability of the cluster and to avoid label loss due to the failure of ResourceManager, we recommend that you store node labels in HDFS.
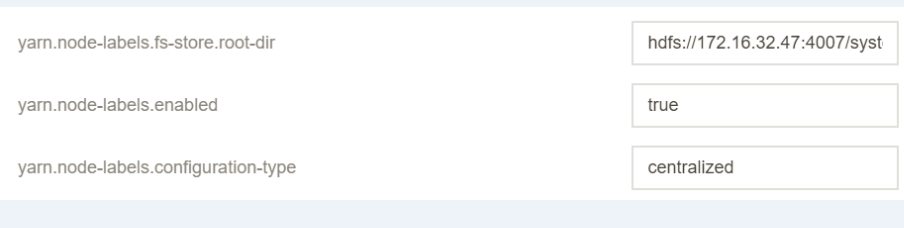
3. If you use Hadoop 2.8.2, you need to set yarn.node-labels.configuration-type.
4. Configuring node labels
You can configure node labels in etc/hadoop/capacity-scheduler.xml.
Configuration Item
Description
yarn.scheduler.capacity.<queue-path>.capacity
The percentage of nodes in the DEFAULT partition that are accessible to a queue. The values of this configuration item of all direct subqueues under each parent queue must sum up to 100.
A list of labels that are accessible to a queue. Labels are separated by commas (,). For example, "HBASE,STORM" specifies that the queue can access the HBASE and STORM labels. All queues can access nodes without labels. If this configuration item is not specified for a queue, the queue inherits the value from its parent queue. If you want a queue to access only nodes without labels, leave this configuration item unspecified.
The percentage of nodes in the <label> partition that are accessible to a queue. The values of this configuration item of all direct subqueues under each parent queue must sum up to 100. The default value is 0.
Similar to yarn.scheduler.capacity.<queue-path>.maximum-capacity of Capacity Scheduler, this configuration item specifies the maximum percentage of nodes in the <label> partition that are accessible to a queue. The default value is 100.
If no node label is specified in a resource request, applications are submitted to the partition specified by this configuration item. By default, the value is empty, which indicates that containers on nodes without a label are assigned to the applications.
Use Cases
Preparations
1. Prepare the cluster.
Make sure that you have activated Tencent Cloud and created an EMR cluster.
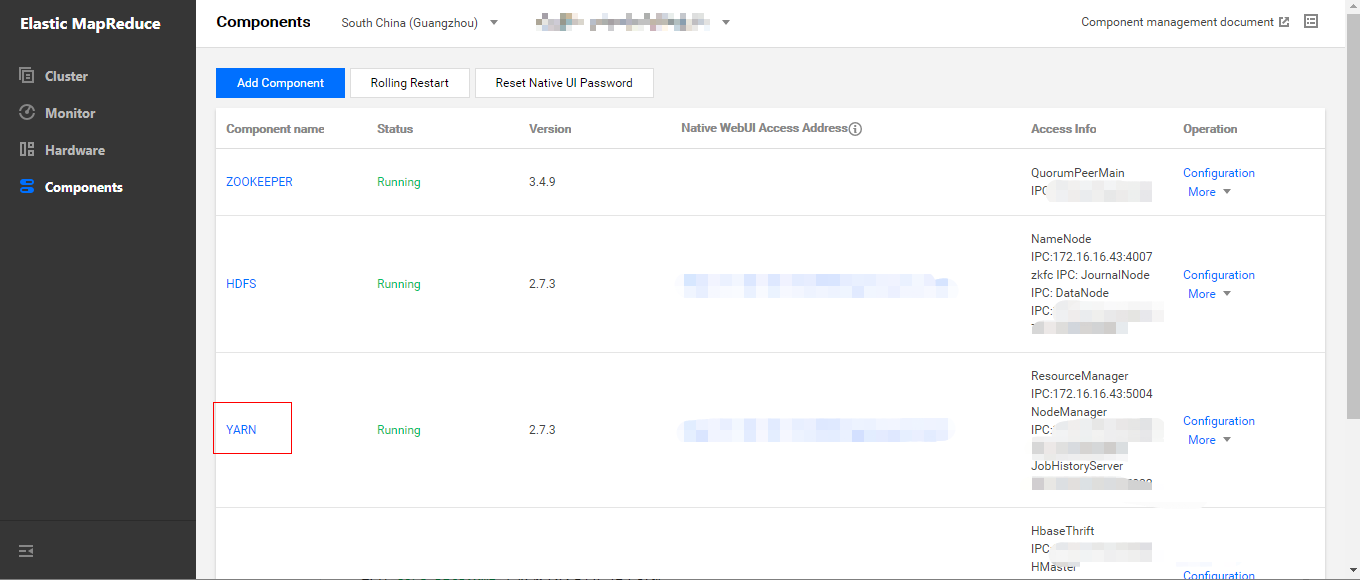
2. Check configurations of the YARN component.
On the Cluster Service page, click YARN to go to the component management page. On the Configuration Management tab, modify relevant parameters in yarn-site.xml, save the changes, and restart all YARN components. On the Role Management tab, confirm the IP address of the node where the ResourceManager service is located. Then, switch to the Configuration Management tab to modify relevant parameters in yarn-site.xml, save the changes, and restart all YARN components.
Find the cluster instance in the list of clusters, and click its ID to go to the cluster information page. Then, click Cluster Service on the left sidebar, and choose Operations > Configuration Management in the YARN component block.
Confirm the IP address of the ResourceManager service.
On the Configuration Management tab of the YARN component, select Cluster-level for Dimension, and select the IP address of the ResourceManager service as the node. Then, click Modify Configuration to modify the yarn.resourcemanager.scheduler.class parameter in yarn-site.xml on the selected node.
Configuring the mapping between node labels and queues and the resource percentage of queues in Capacity-Scheduler.xml
1. Create an HDFS directory to store node labels.
2. Obtain the IP address and port number of the NameNode (NN) in core-site.xml.
3. Create new configuration items in yarn-site.xml for the master node and then restart ResourceManager.
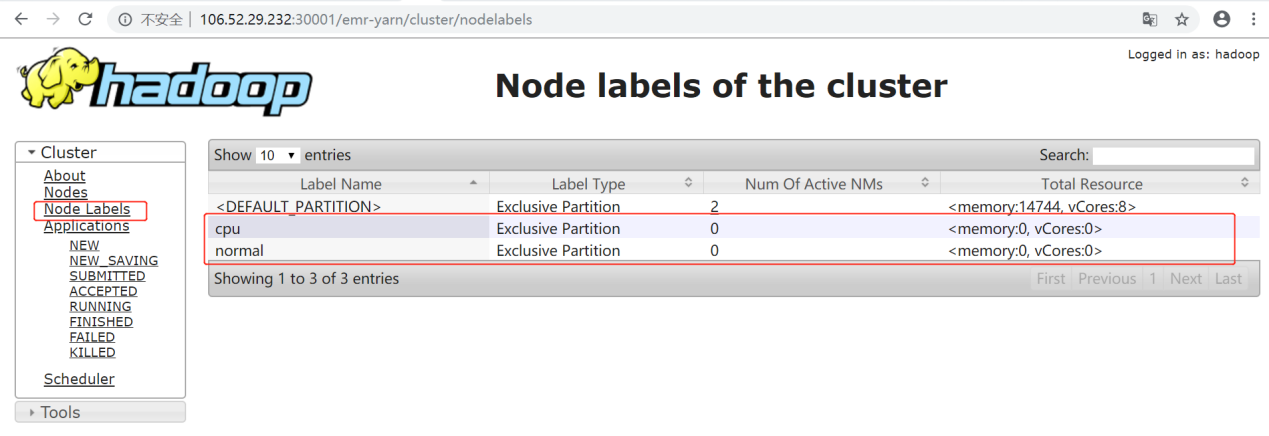
4. Run the yarn rmadmin -addToClusterNodeLabels command to add labels.
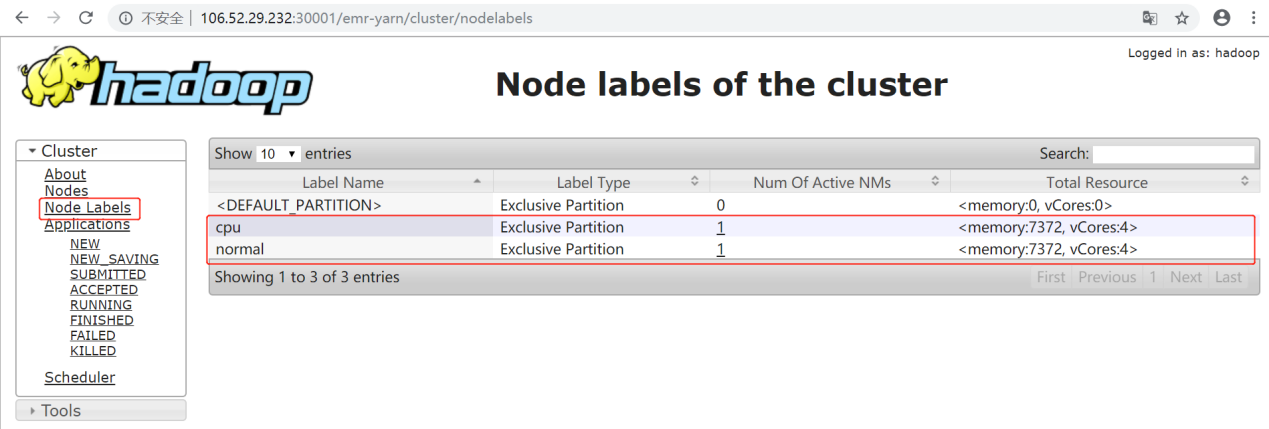
Open the YARN WebUI. You can see all the labels of the cluster in the Node Labels panel.
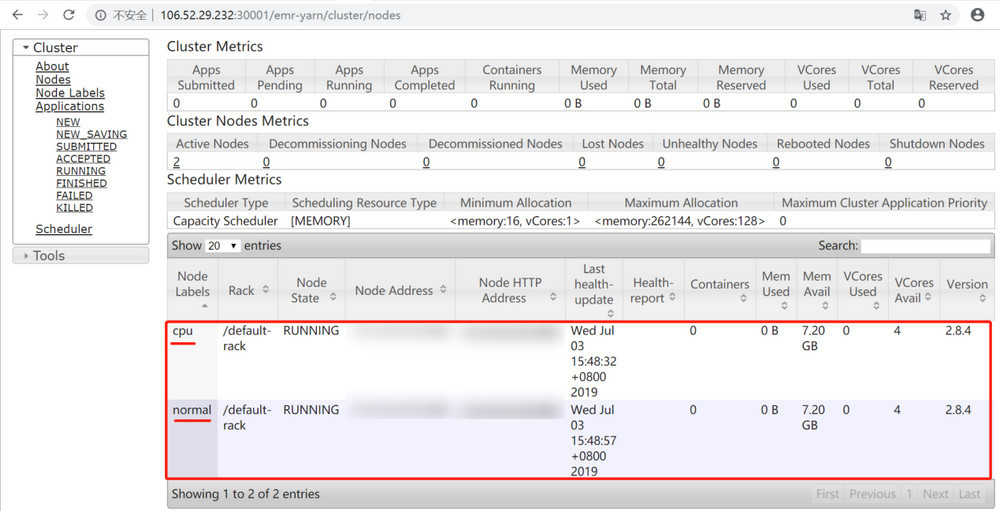
5. Run the yarn rmadmin -replaceLabelsOnNode command to label nodes.
In the Node Labels panel, the number of nodes in the normal partition and cpu partition changes from 0 to 1.
In the Scheduler panel, the two nodes in the test system are respectively labeled with normal and cpu.
6. Edit the configuration items in Capacity-Scheduler.xml to configure the cluster queues, resource percentages of queues, and labels accessible to queues. Example:
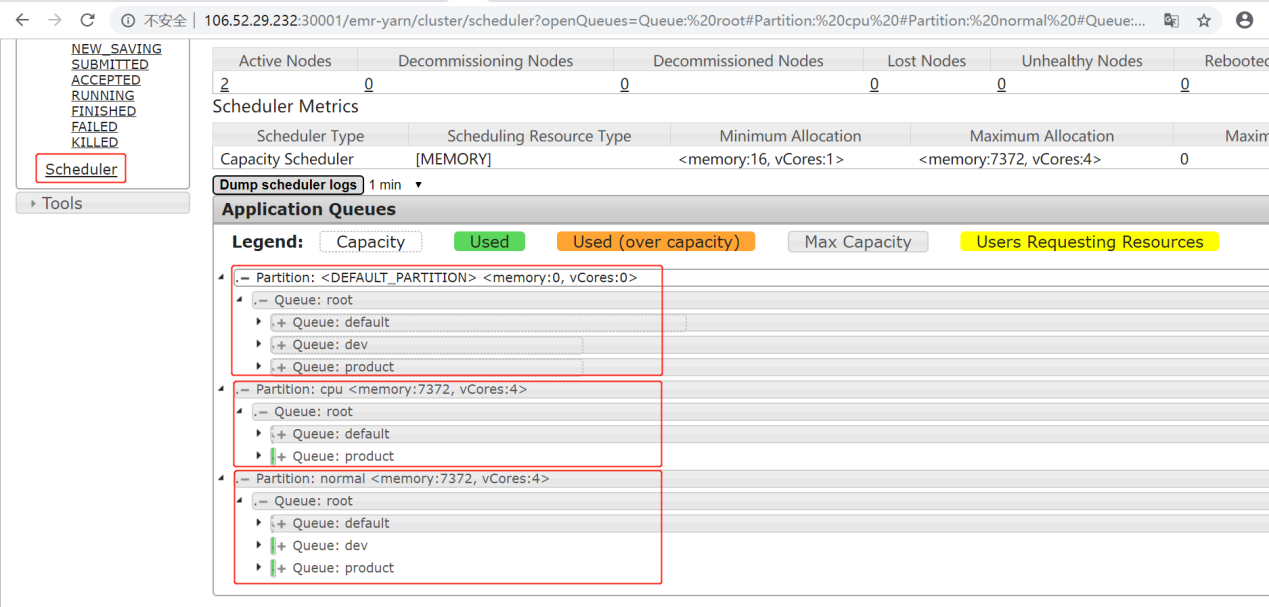
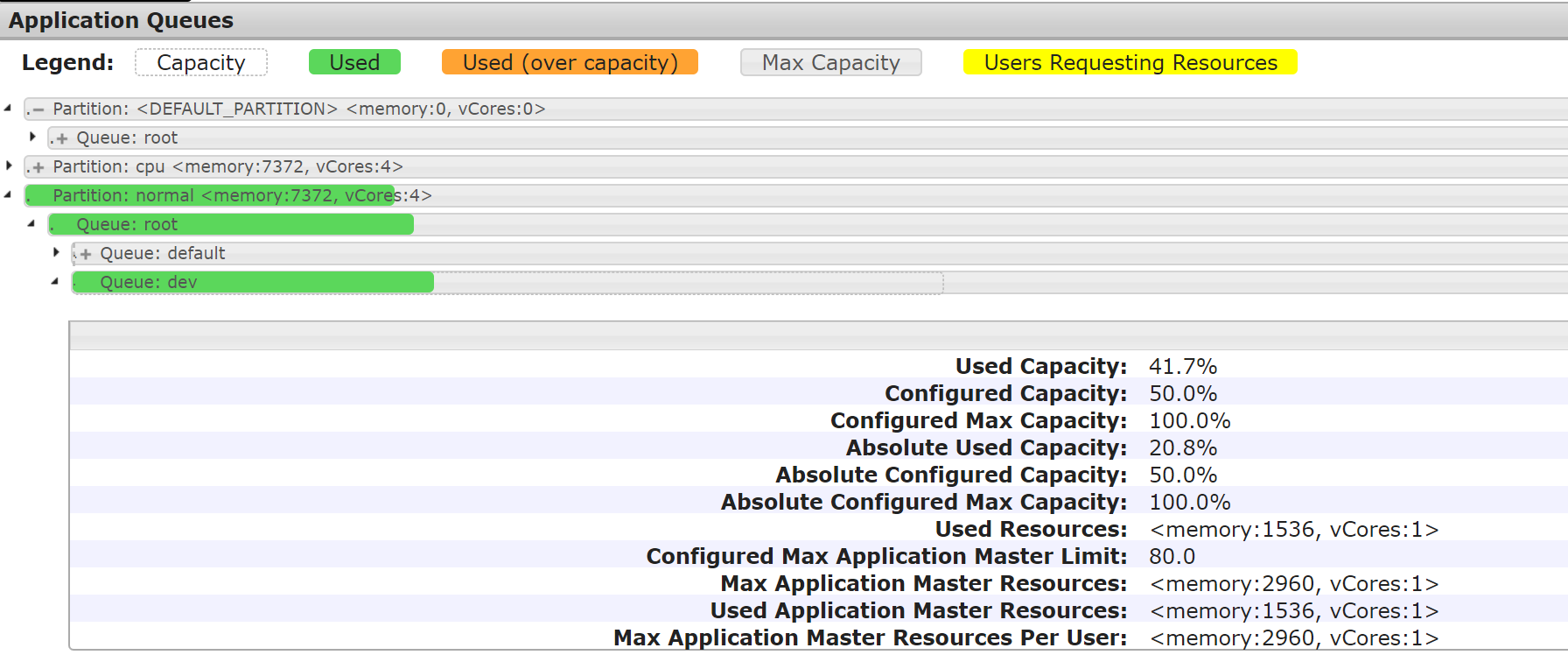
The Scheduler panel displays the information about the three partitions of the test cluster and the resources and queues in each partition. The Application Queues panel displays the default, normal, and cpu partitions. The default partition is the default one. The normal partition consists of nodes with the normal label. The cpu partition consists of nodes with the cpu label. The test cluster has two nodes, which are labeled normal and cpu. To view the queues in a partition, click the plus sign (+) on the left of the partition name.
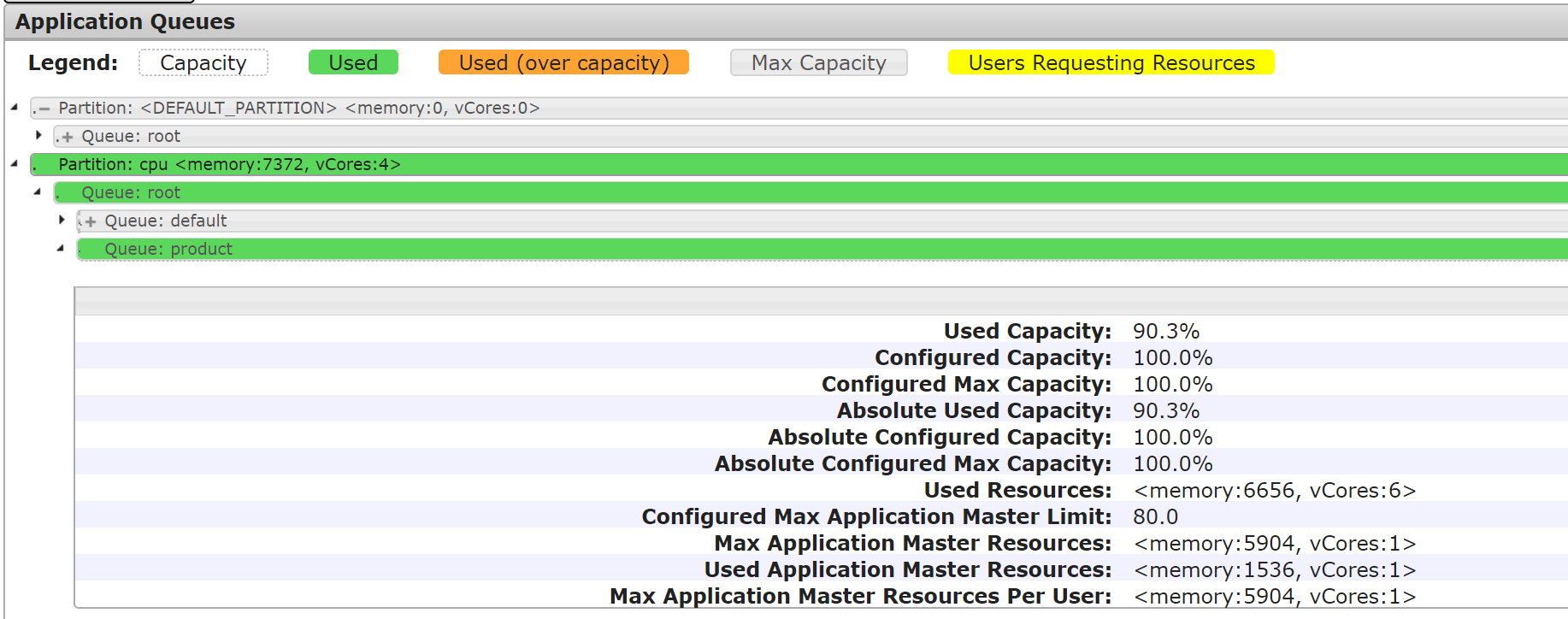
After the job is submitted, the usage of queue resources in each partition is shown in the following figure:
Conclusion: The product queue is mapped to the cpu label and the cpu label is used by default. The job submitted to the product queue runs on the node with the cpu label.
After the job is submitted, the usage of queue resources in each partition is shown in the following figure:
Conclusion: The dev queue is mapped to the normal label and the normal label is used by default. The job submitted to the dev queue runs on the node with the normal label.





 Yes
Yes
 No
No
Was this page helpful?