水平伸缩基本操作
Download
Focus Mode
Font Size
操作场景
实例(Pod)自动扩缩容功能(Horizontal Pod Autoscaler,HPA)可以根据目标实例 CPU 利用率的平均值等指标自动扩展、缩减服务的 Pod 数量。本文介绍如何通过腾讯云容器服务控制台实现 Pod 自动扩缩容。
工作原理
HPA 后台组件会每隔15秒向腾讯云云监控拉取容器和 Pod 的监控指标,然后根据当前指标数据、当前副本数和该指标目标值进行计算,计算所得结果作为服务的期望副本数。当期望副本数与当前副本数不一致时,HPA 会触发 Deployment 进行 Pod 副本数量调整,从而达到自动伸缩的目的。
以 CPU 利用率为例,假设当前有2个实例, 平均 CPU 利用率(当前指标数据)为90%,自动伸缩设置的目标 CPU 为60%, 则自动调整实例数量为:90% × 2 / 60% = 3个。
注意:
如果用户设置了多个弹性伸缩指标,HPA 会依据各个指标,分别计算出目标副本数,取最大值进行扩缩容操作。
注意事项
当指标类型选择为 CPU 利用率(占 Request)时,必须为容器设置 CPU Request。
策略指标目标设置合理,例如设置70%给容器和应用,预留30%的余量。
保持 Pod 和 Node 健康(避免 Pod 频繁重建)。
保证用户请求的负载均衡稳定运行。
HPA 在计算目标副本数时会有一个10%的波动因子。如果在波动范围内,HPA 并不会调整副本数目。
如果服务对应的 Deployment.spec.replicas 值为0,HPA 将不起作用。
如果对单个 Deployment 同时绑定多个 HPA ,则创建的 HPA 会同时生效,会造成工作负载的副本重复扩缩。
前提条件
已 注册腾讯云账户。
已登录 腾讯云容器服务控制台。
已创建集群。操作详情请参见 创建集群。
操作步骤
开启自动扩缩容
可以通过以下三种方式开启自动扩缩容。
通过设置实例数量调节
1. 在 集群 管理中,单击需要创建伸缩组的集群 ID。
2. 选择工作负载 > Deployment,在 Deployment 页面单击新建。
3. 在新建 Deployment 页面,设置实例数量为自动调节。如下图所示:
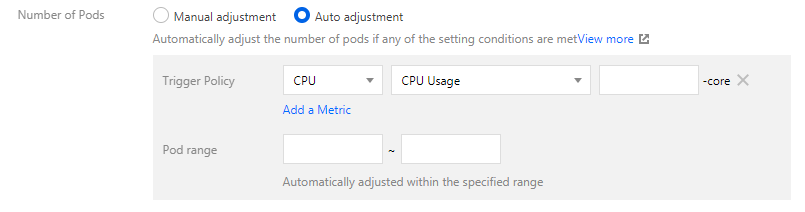
触发策略:自动伸缩功能依赖的策略指标。详情请参见 指标类型。
实例范围:请根据实际需求进行选择,实例数量会在设定的范围内自动调节,不会超出该设定范围。
通过新建自动伸缩组
1. 在 集群 管理中,单击需要创建伸缩组的集群 ID。
2. 选择自动伸缩 > HorizontalPodAutoscaler,在 HorizontalPodAutoscaler 页面单击新建。
3. 在新建 HPA 页面,根据以下提示,进行 HPA 配置。如下图所示:
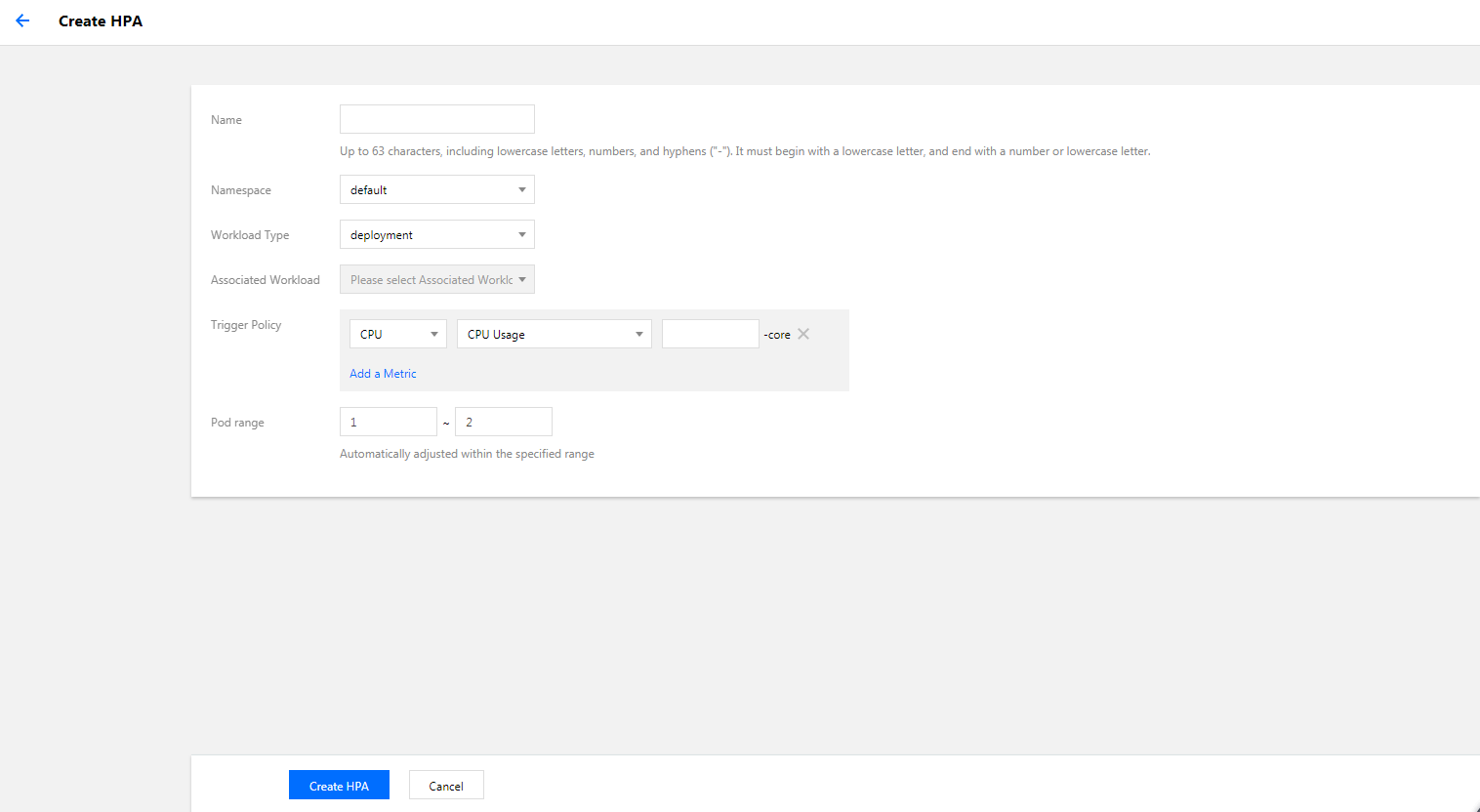
名称:输入要创建的自动伸缩组的名称。
命名空间:请根据实际需求进行选择。
工作负载类型:请根据实际需求进行选择。
关联工作负载:不能为空,请根据实际需求进行选择。
触发策略:自动伸缩功能依赖的策略指标,详情请参见 指标类型。
实例范围:请根据实际需求进行选择,实例数量会在设定的范围内自动调节,不会超出该设定范围。
4. 单击创建 HPA。
通过 YAML 创建
1. 在 集群 管理中,单击需要创建伸缩组的集群 ID。
2. 在集群基本信息页,单击该页面右上角 YAML 创建资源。如下图所示:

3. 在 YAML 创建资源页面,根据实际需求编辑内容,单击完成,即可新建 HPA 。
更新自动扩缩容规则
可以通过以下三种方式更新服务自动扩缩容规则。
通过更新 Pod 数量
1. 在 集群 管理中,单击目标集群 ID。
2. 选择工作负载 > Deployment,在 Deployment 页面单击更新 Pod 数量。

3. 在更新 Pod 数量页面,选择自动调节,并根据实际需求进行设置。如下图所示:
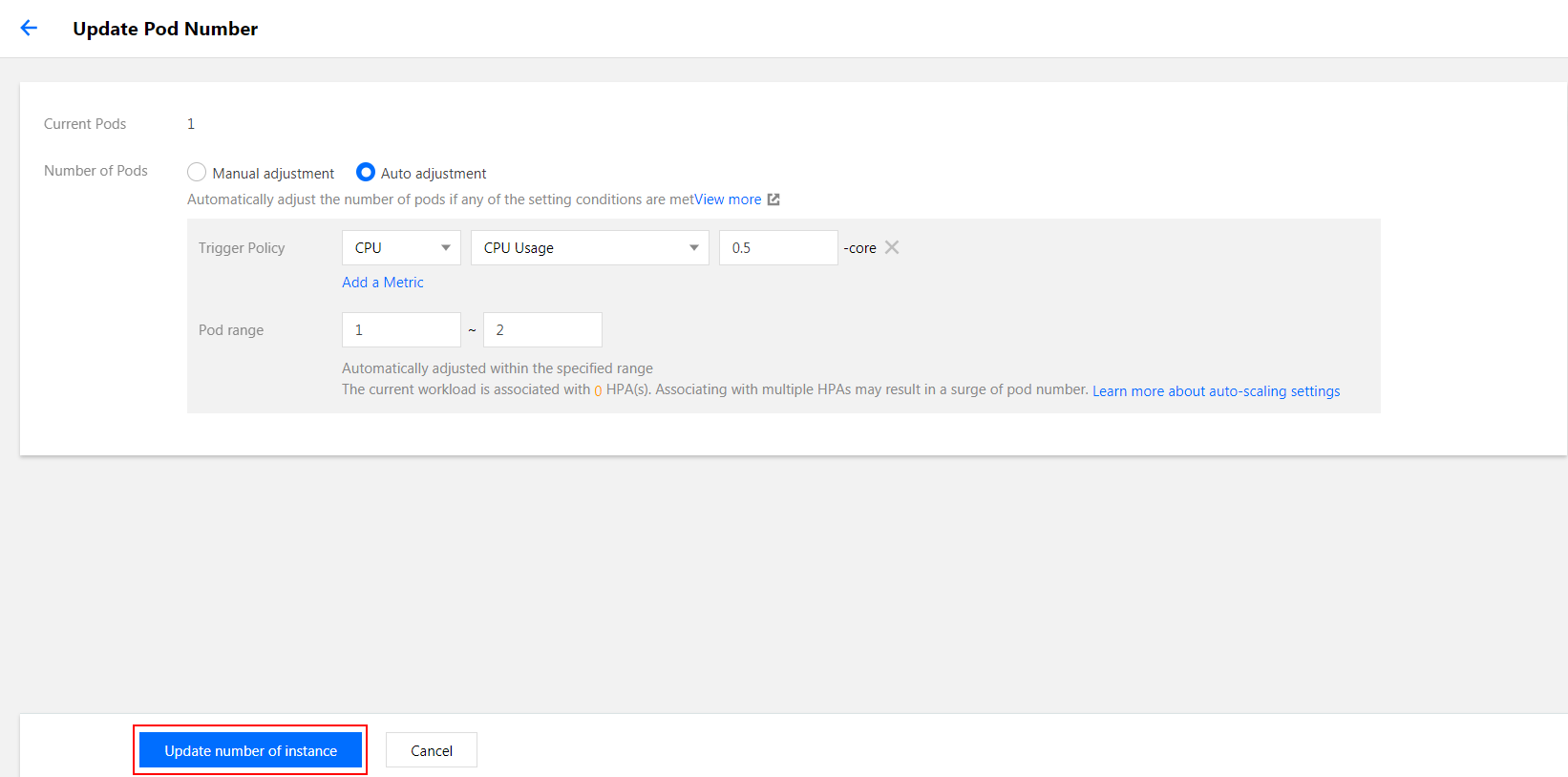
4. 单击更新实例数量。
通过修改 HPA 配置
1. 在 集群 管理中,单击需要创建伸缩组的集群 ID。
2. 选择自动伸缩 > HorizontalPodAutoscaler,在 HorizontalPodAutoscaler 页面单击需要更新配置的 HPA 所在行右侧的修改配置。如下图所示:
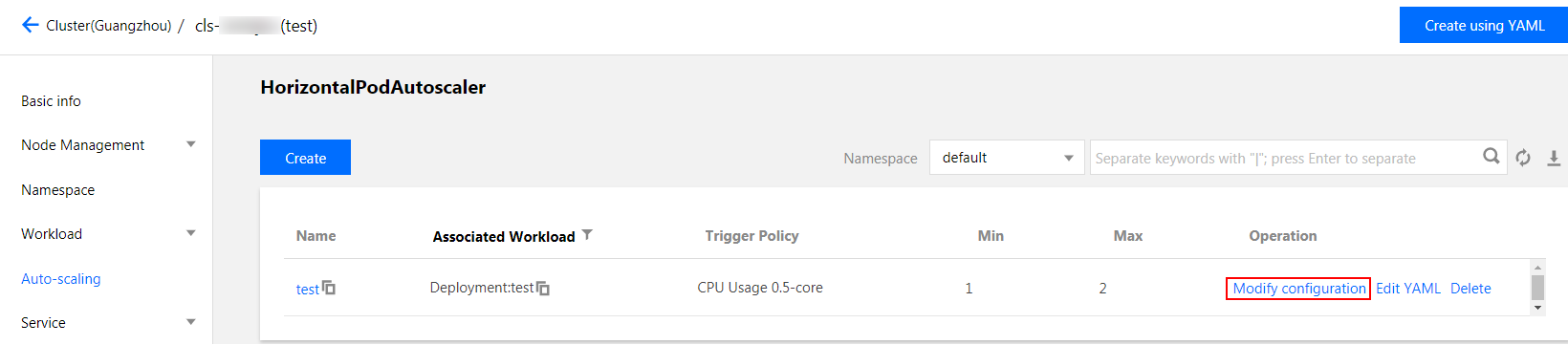
3. 在更新配置页面,根据实际需求进行设置后,单击更新 HPA。
通过编辑 YAML 更新
1. 在 集群 管理中,单击需要创建伸缩组的集群 ID。
2. 选择自动伸缩 > HorizontalPodAutoscaler,在 HorizontalPodAutoscaler 页面单击需要更新配置的 HPA 所在行右侧的编辑 YAML。如下图所示:

3. 在编辑 Yaml 页面,根据实际需求进行编辑,单击完成即可。
指标类型
Help and Support
Was this page helpful?
You can also Contact sales or Submit a Ticket for help.
Help us improve! Rate your documentation experience in 5 mins.
Feedback