TKE 集群中节点移出再移入操作指引
下载
聚焦模式
字号
操作场景
在容器服务 TKE 的众多场景中,例如 K8S 版本升级、内核版本升级等,都需要进行节点移出再移入的操作。本文详细介绍了节点移出再移入的过程,主要分为以下几个步骤:
1. 驱逐节点上运行的 Pod。
2. 将节点移出集群再重新添加到集群,该节点将重装系统。
3. 解除封锁。
注意事项
如果单个集群中的多个节点都需进行移出再移入操作,建议逐个节点进行。即先完成单个节点移出再移入操作,并验证服务正常,再进行下一个节点的移出再移入操作,直到多个节点依次完成。
如果单个账号下的多个集群都需进行节点移出再移入操作,建议分批执行。且在每操作完一个集群之后,立即验证集群状态是否正常。
操作步骤
步骤1:驱逐 Pod
在集群节点进行移入再移出操作之前,需先将待移出节点上的 Pod 驱逐到其他节点上运行。驱逐的过程即逐个删除节点上的 Pod,再前往其他节点进行重建。
驱逐原理
为了简化节点维护操作,K8S 引入了
drain 命令,其使用原理如下:K8S 1.4 之后的版本,
drain 操作为先对节点进行封锁,再对节点上的所有 Pod 进行删除操作。如果该 Pod 被 Deployment 等控制器所管理,则控制器在检查到 Pod 副本数减少的情况下,会重新创建一个 Pod ,调度到其他满足条件的节点上。如果该 Pod 是裸 Pod ,不被控制器管理,则驱逐后不会重新创建。 此过程是先删除,再创建,并非滚动更新。因此更新过程中,可能会导致被驱逐的服务部分请求失败,如果被驱逐的服务所有相关 Pod 都在被驱逐的节点上,则可能导致该服务完全不可用。
为了避免这一情况的出现, K8S 1.4 之后的版本引入了 PDB。只要在 PDB 策略文件中选中某个业务(一组 Pod),声明该业务可容忍的最小副本数量,此时再执行
drain 操作,将不再直接删除 Pod,而是会通过 evict api 检查是否满足 PDB 策略,只有在满足 PDB 策略的情况下才会对 Pod 进行删除,保护了业务可用性。需要注意的是,只有正确配置 PDB 策略才能保证 drain 操作时业务影响在可控范围内。 驱逐前检查
驱逐的过程涉及了 Pod 的重建,可能会对集群中的服务造成影响,因此建议在驱逐前执行如下检查:
1. 检查集群中的剩余节点是否有足够资源去运行待驱逐节点上的 Pod。节点的资源分配情况可通过容器服务控制台查看。在 集群列表 页面,选择目标集群 ID > 节点管理 > 节点,检查“节点列表”页面中的“已分配/总资源”。如下图所示:
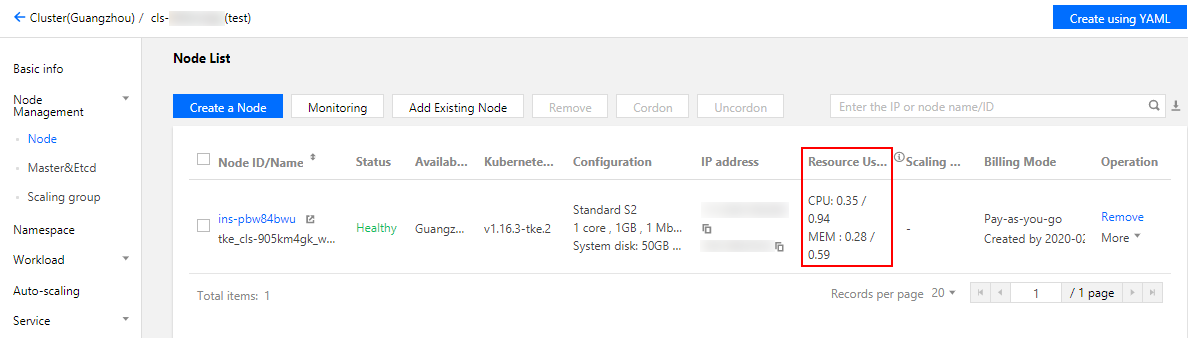
2. 检查集群中是否有配置主动驱逐保护 PodDisruptionBudget(PDB)。主动驱逐保护会中断驱逐操作的执行,建议先删除主动驱逐保护 PDB。
3. 检查集群中是否存在单个服务的所有 Pod 都落在待驱逐的节点上。如果单个服务的所有 Pod 都落在同一个节点上,驱逐 Pod 的动作会造成整个服务不可用。建议判断该服务是否强要求 Pod 都落在同一个节点上:
否,建议给服务增加反亲和性调度。
是,建议选择在业务低流量或者无流量的时间段内操作。
4. 检查服务是否使用了本地盘(hostpath)。如果服务使用了
hostpath volume 方式,则当 Pod 被调度到其他节点上时,数据会丢失,可能会对业务造成影响。如果是重要数据,建议先备份再进行驱逐。说明:
目前 kubelet 的镜像拉取策略是串行的,如果短时间内有大量的 Pod 都被调度到同一个节点上之后,Pod 的启动时间有可能会变长。
操作详情
目前,对于 TKE 集群可以有以下两种方式完成驱逐:
1. 在 集群列表 页面,单击目标集群 ID。
2. 在集群详情页中,选择节点管理 > 节点。
3. 在节点页面,选择目标节点所在行右侧的驱逐。如下图所示:
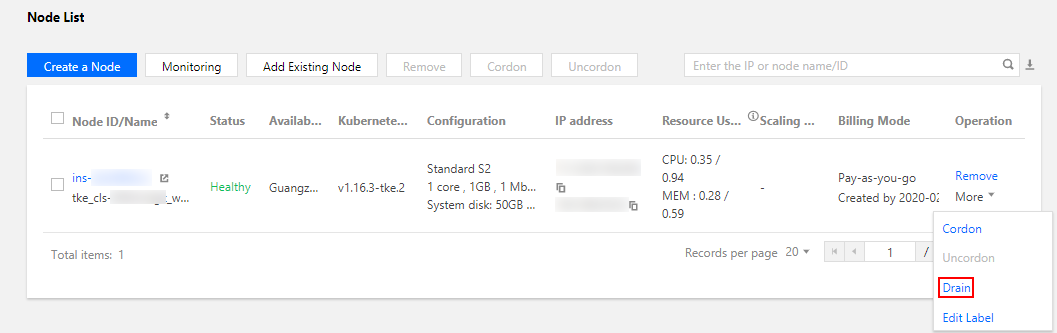
4. 在弹窗中确认节点信息,并单击确定以驱逐节点上运行的 Pod。
步骤2:移出节点
当节点上运行的 Pod 被驱逐后,该节点处于封锁状态。如下图所示:

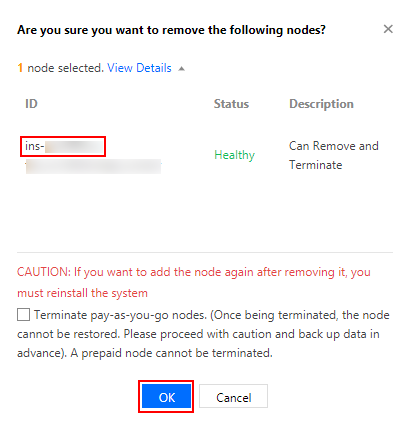
1. 在节点列表页面,单击目标节点所在行右侧的移出。
2. 在弹出窗口中,取消勾选“销毁按量计费的节点”,并单击确定即可将节点移除集群。如下图所示:
说明:
请记录该节点 ID,用于重新添加到集群。
如果该节点是按量计费节点,注意不要勾选销毁按量计费的节点,销毁后不可恢复。
步骤3:重新加入该节点到集群
1. 在节点列表页面,单击页面上方的添加已有节点。
2. 在添加已有节点页面,输入记录的节点 ID,并单击
3. 在搜索结果列表中勾选节点,并配置云服务器其他参数。如下图所示:
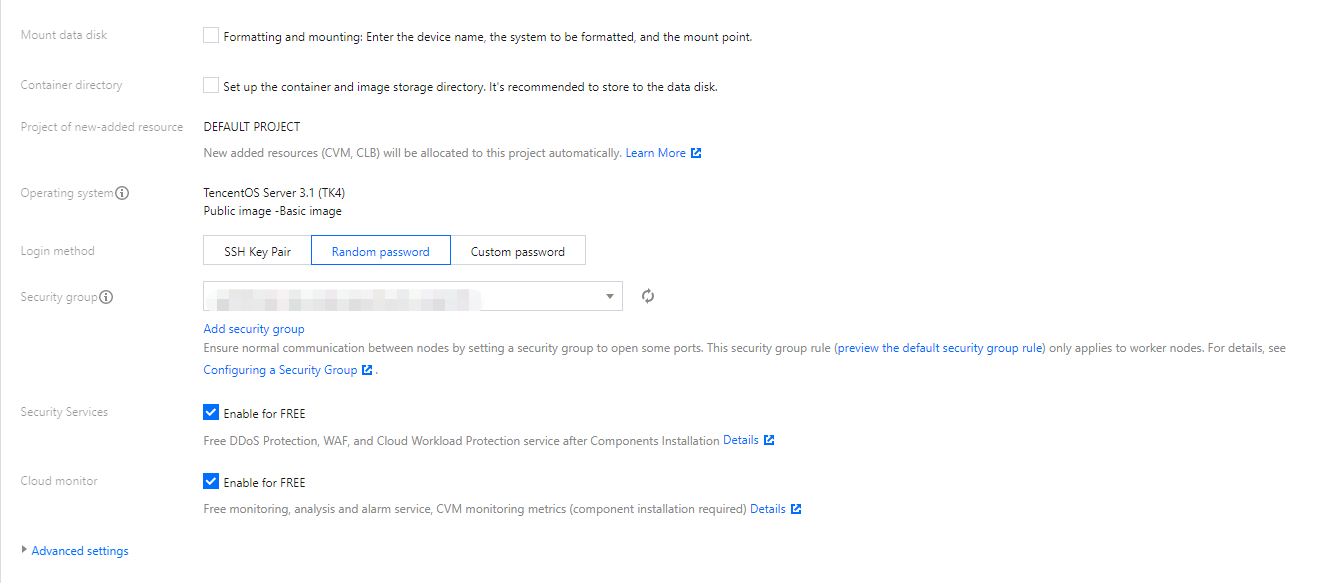
注意:
数据盘挂载与容器目录默认不勾选。
如果您需要将容器和镜像存储在数据盘,则勾选数据盘挂载。选择数据盘挂载时,已格式化的 ext3、ext4、xfs 文件系统的系统盘将直接挂载,其他文件系统或未格式化的数据盘将自动格式化为 ext4 并挂载。
如果您需要保留数据盘数据并挂载,且需要避免数据盘被格式化,可参考以下步骤:
1. 在云服务器配置页面,不勾选数据盘挂载。
2. 打开“高级设置”,在“自定义数据”输入以下节点初始化脚本,并勾选开启封锁。如下图所示:
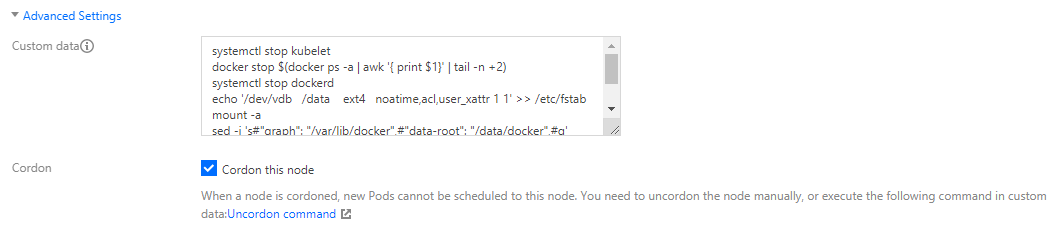
systemctl stop kubeletdocker stop $(docker ps -a | awk '{ print $1}' | tail -n +2)systemctl stop dockerdecho '/dev/vdb /data ext4 noatime,acl,user_xattr 1 1' >> /etc/fstabmount -ased -i 's#"graph": "/var/lib/docker",#"data-root": "/data/docker",#g' /etc/docker/daemon.jsonsystemctl start dockerdsystemctl start kubelet
4. 请根据实际情况进行登录密码及安全组设置,并单击完成,等待节点添加成功。
步骤4:解除封锁
说明:
节点添加成功后,处于封锁状态。
1. 在“节点列表页面,选择该节点所在行右侧的更多 > 取消封锁。
2. 在弹出窗口中,单击确定即可解除封锁。
文档反馈