节点池概述
Download
聚焦模式
字号
简介
为帮助您高效管理 Kubernetes 集群内节点,腾讯云容器服务 TKE 引入节点池概念。借助节点池基本功能,您可以方便快捷地创建、管理和销毁节点,以及实现节点的动态扩缩容:
当集群中出现因资源不足而无法调度的实例(Pod)时,自动触发扩容,为您减少人力成本。
当满足节点空闲等缩容条件时,自动触发缩容,为您节约资源成本。
产品架构
节点池整体架构图如下所示:
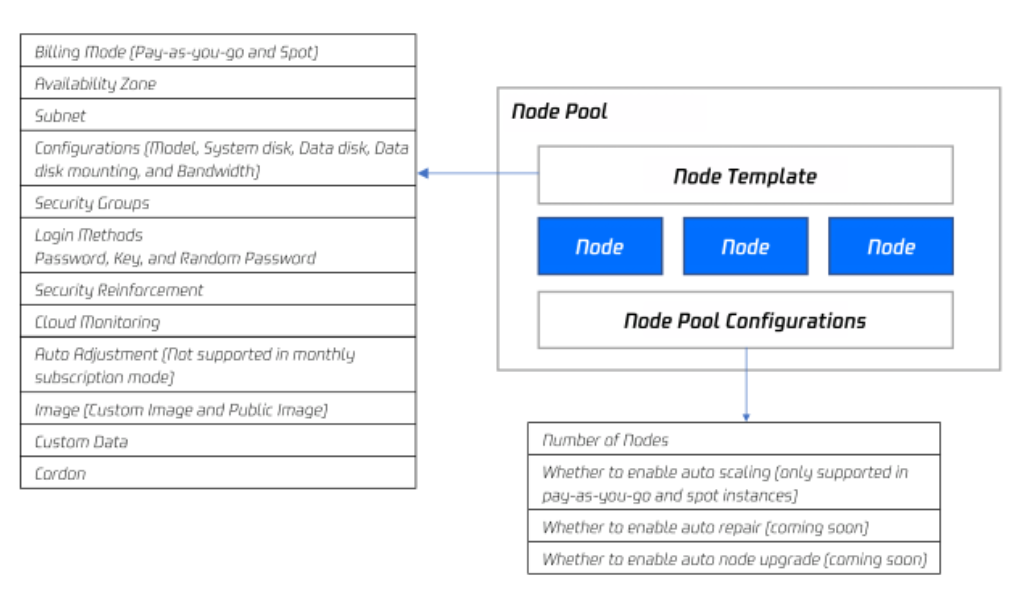
通常情况下,节点池内的节点均具有如下相同属性:
节点操作系统。
计费类型(目前支持按量计费和竞价实例)。
CPU/内存/GPU。
节点 Kubernetes 组件启动参数。
节点自定义启动脚本。
节点 Kubernetes Label 和 Taint 设置。
此外,TKE 将同时围绕节点池扩展以下功能:
支持用 CRD 管理节点池。
节点池级别每节点的 Pod 数上限。
节点池级别自动修复与自动升级。
应用场景
当业务需要使用大规模集群时,推荐您使用节点池进行节点管理,以提高大规模集群易用性。下表介绍了多种大规模集群管理场景,并分别展示节点池在每种场景下发挥的作用:
场景 | 作用 |
集群存在较多异构节点(机型配置不同) | 通过节点池可规范节点分组管理。 |
集群需要频繁扩缩容节点 | 通过节点池可提高运维效率,降低人力成本。 |
集群内应用程序调度规则复杂 | 通过节点池标签可快速指定业务调度规则。 |
集群内节点日常维护 | 通过节点池可便捷操作 Kubernetes 版本升级、Docker 版本升级。 |
相关概念
CA:cluster-autoscaler,社区开源组件,主要负责集群的弹性扩缩容。
AS:Auto Scaling,腾讯云弹性伸缩服务。
ASG:Auto Scaling Group,具体某个节点池(节点池依赖弹性伸缩服务提供的伸缩组,一个节点池对应一个伸缩组,您只需关心节点池)。
ASA:AS activity,某次伸缩活动。
ASC:AS config,AS 启动配置,即节点模板。
节点池内节点种类
为了满足不同场景下的需求,节点池内的节点可以分为两个类型。
说明:
无特殊场景不推荐您使用添加已有节点功能,例如您没有新建节点的权限仅能通过添加已有节点来扩容集群,添加已有节点部分参数可能会与您定义的节点的模板不一致,将无法参与弹性伸缩。
节点类型 | 节点来源 | 是否支持弹性伸缩 | 从节点池移除方式 | 节点数目是否受调整数量影响 |
伸缩组内节点 | 弹性扩容或手动调整数量 | 是 | 弹性缩容或手动调整数量 | 是 |
伸缩组外节点 | 用户手动加入节点池 | 否 | 用户手动移除 | 否 |
节点池弹性伸缩原理
在您使用节点池弹性伸缩功能前,请阅读以下原理说明。
节点池弹性扩容原理
1. 当集群中资源不足时(集群的计算/存储/网络等资源满足不了Pod 的request /亲和性规则),CA(Cluster Autoscaler)会监测到因无法调度而 Pending 的 Pod 。
2. CA 根据每个节点池的节点模板进行调度判断,挑选合适的节点模板。
3. 若有多个模板合适,即有多个可扩的节点池备选,CA 会调用 expanders 从多个模板挑选最优模板并对对应节点池进行扩容。
4. 对指定节点池进行扩容 (根据多子网多机型策略),并且提供两种重试策略(可在创建节点池设置),在扩容失败时根据您设定的重试策略进行重试。
说明:
对特定节点池扩容时,会根据您创建节点池设置的子网以及后续设置的多机型配置来进行扩容。一般情况下会先保证多机型的策略,后保证多可用区/子网的策略。
例如您配置了多机型 A、B,多子网1、2、3,会按照 A1、A2、A3、B1、B2、B3 进行尝试,如果A1售罄,会尝试 A2,而不是 B1。
节点池弹性扩容原理如下图所示: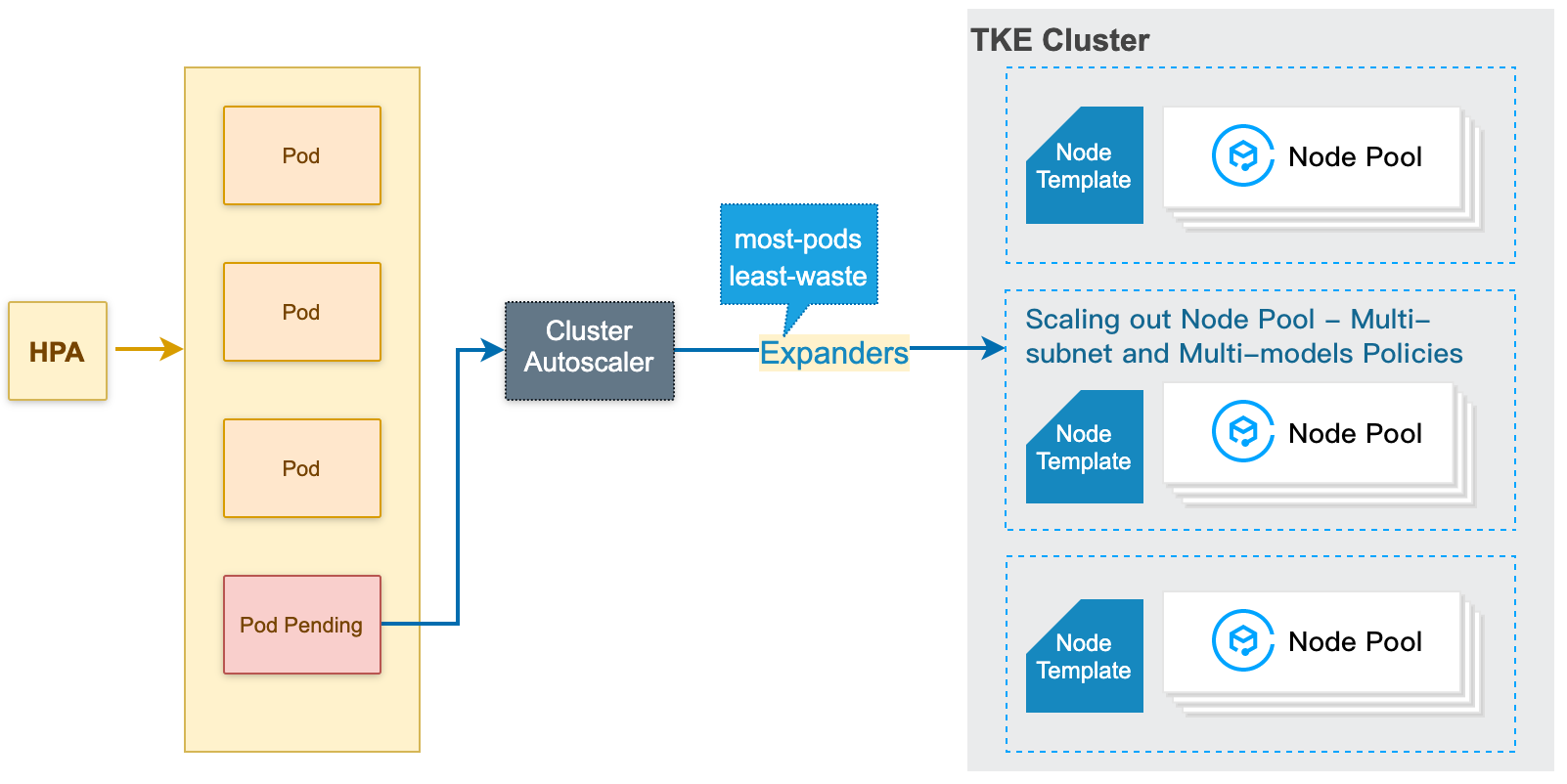
节点池弹性缩容原理
1. CA(Cluster Autoscaler)监测到分配率(即 Request 值,取 CPU 分配率和 MEM 分配率的最大值)低于设定的节点。计算分配率时,可以设置 Daemonset 类型不计入 Pod 占用资源。
2. CA 判断集群的状态是否可以触发缩容,需要满足如下要求:
节点空闲时长要求(默认10分钟)。
集群扩容缓冲时间要求(默认10分钟)。
3. CA 判断该节点是否符合缩容条件。您可以按需设置以下不缩容条件(满足条件的节点不会被 CA 缩容):
含有本地存储的节点。
含有 Kube-system namespace 下非 DaemonSet 管理的 Pod 的节点。
说明:
上述不缩容条件在集群维度生效,若您需要更细粒度的保护节点免于缩容,可以使用缩容保护功能。
4. CA 驱逐节点上的 Pod 后释放/关机节点。
完全空闲节点可并发缩容(可设置最大并发缩容数)。
非完全空闲节点逐个缩容。
节点池弹性缩容原理如下图所示: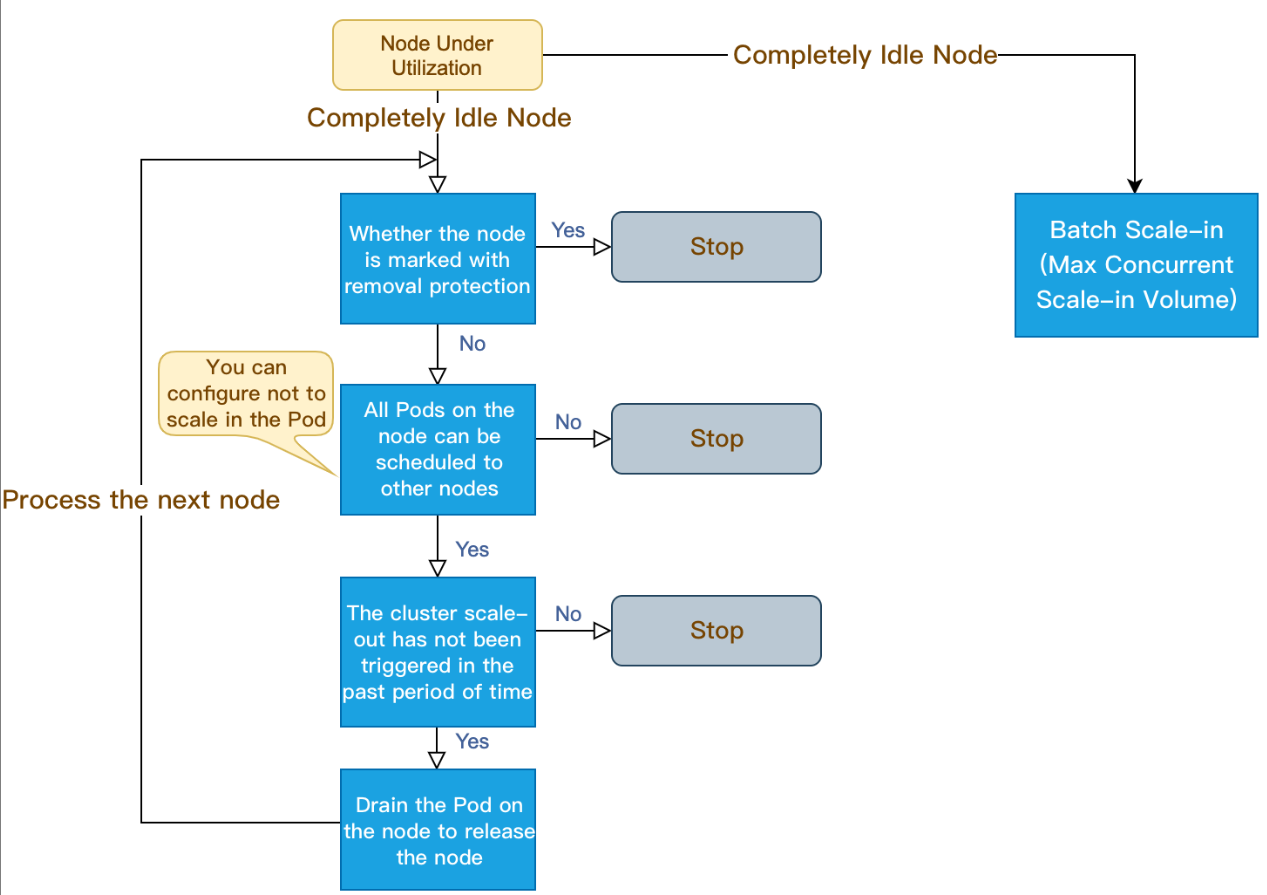
功能点及注意事项
功能点 | 功能说明 | 注意事项 |
新增节点池 | 单个集群不建议超过20个节点池。 | |
删除节点池时可选择是否销毁节点池内节点。 无论是否销毁节点,节点都不会保留在集群内。 | 删除节点池时选择销毁节点,节点将不会保留,后续如需使用新节点可重新创建。 | |
节点池开启弹性伸缩 | 开启弹性伸缩后,节点池内节点数量将随集群负载情况自动调整。 | 请勿在伸缩组控制台开启和关闭弹性伸缩。 |
| 节点池关闭弹性伸缩 | 关闭弹性伸缩后,节点池内节点数量不随集群负载情况自动调整。 |
调整节点池节点数量 | 支持直接调整节点池内节点数量。 若减小节点数量,将按节点移出策略(默认移出最老节点)从伸缩组内缩容节点。请注意:该缩容动作由伸缩组执行,TKE 无法感知具体缩容节点,无提前驱逐/封锁动作。 | 开启弹性伸缩后,不建议手动调整节点池大小。 请勿在伸缩组控制台直接调整伸缩组期望实例数。 无特殊情况,请勿手动缩容节点池,请使用弹性缩容:弹性缩容时会首先将节点标记为不可调度,随后驱逐或者删除节点上所有 Pod 后再释放节点。 |
可修改节点池名称、操作系统、伸缩组节点数量范围、Kubernetes label 及 Taint。 | 修改 Label 和 Taint 会对节点池内节点全部生效,可能会引起 Pod 重新调度,请谨慎变更。 | |
添加已有节点 | 可添加不属于集群的实例到节点池。要求如下: 实例与集群属于同一私有网络。 实例未被其他集群使用且实例与节点池配置相同机型、相同计费模式。 可添加集群内不属于任何节点池的节点,要求节点实例与节点池配置相同机型、相同计费模式。 | 无特殊情况时,不建议添加已有节点,推荐直接新建节点池。 |
移出节点池内节点 | 支持移出节点池内任意节点,移出时节点可选择是否保留到集群。 | 请勿在伸缩组控制台往伸缩组内加入节点,可能会导致数据不一致的严重后果。 |
原伸缩组转换节点池 | 支持存量伸缩组切换为节点池。转化后,节点池完全继承原伸缩组的功能,该伸缩组信息将不再展示。 集群内存量所有伸缩组切换完成后,不再提供伸缩组入口。 | 操作不可逆,请熟悉节点池功能后再进行切换。 |
相关操作
创建节点池
查看节点池
调整节点池
删除节点池
文档反馈