Horizontal Pod Autoscaler (HPA) for Kubernetes Pods can automatically adjust the number of replicas of Pods based on CPU usage, memory usage, and other custom metrics to make the overall level of workload services match the user-defined target value. This document introduces the HPA feature of TKE and how to use the feature to achieve automatic scaling of Pods.
Overview
The HPA feature provides TKE with a very flexible self-adaptation ability, allowing TKE to quickly increase the number of Pod replicas within the scope of user-defined settings to cope with the sudden rise of service loads and properly scale in when service loads decrease to save computing resources for other services. The entire process is automatic without the need for manual intervention. It’s suitable for service scenarios where service fluctuation is huge, the number of services is large, and frequent scaling is needed, such as e-commerce services, online education, and financial services.
Principle Overview
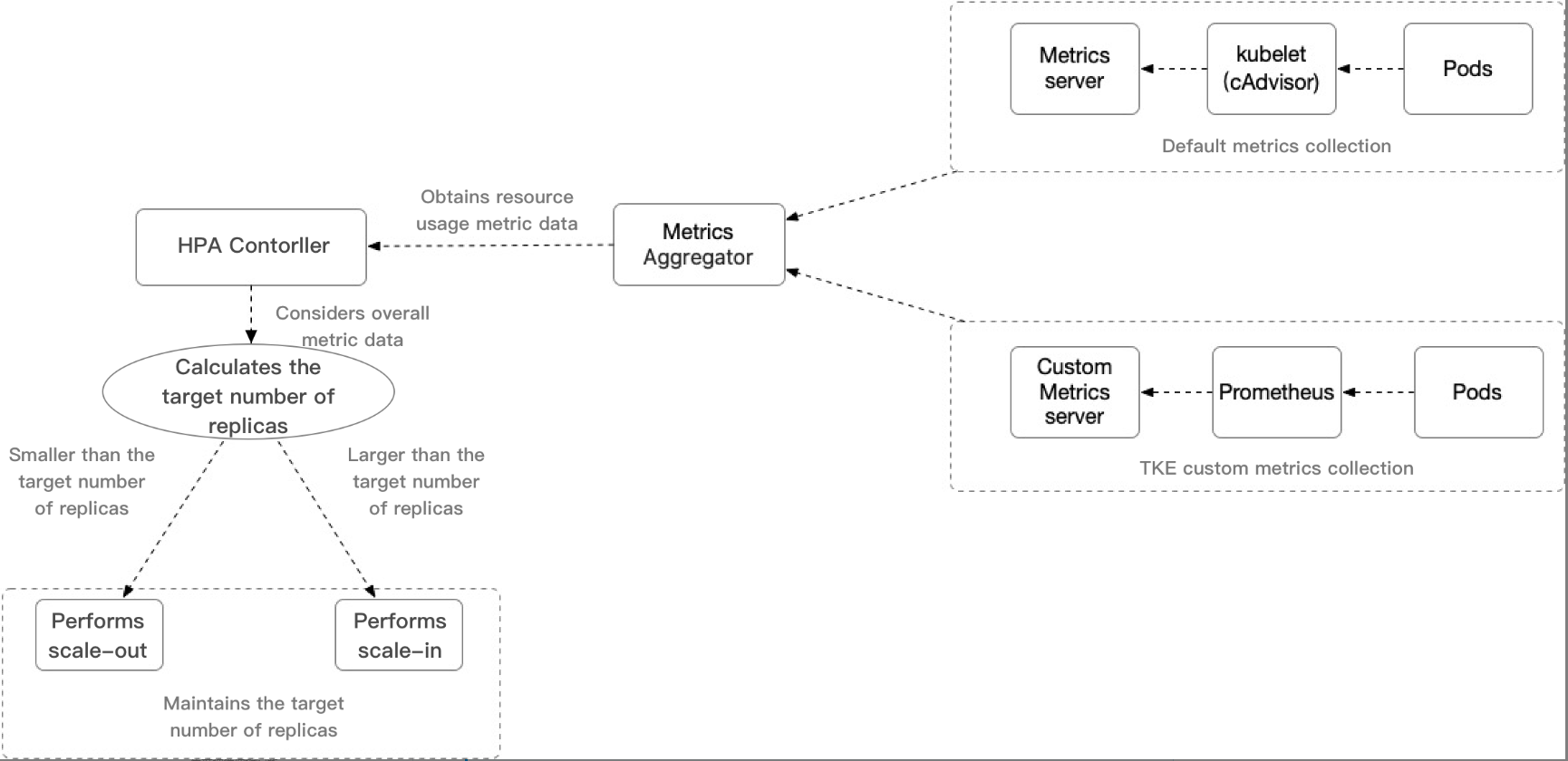
The HPA feature for Pods is realized by Kubernetes API resources and the controller. Resources use metrics to determine the behavior of the controller, whereas the controller periodically adjusts the number of replicas of service Pods based on Pod resource usage, thus making the level of workloads matches the user-defined target value. The following figure shows the scaling process:
Note
The automatic horizontal scaling of Pods does not apply to objects that cannot be scaled, such as DaemonSet resources.
Key content:
HPA Controller: The control component that controls the HPA scaling logic.
Metrics Aggregator: normally, the controller obtains metric values from a series of aggregation APIs (metrics.k8s.io, custom.metrics.k8s.io, and external.metrics.k8s.io). The metrics.k8s.io API is usually provided by the Metrics server. The community edition can provide the basic CPU and memory metric types. Compared with the community edition, the custom Metrics Server collection used by TKE supports a wider range of HPA metric trigger types, providing relevant metrics that include CPU, memory, disk, network, and GPU metrics. For more information, see Autoscaling Metrics.
Note
The controller can also obtain metrics from Heapster. However, starting from Kubernetes 1.11, the controller cannot obtain metrics from Heapster any more.
Calculates the target number of replicas: For information about the TKE HPA scaling algorithm, see How it Works. For more algorithm details, see Algorithm details.
You have created a TKE cluster. For more information, see Creating a Cluster.
Directions
Deploying test workloads
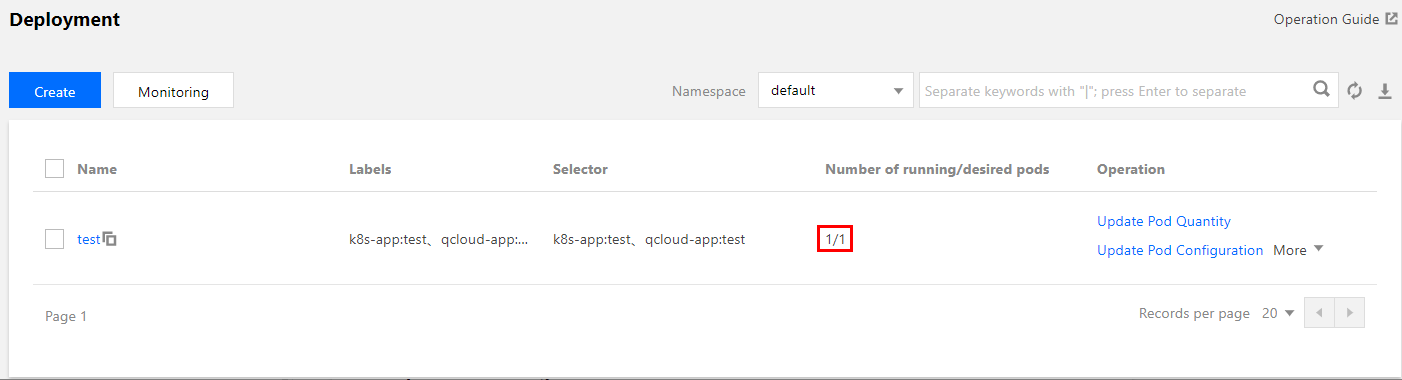
In the TKE console, create a Deployment-type workload. For more information, see Deployment Management. As an example, this document assumes that a Deployment-type workload named “hpa-test” with one replica and a service type of Web service is created, as shown below. Due to console iterations, the following figure may not be exactly the same as the actual display in the console. The actual console display prevails.
Configuring HPA
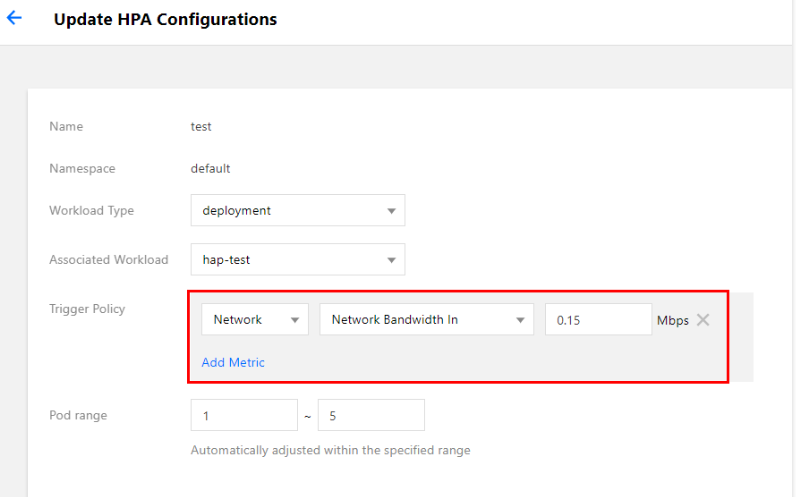
In the TKE Console, bind the test workload with an HPA configuration. For more information about how to bind an HPA configuration, see Directions. As an example, this document describes the configuration of a policy under which scale-out is triggered when the network egress bandwidth reaches 0.15 Mbps (150 Kbps), as shown below:
Function verification
Simulating the scale-out process
Run the following command to launch a temporary Pod in the cluster to test the configured HPA feature (simulated client):
kubectl run -it --image alpine hpa-test --restart=Never --rm /bin/sh
Run the following command in the temporary Pod to simulate a situation where large numbers of requests accessing the "hpa-test" service in a short period causes the egress traffic bandwidth to increase:
# hpa-test.default.svc.cluster.local is the domain name of the service in the cluster. To stop the script, press Ctrl+C.
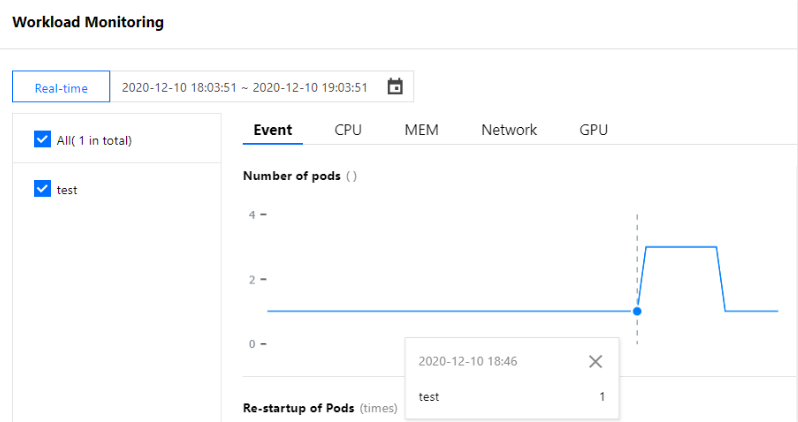
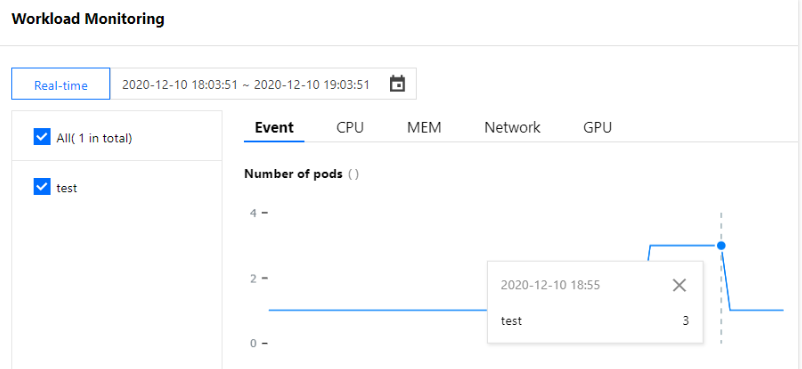
After running the request simulation command in the test Pod, observe the monitored number of Pods of the workload. You can find that scale-out is triggered because the number of Pod replicas increases to 2 at 16:21, as shown below. Due to console iterations, the following figure may not be exactly the same as the actual display in the console. The actual console display prevails.
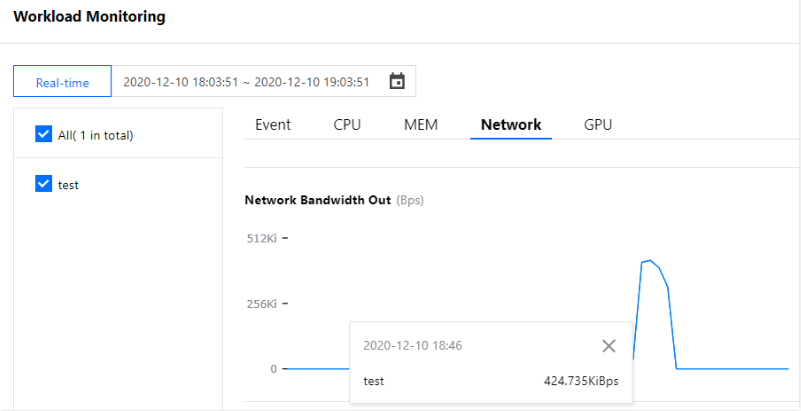
The triggering of the HPA scaling algorithm can also be proved by the fact that in the workload monitoring information, the network egress bandwidth increases to 196 Kbps at 16:21, as shown below. This bandwidth exceeds the set target egress bandwidth value of HPA, so another replica is created to meet the need. Due to console iterations, the following figure may not be exactly the same as the actual display in the console. The actual console display prevails.
Note
The HPA scaling algorithm does not just rely on formula calculation to control the scaling logic but takes multiple dimensions into consideration to decide whether scale-out or scale-in is needed. Therefore, the actual implementation may slightly differ from expectations. For more information, see Algorithm details.
Simulating the scale-in process
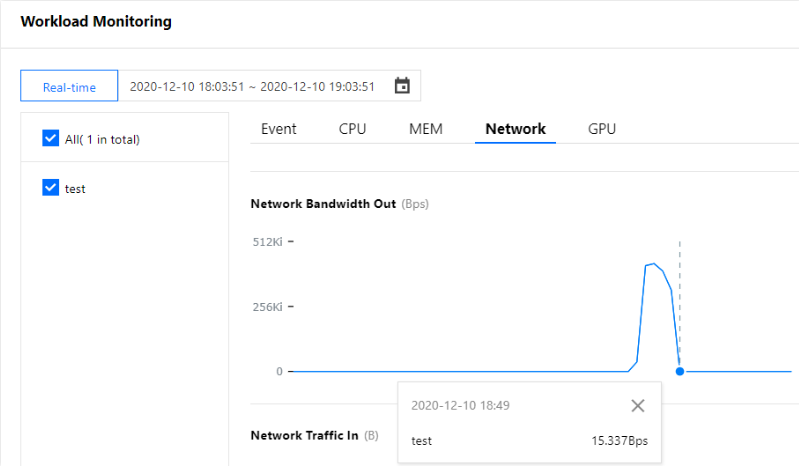
When simulating the scale-in process, manually stop executing the request simulation command at around 16:24. According to the HPA scaling algorithm, the workload scale-in condition is met. In the workload monitoring information, you can find that the network egress bandwidth decreases to the original level before the scale-out, as shown below:
However, scale-in is actually not triggered until 16:30. This is because there is a toleration time of five minutes by default after the triggering condition is met to prevent frequent scaling due to metric value fluctuations within a short time. For more information, see here. As shown below, the number of replicas decreases to 1 based on the HPA scaling algorithm five minutes after the command is stopped. Due to console iterations, the following figure may not be exactly the same as the actual display in the console. The actual console display prevails.
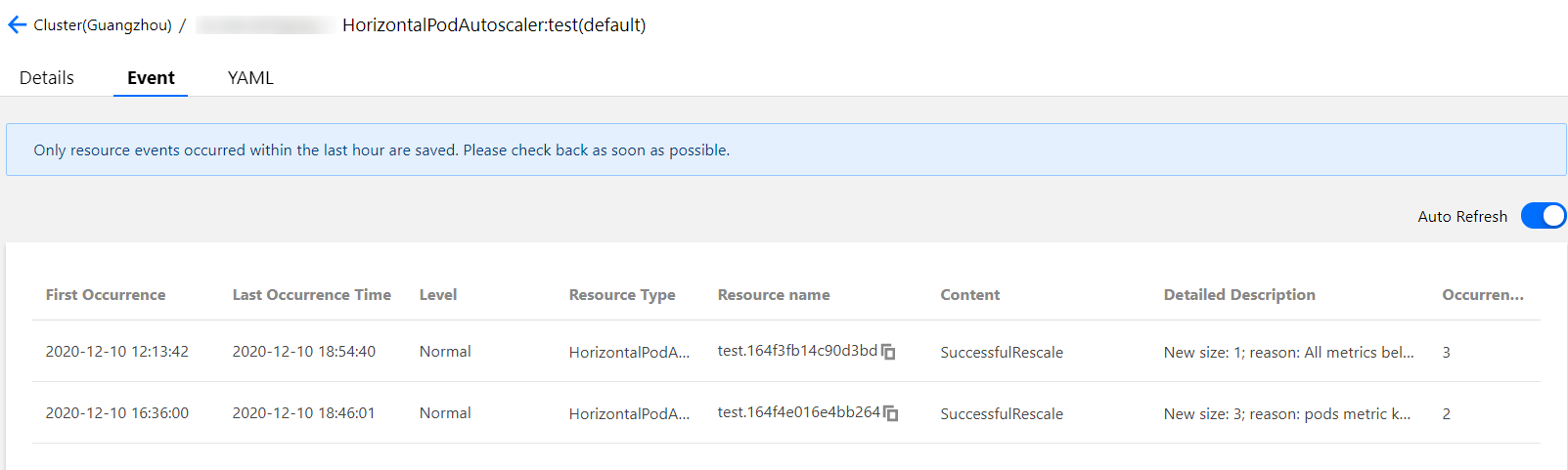
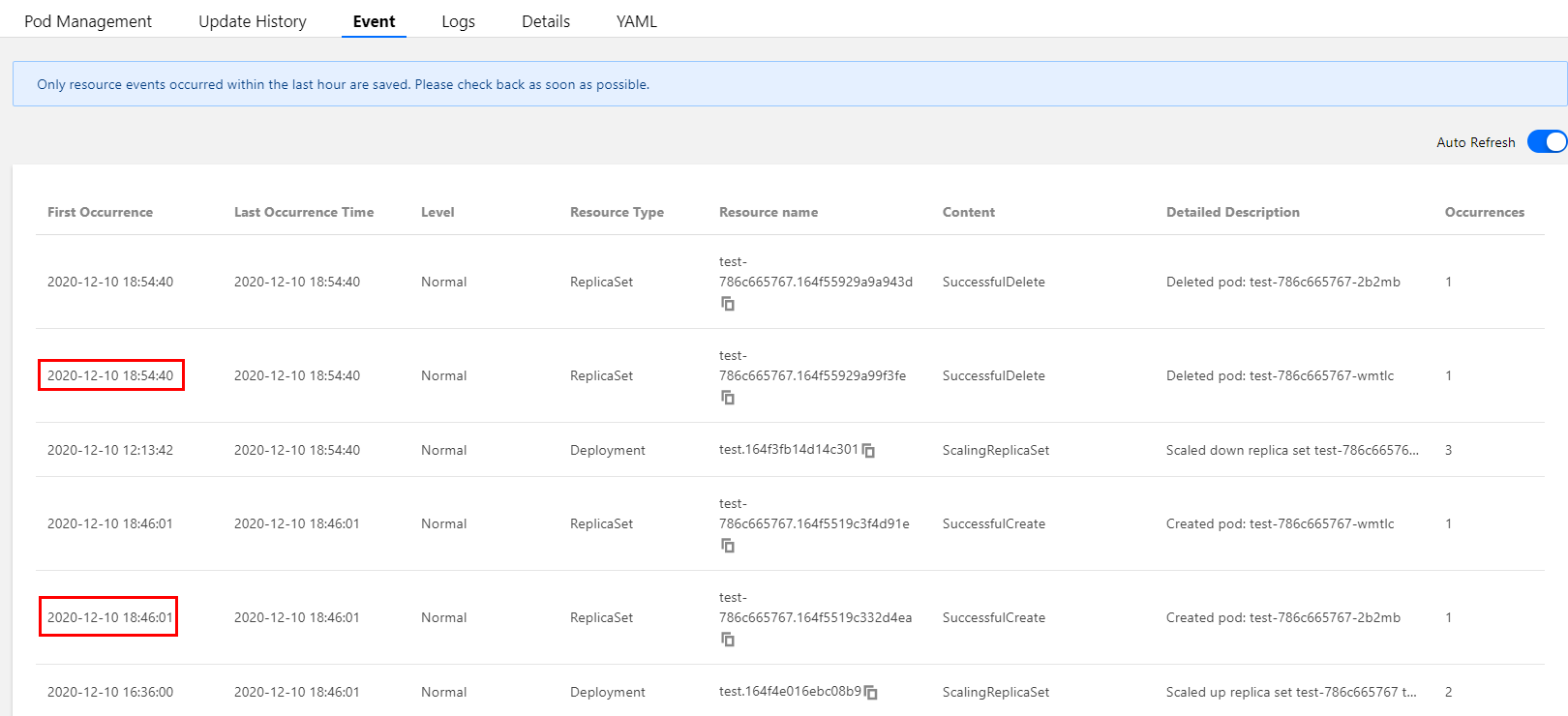
When an HPA scaling event occurs in TKE, the event will be displayed in the event list of the corresponding HPA instance. Note that the time fields on the event notification list include "First occurrence" and "Last occurrence". "First occurrence" indicates the first time when the same event occurred, while "Last occurrence" indicates the latest time when the same event occurred. Therefore, as you can see in the event list shown in the figure below, the "Last occurrence" field displays 16:21:03 for the scale-out event in our example and 16.29:42 for the scale-in event. The points in time displayed here match those in the workload monitoring, as shown below:
Besides, the workload event list also records the events of adding/deleting replicas by workloads when HPA occurs. As you can see in the figure below, the points in time of workload scale-out and scale-in match those displayed in the HPA event list. The point in time when the number of replicas increased is 16:21:03, and the point in time when the number of replicas decreased is 16:29:42.
Summary
This example demonstrates the HPA feature of TKE, describing how to use the TKE custom metric type of network egress bandwidth as the metric for triggering workload HPA scaling.
When the actual metric value of the workload exceeds the target metric value configured by HPA, HPA calculates the proper number of replicas according to its scale-out algorithm to implement scale-out. This ensures that the metric level of the workload meets expectations and that the workload can run healthily and steadily.
When the actual metric value of the workload is far lower than the target metric value configured by HPA, HPA waits until the toleration time expires, and then calculates the proper number of replicas to implement scale-in and release idle resources appropriately, thus achieving the objective of improving resource utilization. Moreover, during the whole process, relevant events are recorded in the HPA and workload event lists, so that the whole scaling process of the workload is traceable.

 Yes
Yes
 No
No
Was this page helpful?