固定 IP 相关特性
下载
聚焦模式
字号
固定 IP 的保留和回收
固定 IP 模式下,创建使用 VPC-CNI 模式的 Pod 以后,网络组件会为该 Pod 在同 namespace 下创建同名的 CRD 对象
VpcIPClaim。该对象描述 Pod 对 IP 的需求。网络组件随后会根据这个对象创建 CRD 对象 VpcIP,并关联对应的 VpcIPClaim。VpcIP 以实际的 IP 地址为名,表示实际的 IP 地址占用。您可以通过以下命令查看集群使用的容器子网内 IP 的使用情况:
kubectl get vip
对于非固定 IP 的 Pod,其 Pod 销毁后
VpcIPClaim 也会被销毁,VpcIP 随之销毁回收。而对于固定 IP 的 Pod,其 Pod 销毁后 VpcIPClaim 仍然保留,VpcIP 也因此保留。同名的 Pod 启动后会使用同名的 VpcIPClaim 关联的 VpcIP,从而实现 IP 地址保留。由于网络组件在集群范围内分配 IP 时会依据
VpcIP 信息找寻可用 IP,因此固定 IP 的地址若不使用需要及时回收(目前默认策略是永不回收),否则会导致 IP 浪费而无 IP 可用。本文介绍过期回收、手动回收及级联回收的 IP 回收方法。过期回收
在 创建集群 页面,容器网络插件选择 VPC-CNI 模式并且勾选开启支持固定 Pod IP 支持,如下图所示:

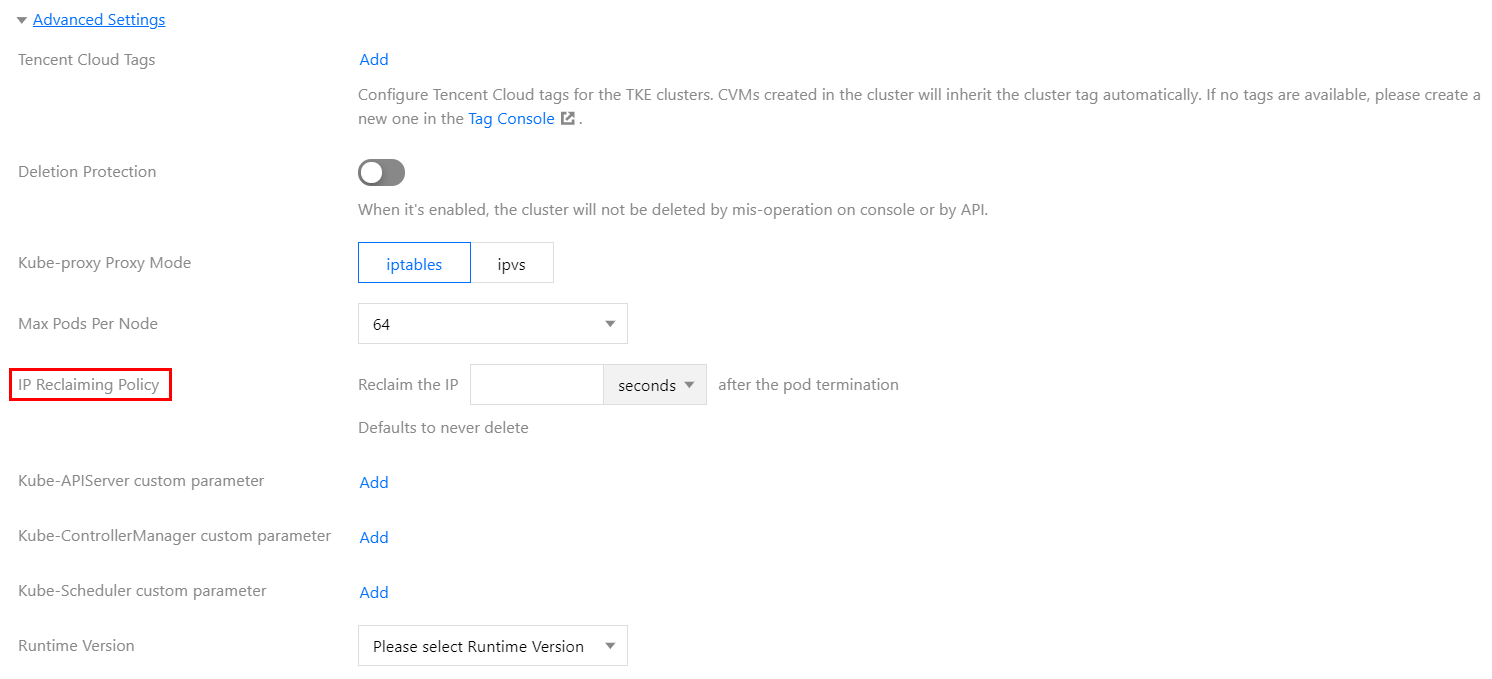
tke-eni-ipamd 组件版本 >= v3.5.0
1. 登录 容器服务控制台,单击左侧导航栏中集群。
2. 在集群管理页面,选择需设置过期时间的集群 ID,进入集群详情页。
3. 在集群详情页面,选择左侧组件管理。
4. 在组件管理页面中,找到 eniipamd 组件,选择更新配置。
5. 在更新配置页面,填写固定 IP 回收策略里的过期时间,并单击完成。
tke-eni-ipamd 组件版本 < v3.5.0 或组件管理中无 eniipamd 组件
修改现存的 tke-eni-ipamd deployment:
kubectl edit deploy tke-eni-ipamd -n kube-system。执行以下命令,在
spec.template.spec.containers[0].args 中加入/修改启动参数。- --claim-expired-duration=1h # 可填写不小于 5m 的任意值
手动回收
对于急需回收的 IP 地址,需要先确定需回收的 IP 被哪个 Pod 占用,找到对应的 Pod 的名称空间和名称,执行以下命令通过手动回收:
注意:
需保证回收的 IP 对应的 Pod 已经销毁,否则会导致该 Pod 网络不可用。
kubectl delete vipc <podname> -n <namespace>
级联回收
目前的固定 IP 与 Pod 强绑定,而与具体的 Workload 无关(例如 deployment、statefulset 等)。Pod 销毁后,固定 IP 不确定何时回收。TKE 现已实现删除 Pod 所属的 Workload 后即刻删除固定 IP。
以下步骤介绍如何开启级联回收:
tke-eni-ipamd 组件版本 >= v3.5.0
1. 登录 容器服务控制台,单击左侧导航栏中集群。
2. 在集群管理页面,选择需开启级联回收的集群 ID,进入集群详情页。
3. 在集群详情页面,选择左侧组件管理。
4. 在组件管理页面中,找到 eniipamd 组件,选择更新配置。
5. 在更新配置页面,勾选级联回收,并点击完成。
tke-eni-ipamd 组件版本 < v3.5.0 或组件管理中无 eniipamd 组件
1. 修改现存的 tke-eni-ipamd deployment:
kubectl edit deploy tke-eni-ipamd -n kube-system。2. 执行以下命令,在
spec.template.spec.containers[0].args 中加入启动参数:- --enable-ownerref
修改后,ipamd 会自动重启并生效。生效后,增量 Workload 可实现级联删除固定 IP,存量 Workload 暂不能支持。
相关问题
节点不能分配到弹性网卡,无法正常调度 Pod(共享网卡模式)
当节点加入到集群后,ipamd 会尝试从和节点相同可用区的子网(配置给 ipamd 的子网)中为节点绑定一个弹性网卡,如果 ipamd 异常或者没有给 ipamd 配置和节点相同可用区的子网,ipamd 将无法给节点分配辅助网卡。此外,如果当前 VPC 使用的辅助网卡数目超过上限,则无法给节点分配辅助网卡。
执行以下命令,确认问题原因:
kubectl get event
event 中显示 ENILimit,则是配额问题,可以通过为 VPC 调大弹性网卡数目配额来解决问题。
查看集群内节点所在可用区的容器子网 IP 是否充足,如已耗尽则补充同可用区容器子网可解决。
节点不能分配到弹性网卡,提示弹性网卡数量超出限制
现象
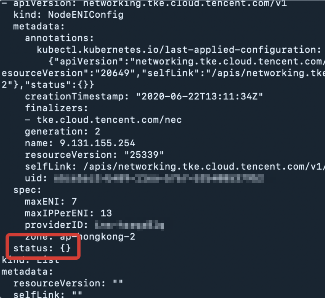
节点配置的弹性网卡无法绑定,nec 关联的 vip attach 失败。查看 nec 则看到节点关联的 nec status 为空。
执行以下代码可查看 nec:
kubectl get nec -o yaml
当节点关联的 nec status 为空时返回结果如下图所示:
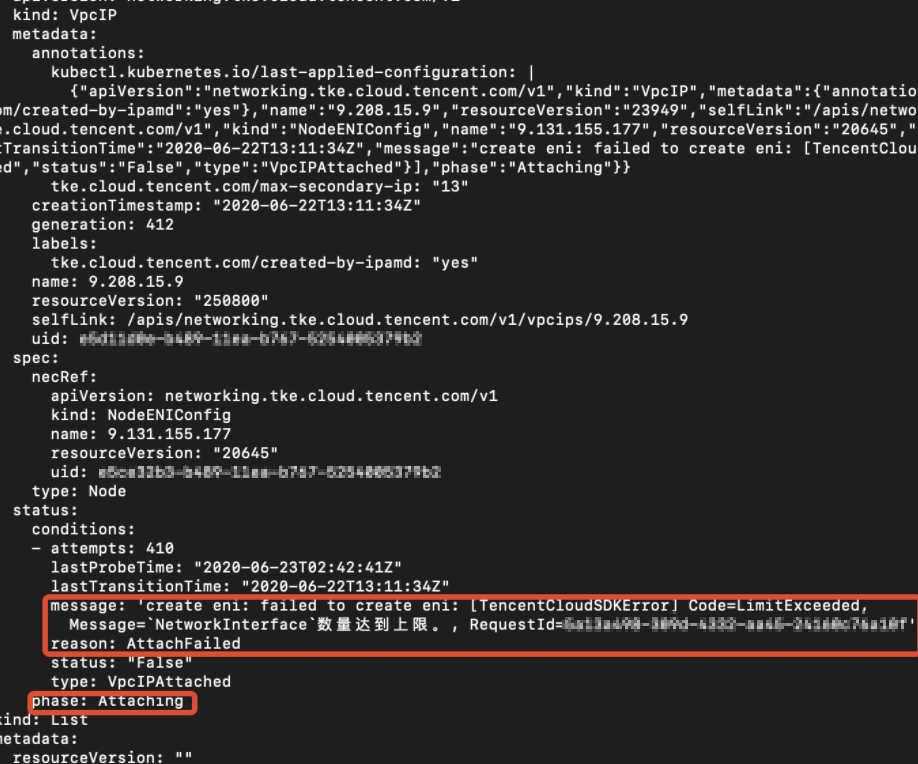
执行以下代码查看 nec 关联的 VIP:
kubectl get vip -oyaml
若命令返回成功则报错 VIP 状态为 Attaching,报错信息如下图所示:
解决方案
文档反馈