- Release Notes and Announcements
- Release Notes
- Announcements
- qGPU Service Adjustment
- Version Upgrade of Master Add-On of TKE Managed Cluster
- Upgrading tke-monitor-agent
- Discontinuing TKE API 2.0
- Instructions on Cluster Resource Quota Adjustment
- Discontinuing Kubernetes v1.14 and Earlier Versions
- Deactivation of Scaling Group Feature
- Notice on TPS Discontinuation on May 16, 2022 at 10:00 (UTC +8)
- Basic Monitoring Architecture Upgrade
- Starting Charging on Managed Clusters
- Instructions on Stopping Delivering the Kubeconfig File to Nodes
- Security Vulnerability Fix Description
- Release Notes
- Product Introduction
- Purchase Guide
- Quick Start
- TKE General Cluster Guide
- TKE General Cluster Overview
- Purchase a TKE General Cluster
- High-risk Operations of Container Service
- Deploying Containerized Applications in the Cloud
- Kubernetes API Operation Guide
- Open Source Components
- Permission Management
- Cluster Management
- Cluster Overview
- Cluster Hosting Modes Introduction
- Cluster Lifecycle
- Creating a Cluster
- Deleting a Cluster
- Cluster Scaling
- Changing the Cluster Operating System
- Connecting to a Cluster
- Upgrading a Cluster
- Enabling IPVS for a Cluster
- Enabling GPU Scheduling for a Cluster
- Custom Kubernetes Component Launch Parameters
- Using KMS for Kubernetes Data Source Encryption
- Images
- Worker node introduction
- Normal Node Management
- Native Node Management
- Overview
- Purchasing Native Nodes
- Lifecycle of a Native Node
- Native Node Parameters
- Creating Native Nodes
- Deleting Native Nodes
- Self-Heal Rules
- Declarative Operation Practice
- Native Node Scaling
- In-place Pod Configuration Adjustment
- Enabling SSH Key Login for a Native Node
- Management Parameters
- Enabling Public Network Access for a Native Node
- Supernode management
- Registered Node Management
- GPU Share
- Kubernetes Object Management
- Overview
- Namespace
- Workload
- Deployment Management
- StatefulSet Management
- DaemonSet Management
- Job Management
- CronJob Management
- Setting the Resource Limit of Workload
- Setting the Scheduling Rule for a Workload
- Setting the Health Check for a Workload
- Setting the Run Command and Parameter for a Workload
- Using a Container Image in a TCR Enterprise Instance to Create a Workload
- Auto Scaling
- Configuration
- Register node management
- Service Management
- Ingress Management
- Storage Management
- Application and Add-On Feature Management Description
- Add-On Management
- Add-on Overview
- Add-On Lifecycle Management
- CBS-CSI Description
- UserGroupAccessControl
- COS-CSI
- CFS-CSI
- P2P
- OOMGuard
- TCR Introduction
- TCR Hosts Updater
- DNSAutoscaler
- NodeProblemDetectorPlus Add-on
- NodeLocalDNSCache
- Network Policy
- DynamicScheduler
- DeScheduler
- Nginx-ingress
- HPC
- Description of tke-monitor-agent
- GPU-Manager Add-on
- CFSTURBO-CSI
- tke-log-agent
- Helm Application
- Application Market
- Network Management
- Container Network Overview
- GlobalRouter Mode
- VPC-CNI Mode
- VPC-CNI Mode
- Multiple Pods with Shared ENI Mode
- Pods with Exclusive ENI Mode
- Static IP Address Mode Instructions
- Non-static IP Address Mode Instructions
- Interconnection Between VPC-CNI and Other Cloud Resources/IDC Resources
- Security Group of VPC-CNI Mode
- Instructions on Binding an EIP to a Pod
- VPC-CNI Component Description
- Limits on the Number of Pods in VPC-CNI Mode
- Cilium-Overlay Mode
- OPS Center
- Log Management
- Backup Center
- Cloud Native Monitoring
- Remote Terminals
- TKE Serverless Cluster Guide
- TKE Edge Cluster Guide
- TKE Registered Cluster Guide
- TKE Container Instance Guide
- Cloud Native Service Guide
- Best Practices
- Cluster
- Cluster Migration
- Serverless Cluster
- Edge Cluster
- Security
- Service Deployment
- Hybrid Cloud
- Network
- DNS
- Using Network Policy for Network Access Control
- Deploying NGINX Ingress on TKE
- Nginx Ingress High-Concurrency Practices
- Nginx Ingress Best Practices
- Limiting the bandwidth on pods in TKE
- Directly connecting TKE to the CLB of pods based on the ENI
- Use CLB-Pod Direct Connection on TKE
- Obtaining the Real Client Source IP in TKE
- Using Traefik Ingress in TKE
- Release
- Logs
- Monitoring
- OPS
- Removing and Re-adding Nodes from and to Cluster
- Using Ansible to Batch Operate TKE Nodes
- Using Cluster Audit for Troubleshooting
- Renewing a TKE Ingress Certificate
- Using cert-manager to Issue Free Certificates
- Using cert-manager to Issue Free Certificate for DNSPod Domain Name
- Using the TKE NPDPlus Plug-In to Enhance the Self-Healing Capability of Nodes
- Using kubecm to Manage Multiple Clusters kubeconfig
- Quick Troubleshooting Using TKE Audit and Event Services
- Customizing RBAC Authorization in TKE
- Clearing De-registered Tencent Cloud Account Resources
- Terraform
- DevOps
- Auto Scaling
- Cluster Auto Scaling Practices
- Using tke-autoscaling-placeholder to Implement Auto Scaling in Seconds
- Installing metrics-server on TKE
- Using Custom Metrics for Auto Scaling in TKE
- Utilizing HPA to Auto Scale Businesses on TKE
- Using VPA to Realize Pod Scaling up and Scaling down in TKE
- Adjusting HPA Scaling Sensitivity Based on Different Business Scenarios
- Storage
- Containerization
- Microservice
- Cost Management
- Fault Handling
- Disk Full
- High Workload
- Memory Fragmentation
- Cluster DNS Troubleshooting
- Cluster kube-proxy Troubleshooting
- Cluster API Server Inaccessibility Troubleshooting
- Service and Ingress Inaccessibility Troubleshooting
- Troubleshooting for Pod Network Inaccessibility
- Pod Status Exception and Handling
- Authorizing Tencent Cloud OPS Team for Troubleshooting
- Engel Ingres appears in Connechtin Reverside
- CLB Loopback
- CLB Ingress Creation Error
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Cluster APIs
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateCluster
- UpdateClusterVersion
- UpdateClusterKubeconfig
- DescribeBackupStorageLocations
- DeleteBackupStorageLocation
- CreateBackupStorageLocation
- Add-on APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- DescribeTKEEdgeScript
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeClusters
- DescribeTKEEdgeClusterStatus
- DescribeTKEEdgeClusterCredential
- DescribeEdgeClusterInstances
- DescribeEdgeCVMInstances
- DescribeECMInstances
- DescribeAvailableTKEEdgeVersion
- DeleteTKEEdgeCluster
- DeleteEdgeClusterInstances
- DeleteEdgeCVMInstances
- DeleteECMInstances
- CreateTKEEdgeCluster
- CreateECMInstances
- CheckEdgeClusterCIDR
- ForwardTKEEdgeApplicationRequestV3
- UninstallEdgeLogAgent
- InstallEdgeLogAgent
- DescribeEdgeLogSwitches
- CreateEdgeLogConfig
- CreateEdgeCVMInstances
- UpdateEdgeClusterVersion
- DescribeEdgeClusterUpgradeInfo
- Cloud Native Monitoring APIs
- Virtual node APIs
- Other APIs
- Scaling group APIs
- Data Types
- Error Codes
- API Mapping Guide
- TKE Insight
- TKE Scheduling
- FAQs
- Service Agreement
- Contact Us
- Purchase Channels
- Glossary
- User Guide(Old)
- Release Notes and Announcements
- Release Notes
- Announcements
- qGPU Service Adjustment
- Version Upgrade of Master Add-On of TKE Managed Cluster
- Upgrading tke-monitor-agent
- Discontinuing TKE API 2.0
- Instructions on Cluster Resource Quota Adjustment
- Discontinuing Kubernetes v1.14 and Earlier Versions
- Deactivation of Scaling Group Feature
- Notice on TPS Discontinuation on May 16, 2022 at 10:00 (UTC +8)
- Basic Monitoring Architecture Upgrade
- Starting Charging on Managed Clusters
- Instructions on Stopping Delivering the Kubeconfig File to Nodes
- Security Vulnerability Fix Description
- Release Notes
- Product Introduction
- Purchase Guide
- Quick Start
- TKE General Cluster Guide
- TKE General Cluster Overview
- Purchase a TKE General Cluster
- High-risk Operations of Container Service
- Deploying Containerized Applications in the Cloud
- Kubernetes API Operation Guide
- Open Source Components
- Permission Management
- Cluster Management
- Cluster Overview
- Cluster Hosting Modes Introduction
- Cluster Lifecycle
- Creating a Cluster
- Deleting a Cluster
- Cluster Scaling
- Changing the Cluster Operating System
- Connecting to a Cluster
- Upgrading a Cluster
- Enabling IPVS for a Cluster
- Enabling GPU Scheduling for a Cluster
- Custom Kubernetes Component Launch Parameters
- Using KMS for Kubernetes Data Source Encryption
- Images
- Worker node introduction
- Normal Node Management
- Native Node Management
- Overview
- Purchasing Native Nodes
- Lifecycle of a Native Node
- Native Node Parameters
- Creating Native Nodes
- Deleting Native Nodes
- Self-Heal Rules
- Declarative Operation Practice
- Native Node Scaling
- In-place Pod Configuration Adjustment
- Enabling SSH Key Login for a Native Node
- Management Parameters
- Enabling Public Network Access for a Native Node
- Supernode management
- Registered Node Management
- GPU Share
- Kubernetes Object Management
- Overview
- Namespace
- Workload
- Deployment Management
- StatefulSet Management
- DaemonSet Management
- Job Management
- CronJob Management
- Setting the Resource Limit of Workload
- Setting the Scheduling Rule for a Workload
- Setting the Health Check for a Workload
- Setting the Run Command and Parameter for a Workload
- Using a Container Image in a TCR Enterprise Instance to Create a Workload
- Auto Scaling
- Configuration
- Register node management
- Service Management
- Ingress Management
- Storage Management
- Application and Add-On Feature Management Description
- Add-On Management
- Add-on Overview
- Add-On Lifecycle Management
- CBS-CSI Description
- UserGroupAccessControl
- COS-CSI
- CFS-CSI
- P2P
- OOMGuard
- TCR Introduction
- TCR Hosts Updater
- DNSAutoscaler
- NodeProblemDetectorPlus Add-on
- NodeLocalDNSCache
- Network Policy
- DynamicScheduler
- DeScheduler
- Nginx-ingress
- HPC
- Description of tke-monitor-agent
- GPU-Manager Add-on
- CFSTURBO-CSI
- tke-log-agent
- Helm Application
- Application Market
- Network Management
- Container Network Overview
- GlobalRouter Mode
- VPC-CNI Mode
- VPC-CNI Mode
- Multiple Pods with Shared ENI Mode
- Pods with Exclusive ENI Mode
- Static IP Address Mode Instructions
- Non-static IP Address Mode Instructions
- Interconnection Between VPC-CNI and Other Cloud Resources/IDC Resources
- Security Group of VPC-CNI Mode
- Instructions on Binding an EIP to a Pod
- VPC-CNI Component Description
- Limits on the Number of Pods in VPC-CNI Mode
- Cilium-Overlay Mode
- OPS Center
- Log Management
- Backup Center
- Cloud Native Monitoring
- Remote Terminals
- TKE Serverless Cluster Guide
- TKE Edge Cluster Guide
- TKE Registered Cluster Guide
- TKE Container Instance Guide
- Cloud Native Service Guide
- Best Practices
- Cluster
- Cluster Migration
- Serverless Cluster
- Edge Cluster
- Security
- Service Deployment
- Hybrid Cloud
- Network
- DNS
- Using Network Policy for Network Access Control
- Deploying NGINX Ingress on TKE
- Nginx Ingress High-Concurrency Practices
- Nginx Ingress Best Practices
- Limiting the bandwidth on pods in TKE
- Directly connecting TKE to the CLB of pods based on the ENI
- Use CLB-Pod Direct Connection on TKE
- Obtaining the Real Client Source IP in TKE
- Using Traefik Ingress in TKE
- Release
- Logs
- Monitoring
- OPS
- Removing and Re-adding Nodes from and to Cluster
- Using Ansible to Batch Operate TKE Nodes
- Using Cluster Audit for Troubleshooting
- Renewing a TKE Ingress Certificate
- Using cert-manager to Issue Free Certificates
- Using cert-manager to Issue Free Certificate for DNSPod Domain Name
- Using the TKE NPDPlus Plug-In to Enhance the Self-Healing Capability of Nodes
- Using kubecm to Manage Multiple Clusters kubeconfig
- Quick Troubleshooting Using TKE Audit and Event Services
- Customizing RBAC Authorization in TKE
- Clearing De-registered Tencent Cloud Account Resources
- Terraform
- DevOps
- Auto Scaling
- Cluster Auto Scaling Practices
- Using tke-autoscaling-placeholder to Implement Auto Scaling in Seconds
- Installing metrics-server on TKE
- Using Custom Metrics for Auto Scaling in TKE
- Utilizing HPA to Auto Scale Businesses on TKE
- Using VPA to Realize Pod Scaling up and Scaling down in TKE
- Adjusting HPA Scaling Sensitivity Based on Different Business Scenarios
- Storage
- Containerization
- Microservice
- Cost Management
- Fault Handling
- Disk Full
- High Workload
- Memory Fragmentation
- Cluster DNS Troubleshooting
- Cluster kube-proxy Troubleshooting
- Cluster API Server Inaccessibility Troubleshooting
- Service and Ingress Inaccessibility Troubleshooting
- Troubleshooting for Pod Network Inaccessibility
- Pod Status Exception and Handling
- Authorizing Tencent Cloud OPS Team for Troubleshooting
- Engel Ingres appears in Connechtin Reverside
- CLB Loopback
- CLB Ingress Creation Error
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Cluster APIs
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateCluster
- UpdateClusterVersion
- UpdateClusterKubeconfig
- DescribeBackupStorageLocations
- DeleteBackupStorageLocation
- CreateBackupStorageLocation
- Add-on APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- DescribeTKEEdgeScript
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeClusters
- DescribeTKEEdgeClusterStatus
- DescribeTKEEdgeClusterCredential
- DescribeEdgeClusterInstances
- DescribeEdgeCVMInstances
- DescribeECMInstances
- DescribeAvailableTKEEdgeVersion
- DeleteTKEEdgeCluster
- DeleteEdgeClusterInstances
- DeleteEdgeCVMInstances
- DeleteECMInstances
- CreateTKEEdgeCluster
- CreateECMInstances
- CheckEdgeClusterCIDR
- ForwardTKEEdgeApplicationRequestV3
- UninstallEdgeLogAgent
- InstallEdgeLogAgent
- DescribeEdgeLogSwitches
- CreateEdgeLogConfig
- CreateEdgeCVMInstances
- UpdateEdgeClusterVersion
- DescribeEdgeClusterUpgradeInfo
- Cloud Native Monitoring APIs
- Virtual node APIs
- Other APIs
- Scaling group APIs
- Data Types
- Error Codes
- API Mapping Guide
- TKE Insight
- TKE Scheduling
- FAQs
- Service Agreement
- Contact Us
- Purchase Channels
- Glossary
- User Guide(Old)
Migrating Self-built Prometheus to Cloud Native Monitoring
Last updated: 2022-04-18 16:58:49
Overview
Compatible with the APIs of Prometheus and Grafana and the CRD usage of mainstream prometheus-operator, TKE Cloud Native Monitoring is more flexible and extensible. Combined with Prometheus open source tools, it can have more advanced usages.
This document describes how to use auxiliary scripts and migration tools to quickly migrate the self-built Prometheus to cloud native monitoring.
Prerequisites
You have installed Kubectl on the node of the self-built Prometheus cluster and configured Kubeconfig to ensure that you can manage the cluster through Kubectl.
Directions
Migrating the Dynamic Collection Configuration
If the prometheus-operator is used in self-built Prometheus, CRD resources such as ServiceMonitor and PodMonitor are usually used to dynamically add collection configurations. This method also applies to cloud native monitoring. If you only need to migrate the prometheus-operator of the self-built Prometheus cluster to cloud native monitoring, and without migrating the cluster, then there is no need to migrate the dynamic configuration. You only need to use the cloud native monitoring to associate the self-built cluster, and then the ServiceMonitor and PodMonitor resources created by the self-built Prometheus will automatically take effect in cloud native monitoring.
For cross-cluster migration, you can export the CRD resources of self-built Prometheus and selectively reapply them in the associated cloud native monitoring cluster. The following describes how to export ServiceMonitor and PodMonitor in batches in a self-built Prometheus cluster.
Create the script
prom-backup.shwith the following contents:_ns_list=$(kubectl get ns | awk '{print $1}' | grep -v NAME) count=0 declare -a types=("servicemonitors.monitoring.coreos.com" "podmonitors.monitoring.coreos.com") for _ns in ${_ns_list}; do ## loop for types for _type in "${types[@]}"; do echo "Backup type [namespace: ${_ns}, type: ${_type}]." _item_list=$(kubectl -n ${_ns} get ${_type} | grep -v NAME | awk '{print $1}' ) ## loop for items for _item in ${_item_list}; do _file_name=./${_ns}_${_type}_${_item}.yaml echo "Backup kubernetes config yaml [namespace: ${_ns}, type: ${_type}, item: ${_item}] to file: ${_file_name}" kubectl -n ${_ns} get ${_type} ${_item} -o yaml > ${_file_name} count=$[count + 1] echo "Backup No.${count} file done." done; done; done;Run the following command to run the
prom-backup.shscript.bash prom-backup.shThe
prom-backup.shscript will export each ServiceMonitor and PodMonitor resource into a separate YAML file. You can run thelscommand to view the output file list. The example is as follows:$ ls kube-system_servicemonitors.monitoring.coreos.com_kube-state-metrics.yaml kube-system_servicemonitors.monitoring.coreos.com_node-exporter.yaml monitoring_servicemonitors.monitoring.coreos.com_coredns.yaml monitoring_servicemonitors.monitoring.coreos.com_grafana.yaml monitoring_servicemonitors.monitoring.coreos.com_kube-apiserver.yaml monitoring_servicemonitors.monitoring.coreos.com_kube-controller-manager.yaml monitoring_servicemonitors.monitoring.coreos.com_kube-scheduler.yaml monitoring_servicemonitors.monitoring.coreos.com_kube-state-metrics.yaml monitoring_servicemonitors.monitoring.coreos.com_kubelet.yaml monitoring_servicemonitors.monitoring.coreos.com_node-exporter.yamlYou can filter, modify and reapply the YAML file to the associated cloud native monitoring cluster (do not apply the collection rules that already exist or have the same feature). The cloud native monitoring will automatically perceive these dynamic collection rules and perform collection.
Note:If you need to add ServiceMonitor or PodMonitor, you can add it visually on the TKE console, or you can directly create it with YAML. The usage is fully compatible with the CRD of the Prometheus community.
Migrating the static collection configuration
If the self-built Prometheus system directly uses the Prometheus native configuration file, you can convert it into a RawJob of cloud native monitoring with a few steps on the TKE console, making it compatible with the scrape_configs configuration item of the Prometheus native configuration file.
- Log in to the TKE console.
- Click Cloud Native Monitoring in the left sidebar to go to the Cloud Native Monitoring page.
- Click the instance ID/name to configure to go to its basic information page.
- Select Associate with Cluster tab, select the cluster to configure, and click Data Collection under the Operation column.
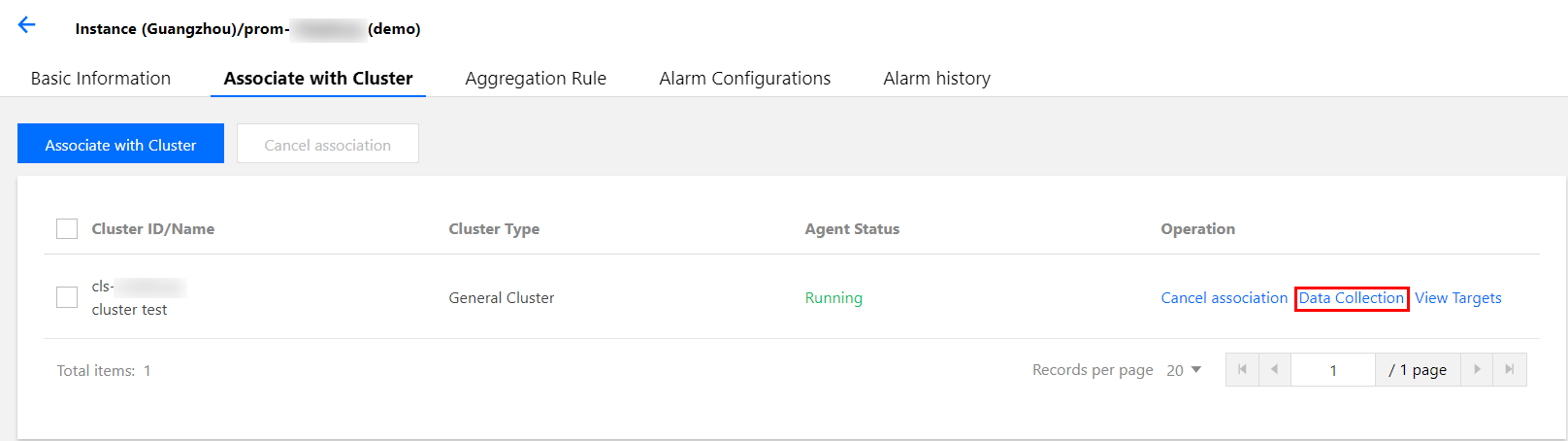
- Select RawJob > Add. Copy and paste the Job configuration from the native Prometheus configuration file into this configuration window.
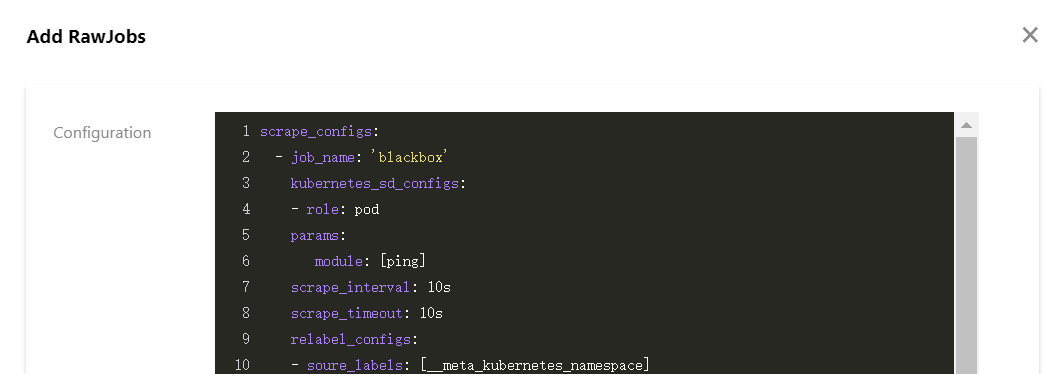
- You can paste all the Job arrays that need to import into the cloud native monitoring, and click Confirm. The Job arrays will be automatically split into multiple RawJobs and named as the
job_namefield of each Job.
Migrating the global configuration
You can modify the Prometheus CRD resource of cloud native monitoring to modify the global configuration.
Run the following command to obtain the Prometheus information.
$ kubectl get ns prom-fnc7bvu9 Active 13m $ kubectl -n prom-fnc7bvu9 get prometheus NAME VERSION REPLICAS AGE tke-cls-hha93bp9 11m $ kubectl -n prom-fnc7bvu9 edit prometheus tke-cls-hha93bp9Run the following command to modify the Prometheus configuration.
$ kubectl -n prom-fnc7bvu9 edit prometheus tke-cls-hha93bp9Modify the following parameters in the pop-up window:
- scrapeInterval: the collection capture interval (default value is 15 seconds)
- externalLabels: add the default label tag for all time series data.
Migrating the aggregation configuration
The format of each Prometheus aggregation configuration rule is the same no matter it is the original static configuration Recording rules or the dynamic configuration PrometheusRule.
- Log in to the TKE console.
- Click Cloud Native Monitoring in the left sidebar to go to the Cloud Native Monitoring page.
- Click the instance ID/name to configure to go to its basic information page.
- Select Aggregation Rule > Create Aggregation Rule. In the Add Aggregation Rule window, paste each rule into the groups array in the PrometheusRule format, as shown in the figure below:
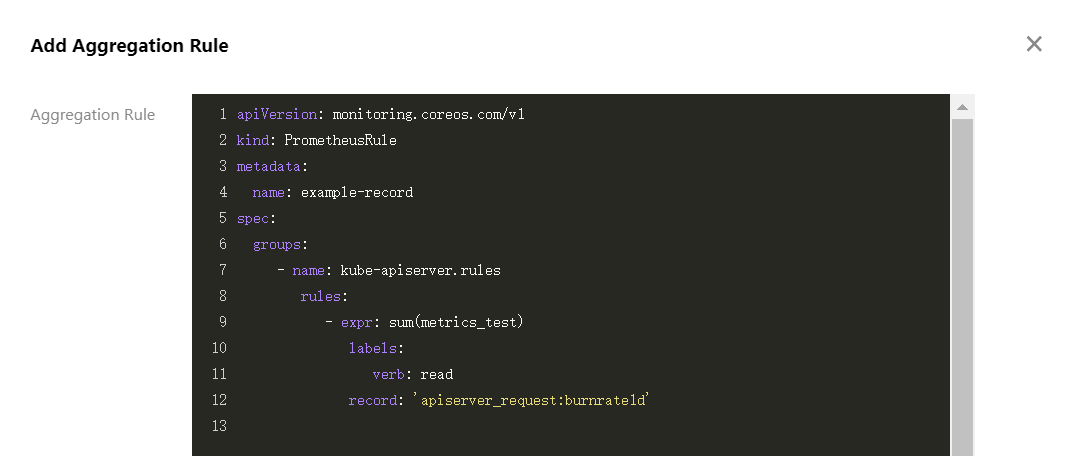 Note:
Note:If the self-built Prometheus uses the aggregation rules defined by PrometheusRule, it is recommended to migrate them according to the above steps. If the PrometheusRule resource is created directly in the cluster using YAML, it cannot be displayed in cloud native monitoring on the console currently.
Migrating the alarm configuration
This document provides the self-built Prometheus Alarm original configuration YAML file as an example to describe how to convert it into a monitoring configuration similar to cloud native monitoring.
- alert: NodeNotReady
expr: kube_node_status_condition{condition="Ready",status="true"} == 0
for: 5m
labels:
severity: critical
annotations:
description: node {{ $labels.node }} is not available for a long time (cluster id {{ $labels.cluster }})
- Log in to the TKE console.
- Click Cloud Native Monitoring in the left sidebar to go to the Cloud Native Monitoring page.
- Click the instance ID/name to configure to go to its basic information page.
- Select Alarm Configurations > Create Alarm Policy to configure the alarm policy.
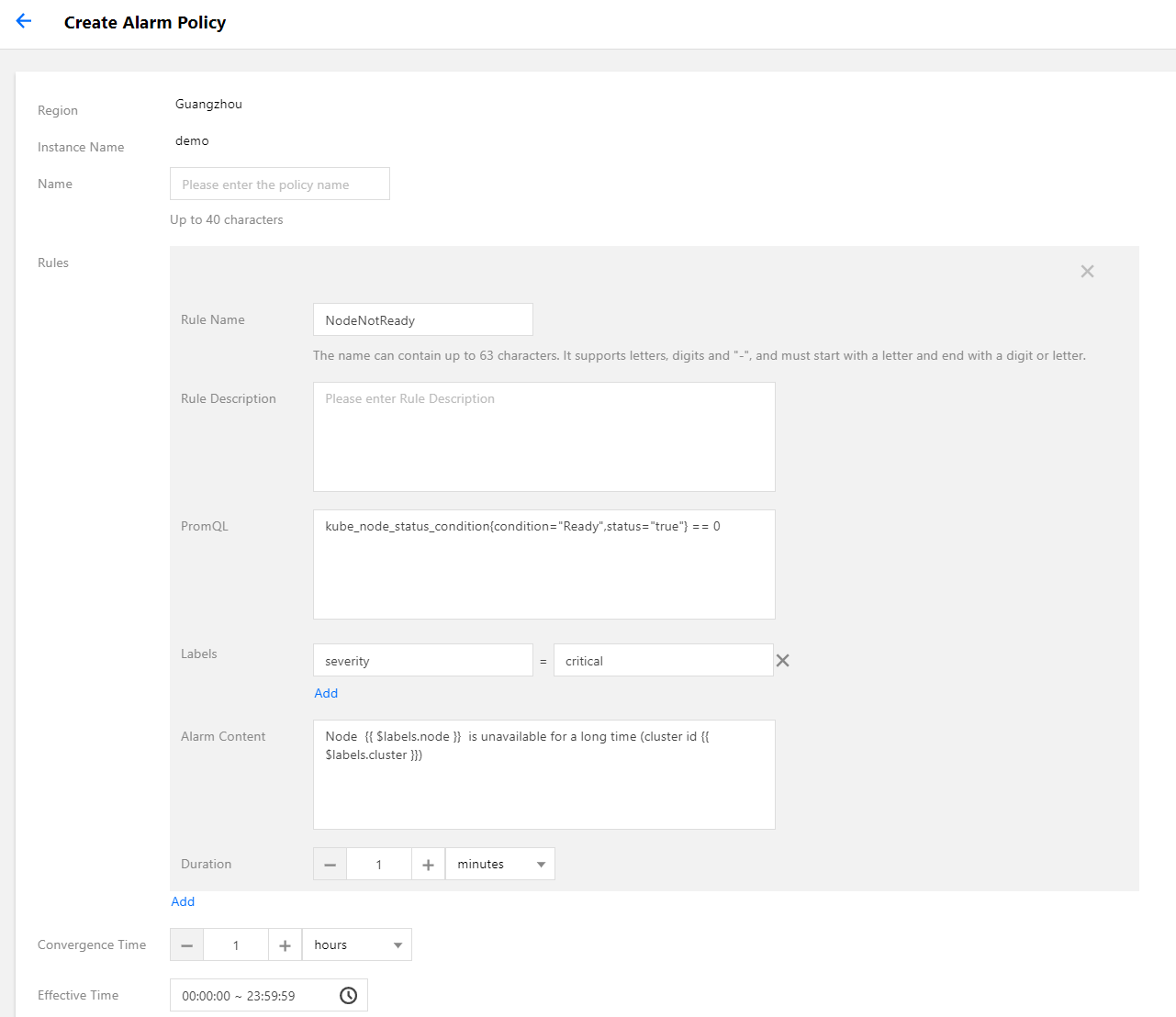
Main parameters are described as follows:- PromQL: the core configuration of the alarm and is the PromQL expression used to indicate the alarm trigger condition, which is equivalent to the “expr” field of the original configuration.
- Labels: an extra label added for the alarm, which is equivalent to the labels field of the original configuration.
- Alarm Content: the pushed alarm content. You can use a template or a template with variables. It is recommended to add the cluster ID in the alarm content. You can use the variable
{{ $labels.cluster }}to represent the cluster ID. - Duration: indicates an alarm will be pushed when the alarm is not restored after the alarm condition is met for how long. It is equivalent to the “for” field of the original configuration. The configuration in the following sample is 5 minutes.
- Convergence Time: indicates an alarm will be pushed again when the alarm is not restored after the alarm condition is met for how long, that is, the push interval between the same alarms. It is equivalent to the repeat_interval configuration of AlertManager. The configuration in the following sample is 1 hour.
Note:
The above alarm configuration example shows that after the node status changes to NotReady, the alarm will be pushed if it is not restored within 5 minutes. If it has not restored for a long time, the alarm will be pushed again at an interval of 1 hour.
- Configure the alarm channel. Currently, only Tencent Cloud and WebHook are available.
The alarm channels of Tencent Cloud support SMS, Email, WeChat and Mobile. You can select as needed.


Migrating the Grafana dashboard
The self-built Prometheus is usually configured with many custom Grafana monitoring dashboards. If you need to migrate a large number of dashboards to other platforms, it is too inefficient to export and import one by one. You can use the grafana-backup tool to export and import Grafana dashboards in batches. For details, please refer to the following directions.
Run the following command to install grafana-backup, as shown below:
pip3 install grafana-backupNote:It is recommended to use Python3 to avoid the compatibility problems.
Create API Keys.
- Enter the configuration page of self-buit Grafana and cloud native monitoring Grafana respectively. Select API Keys > New API Key, as shown below:
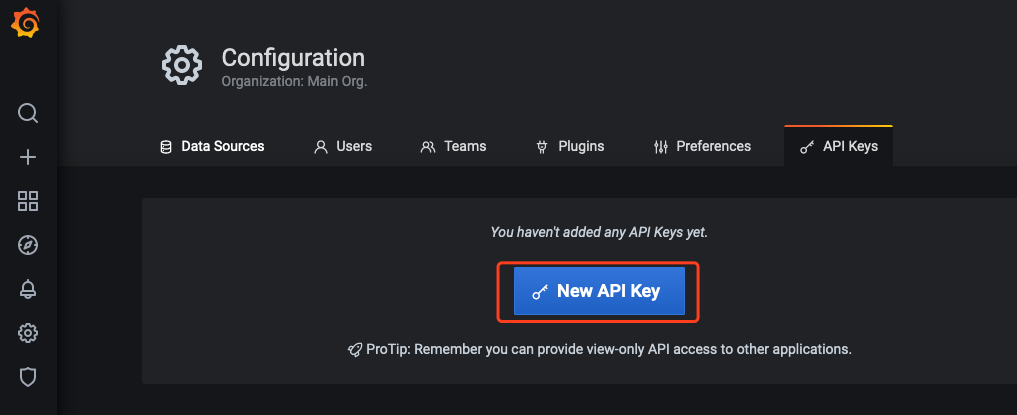
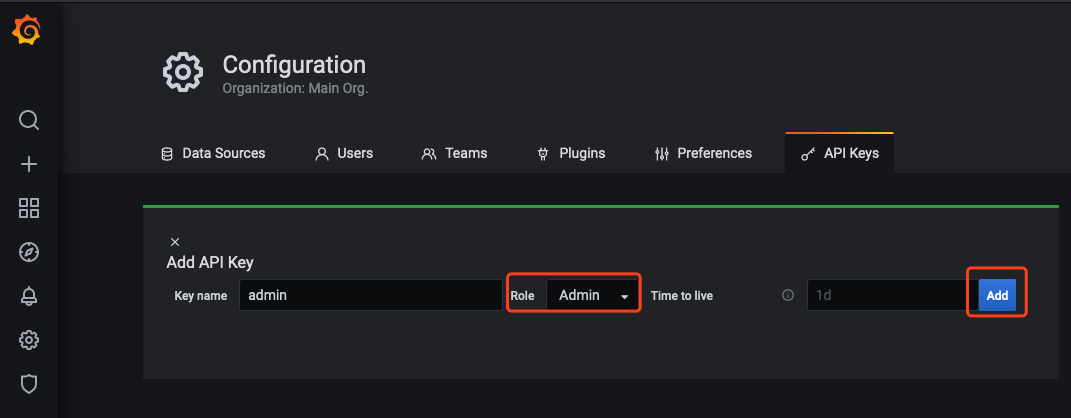
- In Add API Key window, create an API KEY whose role is Admin, as shown below:
- Enter the configuration page of self-buit Grafana and cloud native monitoring Grafana respectively. Select API Keys > New API Key, as shown below:
Back up the configuration file of the dashboard that you want to export.
Run the following command to obtain the access address of the self-built Grafana, as shown below:
$ kubectl -n monitoring get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE grafana ClusterIP 172.21.254.127 <none> 3000/TCP 25hNote:Take the Grafana access address
http://172.21.254.127:3000in the cluster as an example.Run the following command to generate the grafana-backup configuration file (with Grafana address and APIKey) as shown below:
export TOKEN=<TOKEN> cat > ~/.grafana-backup.json <<EOF { "general": { "debug": true, "backup_dir": "_OUTPUT_" }, "grafana": { "url": "http://172.21.254.127:3000", "token": "${TOKEN}" } } EOFNote:You need to replace <TOKEN> with the APIKey of self-built Grafana, and replace the URL with the actual environment address.
Run the following command to export all dashboards, as shown below:
grafana-backup saveThe dashboard will be saved as a compressed file in the
_OUTPUT_directory. You can run the following command to view the files in this directory, as shown below:$ tree _OUTPUT_ _OUTPUT_ └── 202012151049.tar.gz 0 directories, 1 fileRun the following command to restore the configuration file, as shown below:
export TOKEN=<TOKEN> cat > ~/.grafana-backup.json <<EOF { "general": { "debug": true, "backup_dir": "_OUTPUT_" }, "grafana": { "url": "http://prom-xxxxxx-grafana.ccs.tencent-cloud.com", "token": "${TOKEN}" } } EOFNote:You need to replace <TOKEN> with the APIKey of cloud native monitoring Grafana, and replace the URL with the access address of cloud native monitoring Grafana. (The internet access need to be enabled).
Run the following command to import the exported dashboards to the cloud native monitoring Grafana with one click, as shown below:
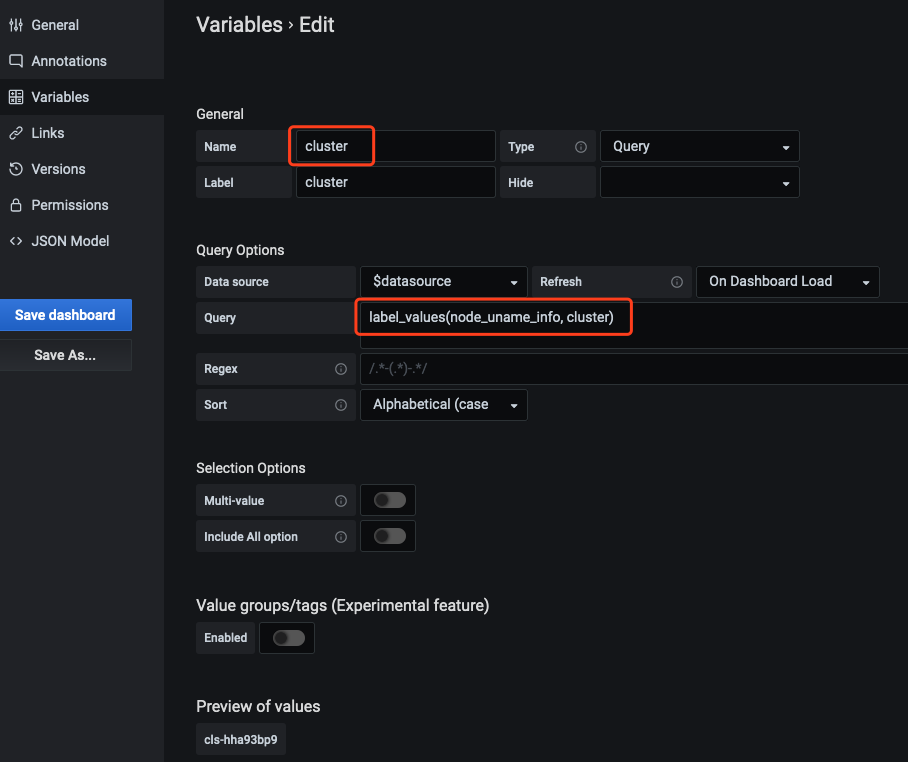
grafana-backup restore _OUTPUT_/202012151049.tar.gzIn Grafana configuration dashboard, select Dashboard settings > Variables > New to create the cluster field. It is recommended to add the filter field “cluster” for all dashboards. Cloud native monitoring supports multiple clusters. It will add the label “cluster” to the data of each cluster, and use the cluster ID to distinguish different clusters, as shown below:
 Note:
Note:Enter an arbitrary metric name that is involved in the current dashboard in label_values (The example is node_uname_info).
Modify the query statements of PromQL in all dashboards and add the filter conditions
cluster=~"$cluster", as shown below: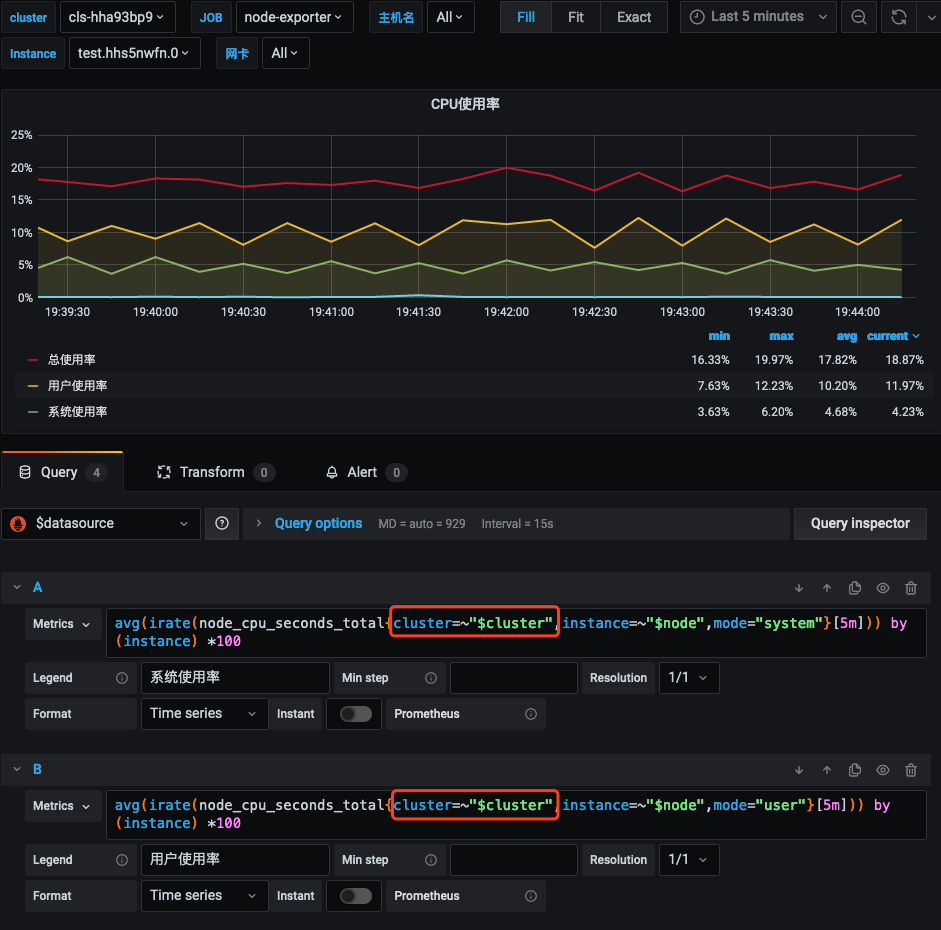
Integrating with the existing systems
Cloud native monitoring supports accessing self-built Grafana and AlertManager systems.
Cloud native monitoring provides Prometheus API. If you need to use self-built Grafana to display monitoring, you can add cloud native monitoring data as a Prometheus data source to self-built Grafana. You can find the Prometheus API address in the basic information of cloud native monitoring instance on TKE console.
- Log in to the TKE console.
- Click Cloud Native Monitoring in the left sidebar to go to the Cloud Native Monitoring page.
- Click the instance ID/name to go to its details page to obtain the Prometheus API address.
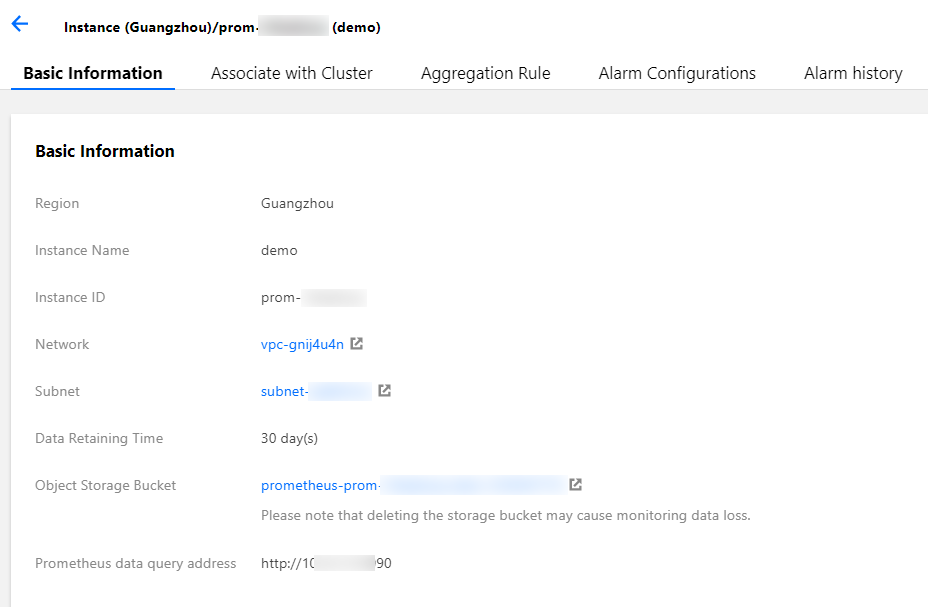
>?Ensure that the self-built Grafana and cloud native monitoring are in the same VPC or their networks have connected. - Add the Prometheus API address in Grafana as the Prometheus data source, as shown below:
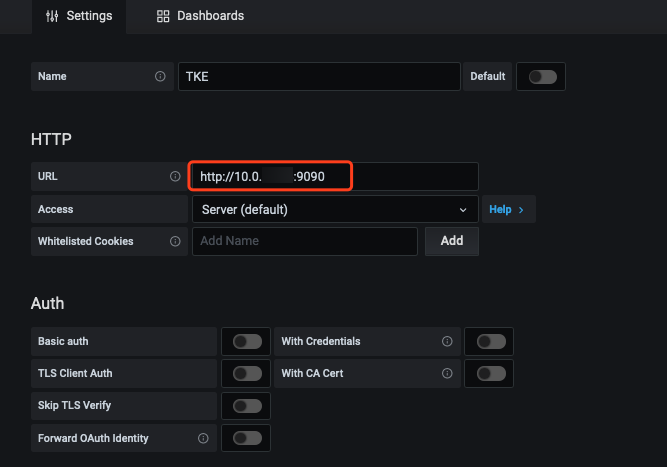


 Yes
Yes
 No
No
Was this page helpful?