- Release Notes and Announcements
- Release Notes
- Announcements
- qGPU Service Adjustment
- Version Upgrade of Master Add-On of TKE Managed Cluster
- Upgrading tke-monitor-agent
- Discontinuing TKE API 2.0
- Instructions on Cluster Resource Quota Adjustment
- Discontinuing Kubernetes v1.14 and Earlier Versions
- Deactivation of Scaling Group Feature
- Notice on TPS Discontinuation on May 16, 2022 at 10:00 (UTC +8)
- Basic Monitoring Architecture Upgrade
- Starting Charging on Managed Clusters
- Instructions on Stopping Delivering the Kubeconfig File to Nodes
- Security Vulnerability Fix Description
- Release Notes
- Product Introduction
- Purchase Guide
- Quick Start
- TKE General Cluster Guide
- TKE General Cluster Overview
- Purchase a TKE General Cluster
- High-risk Operations of Container Service
- Deploying Containerized Applications in the Cloud
- Kubernetes API Operation Guide
- Open Source Components
- Permission Management
- Cluster Management
- Cluster Overview
- Cluster Hosting Modes Introduction
- Cluster Lifecycle
- Creating a Cluster
- Deleting a Cluster
- Cluster Scaling
- Changing the Cluster Operating System
- Connecting to a Cluster
- Upgrading a Cluster
- Enabling IPVS for a Cluster
- Enabling GPU Scheduling for a Cluster
- Custom Kubernetes Component Launch Parameters
- Using KMS for Kubernetes Data Source Encryption
- Images
- Worker node introduction
- Normal Node Management
- Native Node Management
- Overview
- Purchasing Native Nodes
- Lifecycle of a Native Node
- Native Node Parameters
- Creating Native Nodes
- Deleting Native Nodes
- Self-Heal Rules
- Declarative Operation Practice
- Native Node Scaling
- In-place Pod Configuration Adjustment
- Enabling SSH Key Login for a Native Node
- Management Parameters
- Enabling Public Network Access for a Native Node
- Supernode management
- Registered Node Management
- GPU Share
- Kubernetes Object Management
- Overview
- Namespace
- Workload
- Deployment Management
- StatefulSet Management
- DaemonSet Management
- Job Management
- CronJob Management
- Setting the Resource Limit of Workload
- Setting the Scheduling Rule for a Workload
- Setting the Health Check for a Workload
- Setting the Run Command and Parameter for a Workload
- Using a Container Image in a TCR Enterprise Instance to Create a Workload
- Auto Scaling
- Configuration
- Register node management
- Service Management
- Ingress Management
- Storage Management
- Application and Add-On Feature Management Description
- Add-On Management
- Add-on Overview
- Add-On Lifecycle Management
- CBS-CSI Description
- UserGroupAccessControl
- COS-CSI
- CFS-CSI
- P2P
- OOMGuard
- TCR Introduction
- TCR Hosts Updater
- DNSAutoscaler
- NodeProblemDetectorPlus Add-on
- NodeLocalDNSCache
- Network Policy
- DynamicScheduler
- DeScheduler
- Nginx-ingress
- HPC
- Description of tke-monitor-agent
- GPU-Manager Add-on
- CFSTURBO-CSI
- tke-log-agent
- Helm Application
- Application Market
- Network Management
- Container Network Overview
- GlobalRouter Mode
- VPC-CNI Mode
- VPC-CNI Mode
- Multiple Pods with Shared ENI Mode
- Pods with Exclusive ENI Mode
- Static IP Address Mode Instructions
- Non-static IP Address Mode Instructions
- Interconnection Between VPC-CNI and Other Cloud Resources/IDC Resources
- Security Group of VPC-CNI Mode
- Instructions on Binding an EIP to a Pod
- VPC-CNI Component Description
- Limits on the Number of Pods in VPC-CNI Mode
- Cilium-Overlay Mode
- OPS Center
- Log Management
- Backup Center
- Cloud Native Monitoring
- Remote Terminals
- TKE Serverless Cluster Guide
- TKE Edge Cluster Guide
- TKE Registered Cluster Guide
- TKE Container Instance Guide
- Cloud Native Service Guide
- Best Practices
- Cluster
- Cluster Migration
- Serverless Cluster
- Edge Cluster
- Security
- Service Deployment
- Hybrid Cloud
- Network
- DNS
- Using Network Policy for Network Access Control
- Deploying NGINX Ingress on TKE
- Nginx Ingress High-Concurrency Practices
- Nginx Ingress Best Practices
- Limiting the bandwidth on pods in TKE
- Directly connecting TKE to the CLB of pods based on the ENI
- Use CLB-Pod Direct Connection on TKE
- Obtaining the Real Client Source IP in TKE
- Using Traefik Ingress in TKE
- Release
- Logs
- Monitoring
- OPS
- Removing and Re-adding Nodes from and to Cluster
- Using Ansible to Batch Operate TKE Nodes
- Using Cluster Audit for Troubleshooting
- Renewing a TKE Ingress Certificate
- Using cert-manager to Issue Free Certificates
- Using cert-manager to Issue Free Certificate for DNSPod Domain Name
- Using the TKE NPDPlus Plug-In to Enhance the Self-Healing Capability of Nodes
- Using kubecm to Manage Multiple Clusters kubeconfig
- Quick Troubleshooting Using TKE Audit and Event Services
- Customizing RBAC Authorization in TKE
- Clearing De-registered Tencent Cloud Account Resources
- Terraform
- DevOps
- Auto Scaling
- Cluster Auto Scaling Practices
- Using tke-autoscaling-placeholder to Implement Auto Scaling in Seconds
- Installing metrics-server on TKE
- Using Custom Metrics for Auto Scaling in TKE
- Utilizing HPA to Auto Scale Businesses on TKE
- Using VPA to Realize Pod Scaling up and Scaling down in TKE
- Adjusting HPA Scaling Sensitivity Based on Different Business Scenarios
- Storage
- Containerization
- Microservice
- Cost Management
- Fault Handling
- Disk Full
- High Workload
- Memory Fragmentation
- Cluster DNS Troubleshooting
- Cluster kube-proxy Troubleshooting
- Cluster API Server Inaccessibility Troubleshooting
- Service and Ingress Inaccessibility Troubleshooting
- Troubleshooting for Pod Network Inaccessibility
- Pod Status Exception and Handling
- Authorizing Tencent Cloud OPS Team for Troubleshooting
- Engel Ingres appears in Connechtin Reverside
- CLB Loopback
- CLB Ingress Creation Error
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Cluster APIs
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateCluster
- UpdateClusterVersion
- UpdateClusterKubeconfig
- DescribeBackupStorageLocations
- DeleteBackupStorageLocation
- CreateBackupStorageLocation
- Add-on APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- DescribeTKEEdgeScript
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeClusters
- DescribeTKEEdgeClusterStatus
- DescribeTKEEdgeClusterCredential
- DescribeEdgeClusterInstances
- DescribeEdgeCVMInstances
- DescribeECMInstances
- DescribeAvailableTKEEdgeVersion
- DeleteTKEEdgeCluster
- DeleteEdgeClusterInstances
- DeleteEdgeCVMInstances
- DeleteECMInstances
- CreateTKEEdgeCluster
- CreateECMInstances
- CheckEdgeClusterCIDR
- ForwardTKEEdgeApplicationRequestV3
- UninstallEdgeLogAgent
- InstallEdgeLogAgent
- DescribeEdgeLogSwitches
- CreateEdgeLogConfig
- CreateEdgeCVMInstances
- UpdateEdgeClusterVersion
- DescribeEdgeClusterUpgradeInfo
- Cloud Native Monitoring APIs
- Virtual node APIs
- Other APIs
- Scaling group APIs
- Data Types
- Error Codes
- API Mapping Guide
- TKE Insight
- TKE Scheduling
- FAQs
- Service Agreement
- Contact Us
- Purchase Channels
- Glossary
- User Guide(Old)
- Release Notes and Announcements
- Release Notes
- Announcements
- qGPU Service Adjustment
- Version Upgrade of Master Add-On of TKE Managed Cluster
- Upgrading tke-monitor-agent
- Discontinuing TKE API 2.0
- Instructions on Cluster Resource Quota Adjustment
- Discontinuing Kubernetes v1.14 and Earlier Versions
- Deactivation of Scaling Group Feature
- Notice on TPS Discontinuation on May 16, 2022 at 10:00 (UTC +8)
- Basic Monitoring Architecture Upgrade
- Starting Charging on Managed Clusters
- Instructions on Stopping Delivering the Kubeconfig File to Nodes
- Security Vulnerability Fix Description
- Release Notes
- Product Introduction
- Purchase Guide
- Quick Start
- TKE General Cluster Guide
- TKE General Cluster Overview
- Purchase a TKE General Cluster
- High-risk Operations of Container Service
- Deploying Containerized Applications in the Cloud
- Kubernetes API Operation Guide
- Open Source Components
- Permission Management
- Cluster Management
- Cluster Overview
- Cluster Hosting Modes Introduction
- Cluster Lifecycle
- Creating a Cluster
- Deleting a Cluster
- Cluster Scaling
- Changing the Cluster Operating System
- Connecting to a Cluster
- Upgrading a Cluster
- Enabling IPVS for a Cluster
- Enabling GPU Scheduling for a Cluster
- Custom Kubernetes Component Launch Parameters
- Using KMS for Kubernetes Data Source Encryption
- Images
- Worker node introduction
- Normal Node Management
- Native Node Management
- Overview
- Purchasing Native Nodes
- Lifecycle of a Native Node
- Native Node Parameters
- Creating Native Nodes
- Deleting Native Nodes
- Self-Heal Rules
- Declarative Operation Practice
- Native Node Scaling
- In-place Pod Configuration Adjustment
- Enabling SSH Key Login for a Native Node
- Management Parameters
- Enabling Public Network Access for a Native Node
- Supernode management
- Registered Node Management
- GPU Share
- Kubernetes Object Management
- Overview
- Namespace
- Workload
- Deployment Management
- StatefulSet Management
- DaemonSet Management
- Job Management
- CronJob Management
- Setting the Resource Limit of Workload
- Setting the Scheduling Rule for a Workload
- Setting the Health Check for a Workload
- Setting the Run Command and Parameter for a Workload
- Using a Container Image in a TCR Enterprise Instance to Create a Workload
- Auto Scaling
- Configuration
- Register node management
- Service Management
- Ingress Management
- Storage Management
- Application and Add-On Feature Management Description
- Add-On Management
- Add-on Overview
- Add-On Lifecycle Management
- CBS-CSI Description
- UserGroupAccessControl
- COS-CSI
- CFS-CSI
- P2P
- OOMGuard
- TCR Introduction
- TCR Hosts Updater
- DNSAutoscaler
- NodeProblemDetectorPlus Add-on
- NodeLocalDNSCache
- Network Policy
- DynamicScheduler
- DeScheduler
- Nginx-ingress
- HPC
- Description of tke-monitor-agent
- GPU-Manager Add-on
- CFSTURBO-CSI
- tke-log-agent
- Helm Application
- Application Market
- Network Management
- Container Network Overview
- GlobalRouter Mode
- VPC-CNI Mode
- VPC-CNI Mode
- Multiple Pods with Shared ENI Mode
- Pods with Exclusive ENI Mode
- Static IP Address Mode Instructions
- Non-static IP Address Mode Instructions
- Interconnection Between VPC-CNI and Other Cloud Resources/IDC Resources
- Security Group of VPC-CNI Mode
- Instructions on Binding an EIP to a Pod
- VPC-CNI Component Description
- Limits on the Number of Pods in VPC-CNI Mode
- Cilium-Overlay Mode
- OPS Center
- Log Management
- Backup Center
- Cloud Native Monitoring
- Remote Terminals
- TKE Serverless Cluster Guide
- TKE Edge Cluster Guide
- TKE Registered Cluster Guide
- TKE Container Instance Guide
- Cloud Native Service Guide
- Best Practices
- Cluster
- Cluster Migration
- Serverless Cluster
- Edge Cluster
- Security
- Service Deployment
- Hybrid Cloud
- Network
- DNS
- Using Network Policy for Network Access Control
- Deploying NGINX Ingress on TKE
- Nginx Ingress High-Concurrency Practices
- Nginx Ingress Best Practices
- Limiting the bandwidth on pods in TKE
- Directly connecting TKE to the CLB of pods based on the ENI
- Use CLB-Pod Direct Connection on TKE
- Obtaining the Real Client Source IP in TKE
- Using Traefik Ingress in TKE
- Release
- Logs
- Monitoring
- OPS
- Removing and Re-adding Nodes from and to Cluster
- Using Ansible to Batch Operate TKE Nodes
- Using Cluster Audit for Troubleshooting
- Renewing a TKE Ingress Certificate
- Using cert-manager to Issue Free Certificates
- Using cert-manager to Issue Free Certificate for DNSPod Domain Name
- Using the TKE NPDPlus Plug-In to Enhance the Self-Healing Capability of Nodes
- Using kubecm to Manage Multiple Clusters kubeconfig
- Quick Troubleshooting Using TKE Audit and Event Services
- Customizing RBAC Authorization in TKE
- Clearing De-registered Tencent Cloud Account Resources
- Terraform
- DevOps
- Auto Scaling
- Cluster Auto Scaling Practices
- Using tke-autoscaling-placeholder to Implement Auto Scaling in Seconds
- Installing metrics-server on TKE
- Using Custom Metrics for Auto Scaling in TKE
- Utilizing HPA to Auto Scale Businesses on TKE
- Using VPA to Realize Pod Scaling up and Scaling down in TKE
- Adjusting HPA Scaling Sensitivity Based on Different Business Scenarios
- Storage
- Containerization
- Microservice
- Cost Management
- Fault Handling
- Disk Full
- High Workload
- Memory Fragmentation
- Cluster DNS Troubleshooting
- Cluster kube-proxy Troubleshooting
- Cluster API Server Inaccessibility Troubleshooting
- Service and Ingress Inaccessibility Troubleshooting
- Troubleshooting for Pod Network Inaccessibility
- Pod Status Exception and Handling
- Authorizing Tencent Cloud OPS Team for Troubleshooting
- Engel Ingres appears in Connechtin Reverside
- CLB Loopback
- CLB Ingress Creation Error
- API Documentation
- History
- Introduction
- API Category
- Making API Requests
- Cluster APIs
- DescribeEncryptionStatus
- DisableEncryptionProtection
- EnableEncryptionProtection
- AcquireClusterAdminRole
- CreateClusterEndpoint
- CreateClusterEndpointVip
- DeleteCluster
- DeleteClusterEndpoint
- DeleteClusterEndpointVip
- DescribeAvailableClusterVersion
- DescribeClusterAuthenticationOptions
- DescribeClusterCommonNames
- DescribeClusterEndpointStatus
- DescribeClusterEndpointVipStatus
- DescribeClusterEndpoints
- DescribeClusterKubeconfig
- DescribeClusterLevelAttribute
- DescribeClusterLevelChangeRecords
- DescribeClusterSecurity
- DescribeClusterStatus
- DescribeClusters
- DescribeEdgeAvailableExtraArgs
- DescribeEdgeClusterExtraArgs
- DescribeResourceUsage
- DisableClusterDeletionProtection
- EnableClusterDeletionProtection
- GetClusterLevelPrice
- GetUpgradeInstanceProgress
- ModifyClusterAttribute
- ModifyClusterAuthenticationOptions
- ModifyClusterEndpointSP
- UpgradeClusterInstances
- CreateCluster
- UpdateClusterVersion
- UpdateClusterKubeconfig
- DescribeBackupStorageLocations
- DeleteBackupStorageLocation
- CreateBackupStorageLocation
- Add-on APIs
- Network APIs
- Node APIs
- Node Pool APIs
- TKE Edge Cluster APIs
- DescribeTKEEdgeScript
- DescribeTKEEdgeExternalKubeconfig
- DescribeTKEEdgeClusters
- DescribeTKEEdgeClusterStatus
- DescribeTKEEdgeClusterCredential
- DescribeEdgeClusterInstances
- DescribeEdgeCVMInstances
- DescribeECMInstances
- DescribeAvailableTKEEdgeVersion
- DeleteTKEEdgeCluster
- DeleteEdgeClusterInstances
- DeleteEdgeCVMInstances
- DeleteECMInstances
- CreateTKEEdgeCluster
- CreateECMInstances
- CheckEdgeClusterCIDR
- ForwardTKEEdgeApplicationRequestV3
- UninstallEdgeLogAgent
- InstallEdgeLogAgent
- DescribeEdgeLogSwitches
- CreateEdgeLogConfig
- CreateEdgeCVMInstances
- UpdateEdgeClusterVersion
- DescribeEdgeClusterUpgradeInfo
- Cloud Native Monitoring APIs
- Virtual node APIs
- Other APIs
- Scaling group APIs
- Data Types
- Error Codes
- API Mapping Guide
- TKE Insight
- TKE Scheduling
- FAQs
- Service Agreement
- Contact Us
- Purchase Channels
- Glossary
- User Guide(Old)
Overview
This document describes how to host a Spring Cloud application to TKE.
Hosting Spring Cloud applications to TKE has the following advantages:
- Improve the resource utilization.
- Kubernetes is a natural fit for microservice architectures.
- Improve the Ops efficiency and facilitate DevOps implementation.
- Highly scalable Kubernetes makes it easy to dynamically scale applications.
- TKE provides Kubernetes master management to ease Kubernetes cluster Ops and management.
- TKE is integrated with other cloud-native products of Tencent Cloud to help you better use Tencent Cloud products.
Best Practices
PiggyMetrics overview
This document describes how to host a Spring Cloud application to TKE by forking the open-source PiggyMetrics on GitHub and adapting it to Tencent Cloud products.
Note:The modified PiggyMetrics deployment project is hosted on GitHub. After creating the basic service cluster, you can download the deployment project and deploy it in TKE.
The PiggyMetrics homepage is as shown below: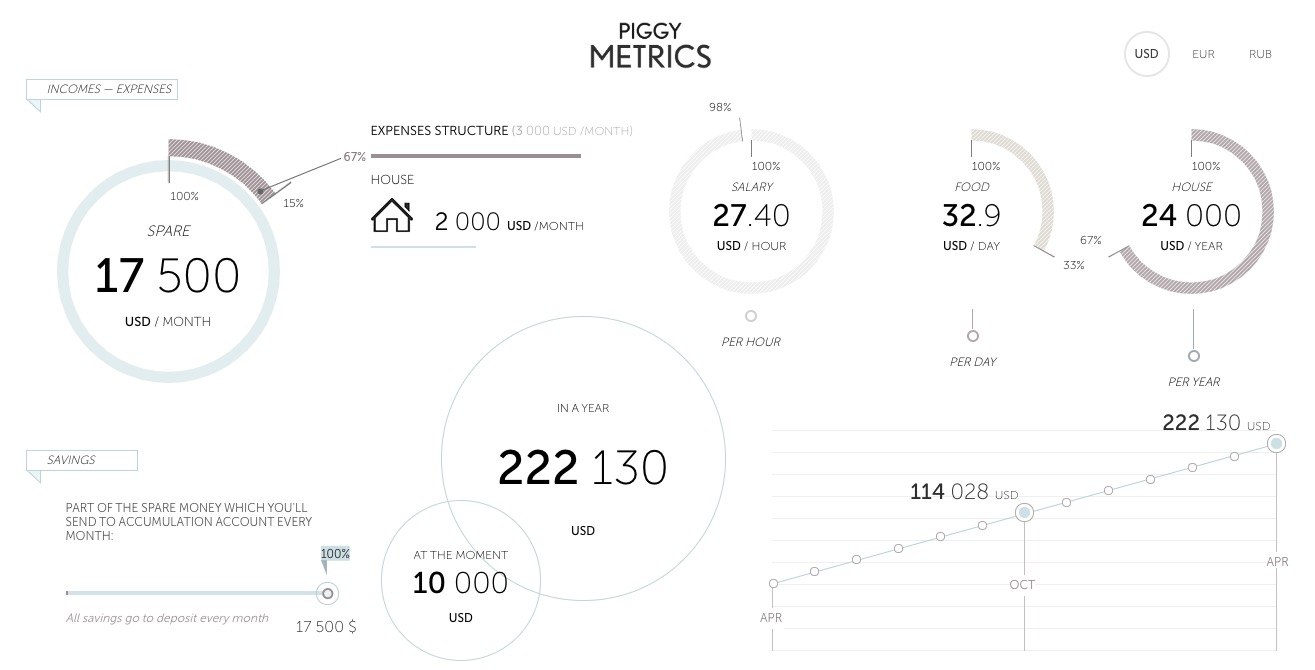
PiggyMetrics is a microservice-architecture application for personal finances developed by using the Spring Cloud framework.
PiggyMetrics consists of the following microservices:
| Microservice | Description |
|---|---|
| API gateway | It's a Spring Cloud Zuul-based gateway and the aggregated portal for calling backend APIs, providing reverse routing and load balancing (Eureka + Ribbon) as well as rate limiting (Hystrix). Client single-page applications and the Zuul gateway are deployed together to simplify deployment. |
| Service registration and discovery | A Spring Cloud Eureka registry. Business services are registered through Eureka when they are enabled, and service discovery is performed through Eureka when services are called. |
| Authorization and authentication service | An authorization and authentication center based on Spring Security OAuth2. The client gets the access token through the Auth Service during logins, and so does service call. Each resource server verifies the token through the Auth Service. |
| Configuration service | A configuration center based on Spring Cloud Config to centrally manage configuration files for all Spring services. |
| Soft loading and rate limiting | Ribbon and Hystrix based on Spring Cloud. Zuul calls backend services through Ribbon for soft loading and Hystrix for rate limiting. |
| Metrics and dashboard | Hystrix Dashboard based on Spring Cloud Turbine, aggregating all the PiggyMetrics streams generated by Hystrix and displaying them on the Hystrix Dashboard. |
PiggyMetrics deployment architecture and add-ons
In the following best practice, applications deployed in CVM are containerized and hosted to TKE. In this use case, one VPC is used and divided into two subnets:
- Subnet-Basic is deployed with stateful basic services, including Dubbo's service registry Nacos, MySQL, and Redis.
- Subnet-K8S is deployed with PiggyMetrics application services, all of which are containerized and run in TKE.
The VPC is divided as shown below: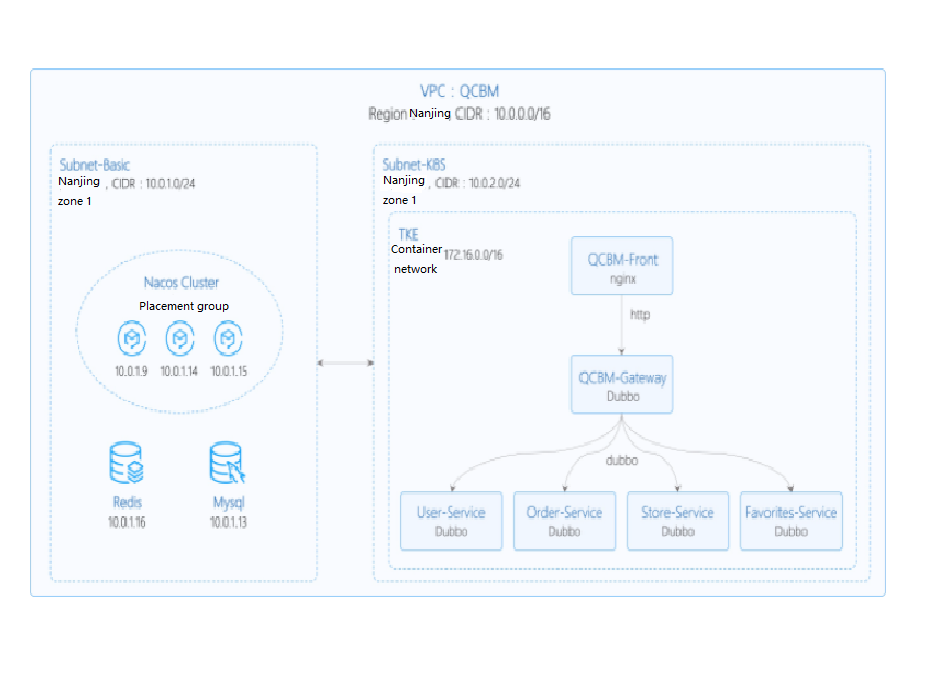
The network planning for the PiggyMetrics instance is as shown below:
| Network Planning | Description |
|---|---|
| Region/AZ | Nanjing/Nanjing Zone 1 |
| VPC | CIDR: 10.0.0.0/16 |
| Subnet-Basic | Nanjing Zone 1, CIDR block: 10.0.1.0/24 |
| Subnet-K8S | Nanjing Zone 1, CIDR block: 10.0.2.0/24 |
| Nacos cluster | Nacos cluster built with three 1-core 2 GB MEM Standard SA2 CVM instances with IP addresses of 10.0.1.9, 10.0.1.14, and 10.0.1.15 |
The add-ons used in the PiggyMetrics instance are as shown below:
| Add-on | Version | Source | Remarks |
|---|---|---|---|
| K8S | 1.8.4 | Tencent Cloud | TKE management mode |
| MongoDB | 4.0 | Tencent Cloud | TencentDB for MongoDB WiredTiger engine |
| CLS | N/A | Tencent Cloud | Log service |
| TSW | N/A | Tencent Cloud | Accessed with SkyWalking 8.4.0 Agent, which can be downloaded here |
| Java | 1.8 | Open-source community | Docker image of Java 8 JRE |
| Spring Cloud | Finchley.RELEASE | Open-source community | Spring Cloud website |
Overview
TCR
Tencent Cloud Tencent Container Registry (TCR) are available in Personal Edition and Enterprise Edition as differentiated below:
- TCR Personal Edition is only deployed in Guangzhou, while TCR Enterprise Edition is deployed in every region.
- TCR Personal Edition doesn't offer SLA guarantee.
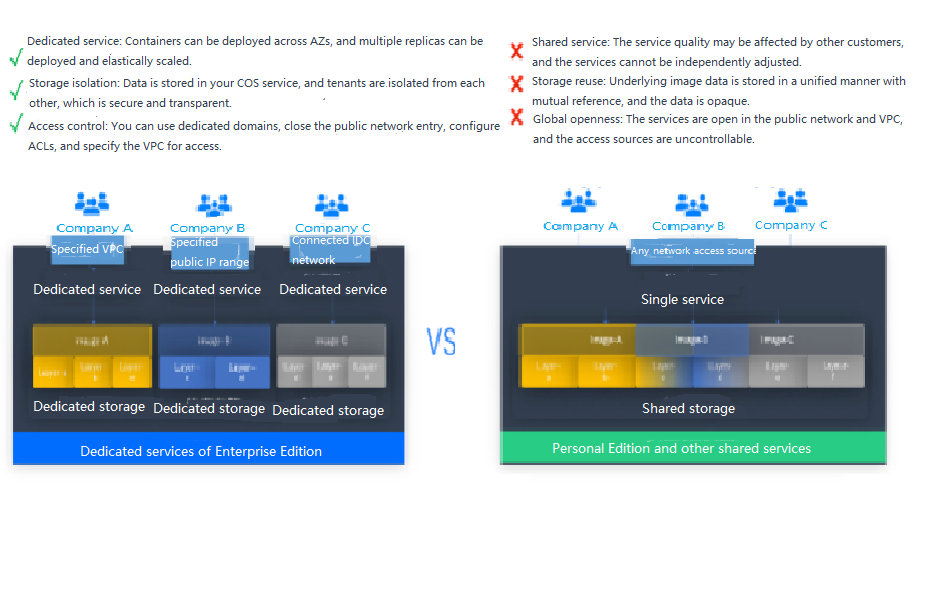
PiggyMetrics is a Dubbo containerized demo project, so TCR Personal Edition perfectly meets its needs. However, for enterprise users, TCR Enterprise Edition is recommended. To use an image repository, see Basic Image Repository Operations.
TSW
Tencent Service Watcher (TSW) provides cloud-native service observability solutions that can trace upstream and downstream dependencies in distributed architectures, draw topologies, and provide multidimensional call observation by service, API, instance, and middleware.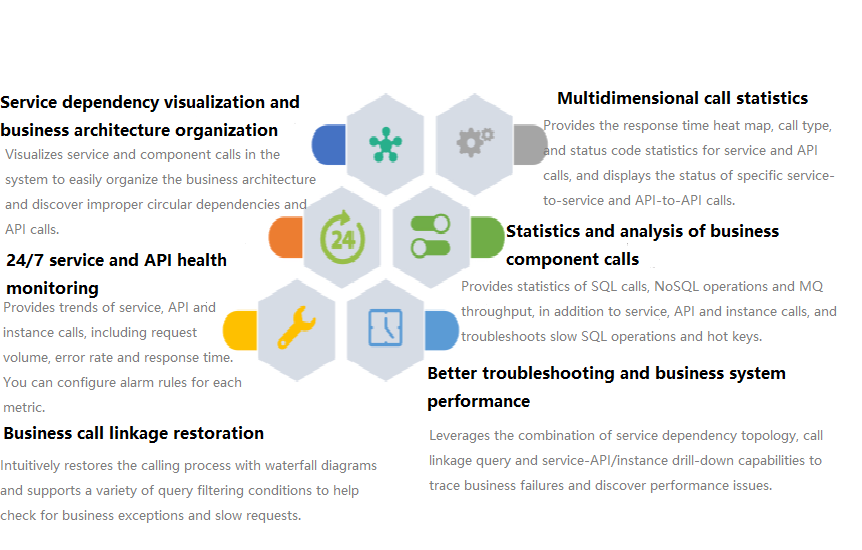
TSW is architecturally divided into four modules:
Data collection (client)
展开&收起You can use an open-source probe or SDK to collect data. If you are migrating to the cloud, you can change the reporting address and authentication information only and keep most of the configurations on the client.
Data processing (server)
展开&收起Data is reported to the server via the Pulsar message queue, converted by the adapter into an OpenTracing-compatible format, and assigned to real-time and offline computing as needed.
- Real-time computing provides real-time monitoring, statistical data display, and fast response to the connected alarming platform.
- Offline computing aggregates the statistical data in large amounts over long periods of time and leverages big data analytics to provide business value.
Storage
展开&收起The storage layer can adapt to use cases with different data types, writing at the server layer, and query and reading requests at the data usage layer.
Data usage
展开&收起The data usage layer provides underlying support for console operations, data display, and alarming.
The architecture is as shown below: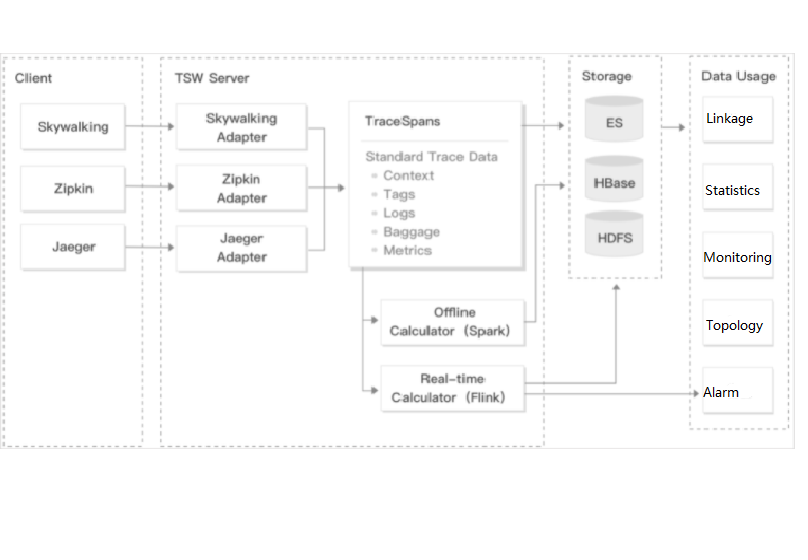
Directions
Creating basic service cluster
In the TencentDB for MongoDB console, create an instance and run the following command to initialize it:
# Download the MongoDB client, decompress it, and enter the `bin` directory.
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.6.18.tgz
tar -zxvf mongodb-linux-x86_64-3.6.18.tgz
cd mongodb-linux-x86_64-3.6.18/bin
# Run the following command to initialize MongoDB, where `mongouser` is the admin account created when the MongoDB instance is created.
./mongo -u mongouser -p --authenticationDatabase "admin" [mongodb IP]/piggymetrics mongo-init.jsA guest user of the
piggymetricslibrary is created in the MongoDB initialization script mongo-init.js by default, which can be modified as needed.In the CLB console, create a private network CLB instance for
Subnet-K8S(the ID of this CLB instance will be used later).TSW is currently in beta test and supports both Java and Go.
Building Docker image
Writing Dockerfile
The following uses account-service as an example to describe how to write a Dockerfile. The project directory structure of account-service is displayed, Dockerfile is in the root directory of the project, and account-service.jar is the packaged file that needs to be added to the image.
➜ account-service tree
├── Dockerfile
├── skywalking
│ ├── account.config
│ └── skywalking-agent.zip
├── pom.xml
├── src
│ ....
├── target
│ .....
│ └── account-service.jar
└── account-service.iml
Note:Here, SkyWalking Agent is used as the TSW access client that reports call chain information to the TSW backend. For more information on how to download SkyWalking Agent, see PiggyMetrics deployment architecture and add-ons.
The Dockerfile of account-service is as shown below:
FROM java:8-jre
# Working directory in the container
/appWORKDIR /app
# Add the locally packaged application to the image.
ADD ./target/account-service.jar
# Copy SkyWalking Agent to the image.
COPY ./skywalking/skywalking-agent.zip
# Decompress SkyWalking Agent and delete the original compressed file.
RUN unzip skywalking-agent.zip && rm -f skywalking-agent.zip
# Add the SkyWalking configuration file.
COPY ./skywalking/account.config ./skywalking-agent/config/agent.config
# Start the application.
CMD ["java", "-Xmx256m", "-javaagent:/app/skywalking-agent/skywalking-agent.jar", "-jar", "/app/account-service.jar"]
# Port description of the application
EXPOSE 6000Note:As each Run command in the Dockerfile will generate an image layer, we recommend you combine these commands into one.
Image build
TCR provides both automatic and manual methods to build an image. To demonstrate the build process, the manual method is used.
The image name needs to be in line with the convention of ccr.ccs.tencentyun.com/[namespace]/[ImageName]:[image tag]:
- Here,
namespacecan be the project name to facilitate image management and use. In this document,piggymetricsrepresents all the images under the PiggyMetrics project. ImageNamecan contain thesubpath, generally used for multi-project use cases of enterprise users. In addition, if a local image is already built, you can run thedocker tagcommand to rename the image in line with the naming convention.
Run the following command to build an image as shown below:
# Recommended build method, which eliminates the need for secondary tagging operations
sudo docker build -t ccr.ccs.tencentyun.com/[namespace]/[ImageName]:[image tag]
# Build a local `account-service` image. The last `.` indicates that the Dockerfile is stored in the current directory (`account-service`).
➜ account-service docker build -t ccr.ccs.tencentyun.com/piggymetrics/account-service:1.0.0 .
# Rename existing images in line with the naming convention
sudo docker tag [ImageId] ccr.ccs.tencentyun.com/[namespace]/[ImageName]:[image tag]After the build is complete, you can run the following command to view all the images in your local repository.
docker images | grep piggymetricsA sample is as shown below:
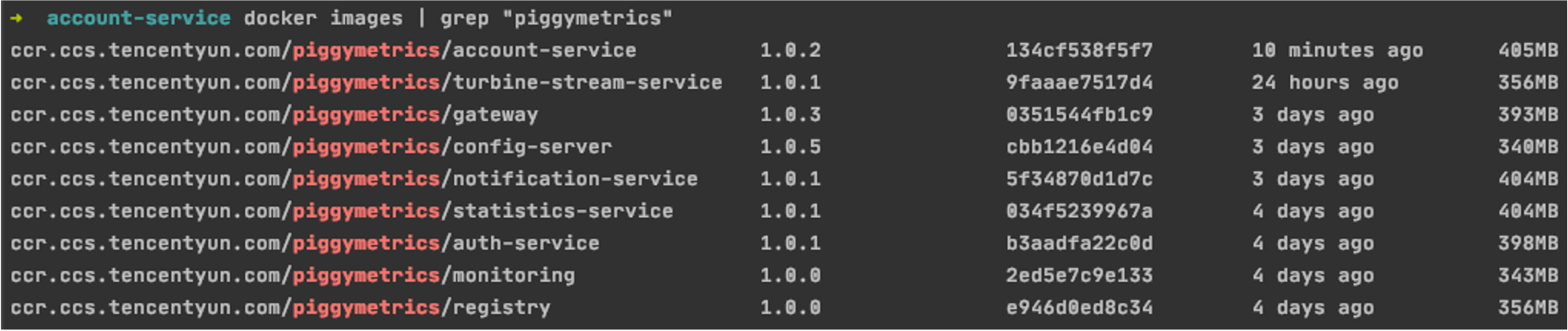
Uploading image to TCR
Creating namespace
The PiggyMetrics project uses TCR Personal Edition (TCR Enterprise Edition is recommended for enterprise users).
- Log in to the TKE console.
- Click TCR > Personal > Namespace to enter the Namespace page.
- Click Create and create the
piggymetricsnamespace in the pop-up window. All the images of the PiggyMetrics project are stored under this namespace as shown below:
Uploading image
Log in to TCR and upload an image.
Run the following command to log in to TCR.
docker login --username=[Tencent Cloud account ID] ccr.ccs.tencentyun.com- You can get your Tencent Cloud account ID on the Account Info page.
- If you forget your TCR login password, you can reset it in My Images of TCR Personal Edition.
- If you are prompted that you have no permission to run the command, add
sudobefore the command and run it as shown below. In this case, you need to enter two passwords, the server admin password required forsudoand the TCR login password.
As shown below:sudo docker login --username=[Tencent Cloud account ID] ccr.ccs.tencentyun.com
Run the following command to push the locally generated image to TCR.
docker push ccr.ccs.tencentyun.com/[namespace]/[ImageName]:[image tag]As shown below:
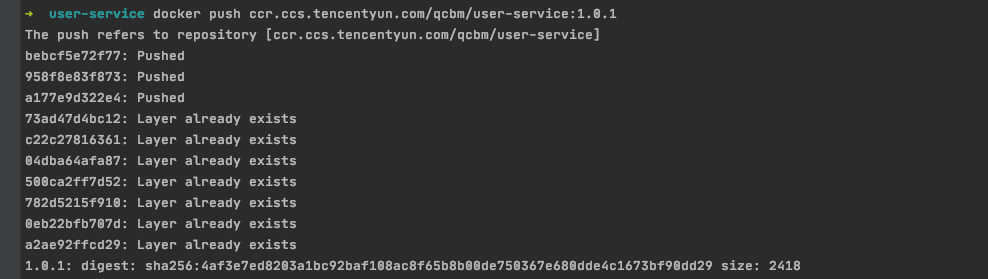
In My Images, you can view all the uploaded images.
The default image type is
Private. If you want to let others use the image, you can set it toPublicin Image Info as shown below:
Deploying service in TKE
Creating K8s cluster PiggyMetrics
- Before the deployment, you need to create a K8s cluster as instructed in Quickly Creating a Standard Cluster.
Note:
When a cluster is created, we recommend you enable Placement Group on the Select Model page. It helps distribute CVM instances across different hosts to increase the system reliability.
- After the cluster is created, you can view its information on the Cluster Management page in the TKE console. Here, the new cluster is named
piggyMetrics. - Click the
PiggyMetrics-k8s-democluster to enter the Basic Info page to view the cluster configuration information. - (Optional) If you want to use K8s management tools such as kubectl and Lens, you need to follow two steps:
- Enable public network access.
- Store the API authentication token in the local
configfile underuser home/.kube(choose another if theconfigfile has content) to ensure that the default cluster can be accessed each time. If you choose not to store the token in theconfigfile under.kube, see the Instructions on Connecting to Kubernetes Cluster via kubectl under Cluster API Server Info in the console as shown below: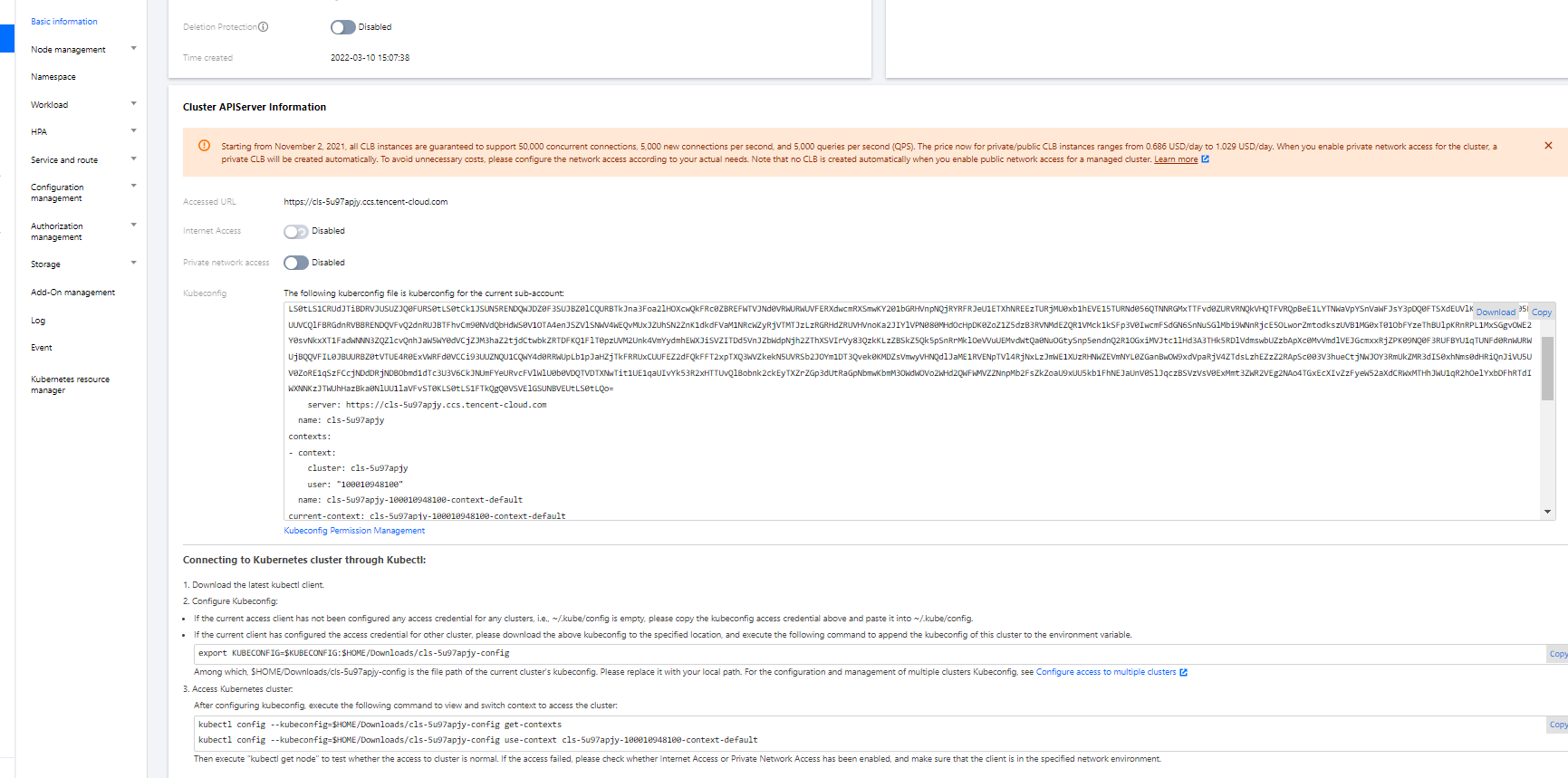
Creating namespace
A namespace is a logical environment in a Kubernetes cluster, allowing you to divide teams or projects. You can create a namespace in the following three methods, and method 1 is recommended.
Run the following command to create a namespace:
kubectl create namespace piggymetricsUsing ConfigMap to store configuration information
ConfigMap allows you to decouple the configuration from the running image, making the application more portable. The PiggyMetrics backend service needs to get the MongoDB host and port information from the environment variables and store them by using the ConfigMap.
You can use ConfigMap to store configuration information in the following two methods:
The following is the ConfigMap YAML for PiggyMetrics, where values of pure digits require double quotation marks.
# Create a ConfigMap.
apiVersion: v1
kind: ConfigMap
metadata:
name: piggymetrics-env
namespace: piggymetrics
data:
# MongoDB IP address
MONGODB_HOST: 10.0.1.13
# TSW access address as described below
SW_AGENT_COLLECTOR_BACKEND_SERVICES: ap-shanghai.tencentservicewatcher.com:11800
Using Secret to store sensitive information
A Secret can be used to store sensitive information such as passwords, tokens, and keys to reduce exposure risks. PiggyMetrics uses it to store account and password information.
You can use a Secret to store sensitive information in the following two methods:
The following is the YAML for creating a Secret in PiggyMetrics, where the value of the Secret needs to be a Base64-encoded string.
# Create a Secret.
apiVersion: v1
kind: Secret
metadata:
name: piggymetrics-keys
namespace: piggymetrics
labels:
qcloud-app: piggymetrics-keys
data:
# Replace XXX below with the actual value.
MONGODB_USER: XXX
MONGODB_PASSWORD: XXX
SW_AGENT_AUTHENTICATION: XXX
type: Opaque
Deploying stateful service with StatefulSet
A StatefulSet is used to manage stateful applications. A Pod created accordingly has a persistent identifier in line with the specifications, which will be retained after the Pod is migrated, terminated, or restarted. When using persistent storage, you can map storage volumes to identifiers.
The basic add-ons and services under the PiggyMetrics project such as configuration services, registry, and RabbitMQ have their own data stored and are therefore suitable for deployment through StatefulSet.
Below is a sample deployment YAML for config-server:
---
kind: Service
apiVersion: v1
metadata:
name: config-server
namespace: piggymetrics
spec:
clusterIP: None
ports:
- name: http
port: 8888
targetPort: 8888
protocol: TCP
selector:
app: config
version: v1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: config
namespace: piggymetrics
labels:
app: config
version: v1
spec:
serviceName: "config-server"
replicas: 1
selector:
matchLabels:
app: config
version: v1
template:
metadata:
labels:
app: config
version: v1
spec:
terminationGracePeriodSeconds: 10
containers:
- name: config
image: ccr.ccs.tencentyun.com/piggymetrics/config-server:2.0.03
ports:
- containerPort: 8888
protocol: TCPDeploying Deployment
A Deployment declares the Pod template and controls the Pod running policy, which is suitable for deploying stateless applications. PiggyMetrics backend services such as Account are stateless and can use the Deployment.
YAML parameters for the account-service Deployment are as follows:
| Parameter | Description |
|---|---|
| replicas | Indicates the number of Pods to be created. |
| image | Image address |
| imagePullSecrets | The key to pull an image, which can be obtained from Cluster > Configuration Management > Secret. It is not required for public images. |
| env | key-value defined in the ConfigMap can be referenced by using configMapKeyRef.key-value defined in the Secret can be referenced by using secretKeyRef. |
| ports | Specifies the port number of the container. It is 6000 for account-service. |
Below is a complete sample YAML file for the account-service Deployment:
# account-service Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: account-service
namespace: piggymetrics
labels:
app: account-service
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: account-service
version: v1
template:
metadata:
labels:
app: account-service
version: v1
spec:
containers:
- name: account-service
image: ccr.ccs.tencentyun.com/piggymetrics/account-service:1.0.1
env:
# MongoDB IP address
- name: MONGODB_HOST
valueFrom:
configMapKeyRef:
key: MONGODB_HOST
name: piggymetrics-env
optional: false
# MongoDB username
- name: MONGODB_USER
valueFrom:
secretKeyRef:
key: MONGODB_USER
name: piggymetrics-keys
optional: false
# MongoDB password
- name: MONGODB_PASSWORD
valueFrom:
secretKeyRef:
key: MONGODB_PASSWORD
name: piggymetrics-keys
optional: false
# TSW access point
- name: SW_AGENT_COLLECTOR_BACKEND_SERVICES
valueFrom:
configMapKeyRef:
key: SW_AGENT_COLLECTOR_BACKEND_SERVICES
name: piggymetrics-env
optional: false
# TSW access token
- name: SW_AGENT_AUTHENTICATION
valueFrom:
secretKeyRef:
key: SW_AGENT_AUTHENTICATION
name: piggymetrics-keys
optional: false
ports:
# Container port
- containerPort: 6000
protocol: TCP
imagePullSecrets: # Token to pull the image
- name: qcloudregistrykeyDeploying Service
You can specify the Service type with Kubernetes ServiceType, which defaults to ClusterIP. Valid values of ServiceType include the following:
- LoadBalancer: Provides public network, VPC, and private network access.
- NodePort: : Accesses services through the CVM IP and host port.
- ClusterIP: Accesses services through the service name and port.
The frontend pages and the gateway of PiggyMetrics are packaged together and need to provide services, so ServiceType is set to LoadBalancer. TKE enriches the LoadBalancer mode by configuring the Service through annotations.
If you use the service.kubernetes.io/qcloud-loadbalancer-internal-subnetid annotations, a private network CLB instance will be created when the Service is deployed. In general, we recommend you create the CLB instance in advance and use the service.kubernetes.io/loadbalance-id annotations in the deployment YAML to improve the efficiency.
Below is the deployment YAML for gateway service:
# Deploy `gateway service`.
apiVersion: v1
kind: Service
metadata:
name: gateway
namespace: piggymetrics
annotations:
# Replace it with the ID of the CLB instance of `Subnet-K8S`.
service.kubernetes.io/loadbalance-id: lb-hfyt76co
spec:
externalTrafficPolicy: Cluster
ports:
- name: http
port: 80
targetPort: 4000
protocol: TCP
selector: # Map the backend `gateway` to the Service.
app: gateway
version: v1
type: LoadBalancerViewing deployment result
At this point, you have completed the deployment of PiggyMetrics in TKE and can view the deployment result in the following steps:
- Log in to the TKE console and click the Cluster ID/Name to enter the cluster details page.
- Click Services and Routes > Service to enter the Service page, where you can see the created Service. You can access the PiggyMetrics page through the
gateway serviceVIP.
Integrating CLS
Enabling container log collection
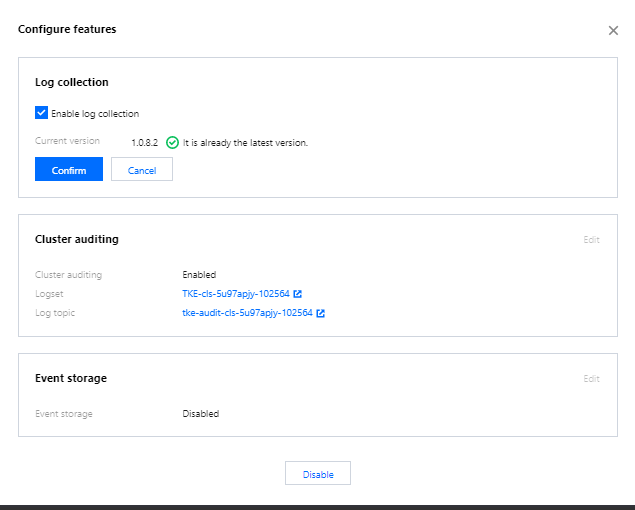
The container log collection feature is disabled by default and needs to be enabled as instructed below:
- Log in to the TKE console and click Cluster Ops > Feature Management on the left sidebar.
- At the top of the Feature Management page, select the region. On the right of the target cluster, click Set.

- On the Configure Features page, click Edit for log collection, enable log collection, and confirm this operation as shown below:
Creating log topic and logset
CLS is region-specific. To reduce the network latency, we recommend you select a region closest to your business when creating log resources, which are mainly logsets and log topics. A logset represents a project, a log topic represents a class of services, and a single logset can contain multiple log topics.
PiggyMetrics is deployed in Nanjing region, so you need to select Nanjing region on the Log Topic page when creating logsets:
- Log in to the CLS console and select Nanjing region on the Log Topic page.
- Click Create Log Topic and enter the relevant information in the pop-up window as prompted as shown below:
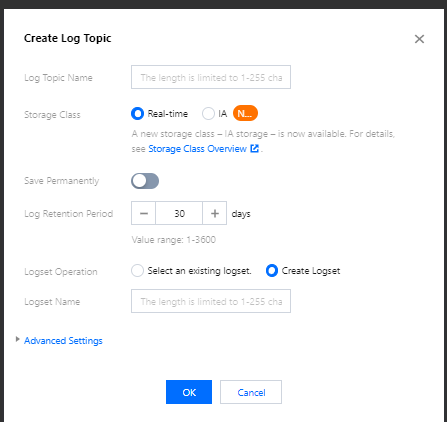
- Log Topic Name: Enter
piggymetrics. - Logset Operation: Select Create Logset.
- Logset Name: Enter
piggymetrics-logs.
- Log Topic Name: Enter
- Click OK.
Note:
As PiggyMetrics has multiple backend microservices, you can create a log topic for each microservice to facilitate log categorization.
- A log topic is created for each PiggyMetrics service.
- You need the log topic ID when creating log rules for containers.
Configuring log collection rule
You can configure container log collection rules in the console or with CRD.
Log rules specify the location of a log in a container:
- Log in to the TKE console and click Cluster Ops > Log Rules on the left sidebar.
- On the Log Rules page, click Create to create a rule.
- Log Source: Specify the location of a log in a container. PiggyMetrics uses the default Spring Cloud configuration where all logs are printed to the standard output. Therefore, you can use the standard container output and specify a Pod Label.
- Consumer: Select the previously created logset and topic.
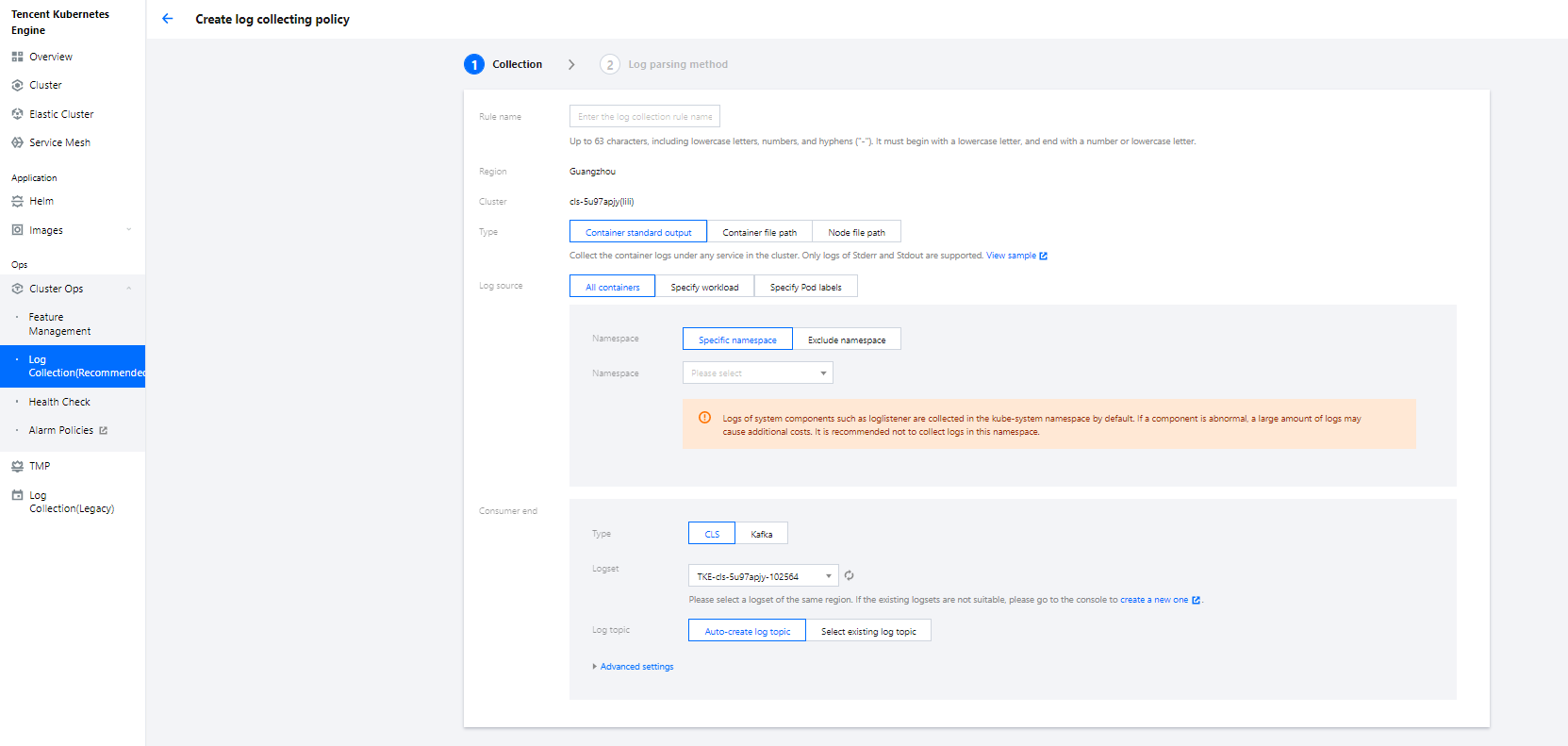
- Click Next to enter the Log Parsing Method. Here, single-line text is used for PiggyMetrics. For more information on the log formats supported by CLS, see Full Text in a Single Line.
Viewing log
- Log in to the CLS console and enter the Search and Analysis page.
- On the Search and Analysis page, Create Index for the logs first and then click Search and Analysis to view the logs.
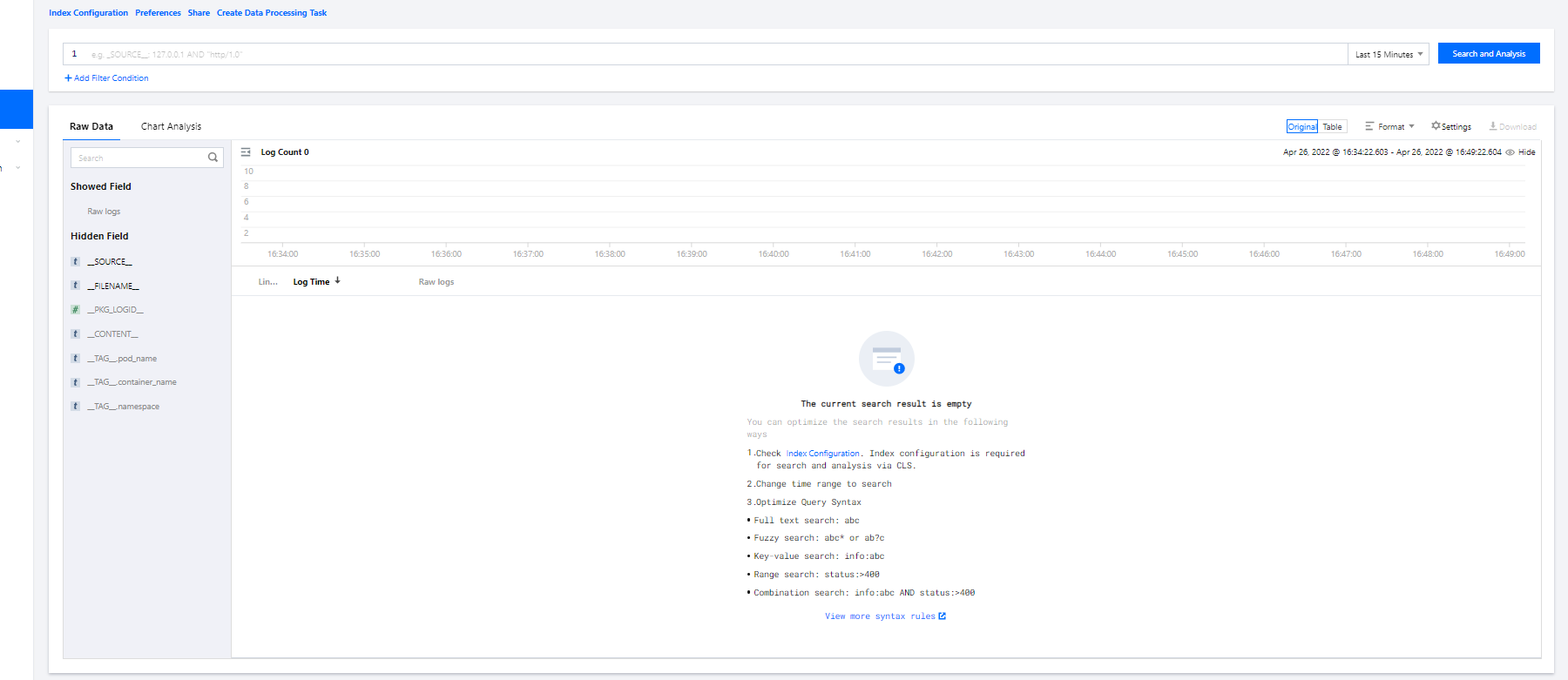 Note:
Note:You can't find logs if no indexes are created.
Integrating TSW
TSW is currently in beta test and can be deployed in Guangzhou and Shanghai. Here, deployment in Shanghai is used as an example (PiggyMetrics is deployed in Nanjing).
Accessing TSW - getting access point information
- Log in to the TSW console and click Service Observation > Service List on the left sidebar.
- Click Access Service and select Java and the SkyWalking data collection method. The access method provides the Access Point and Token information.
Accessing TSW - application and container configuration
Enter the Access Point and Token of the TSW obtained in the previous step in collector.backend_service and agent.authentication respectively in the agent.config of SkyWalking. agent.service_name is the service name, and agent.namespace can be used to group microservices under the same domain. account-service configuration is as shown below: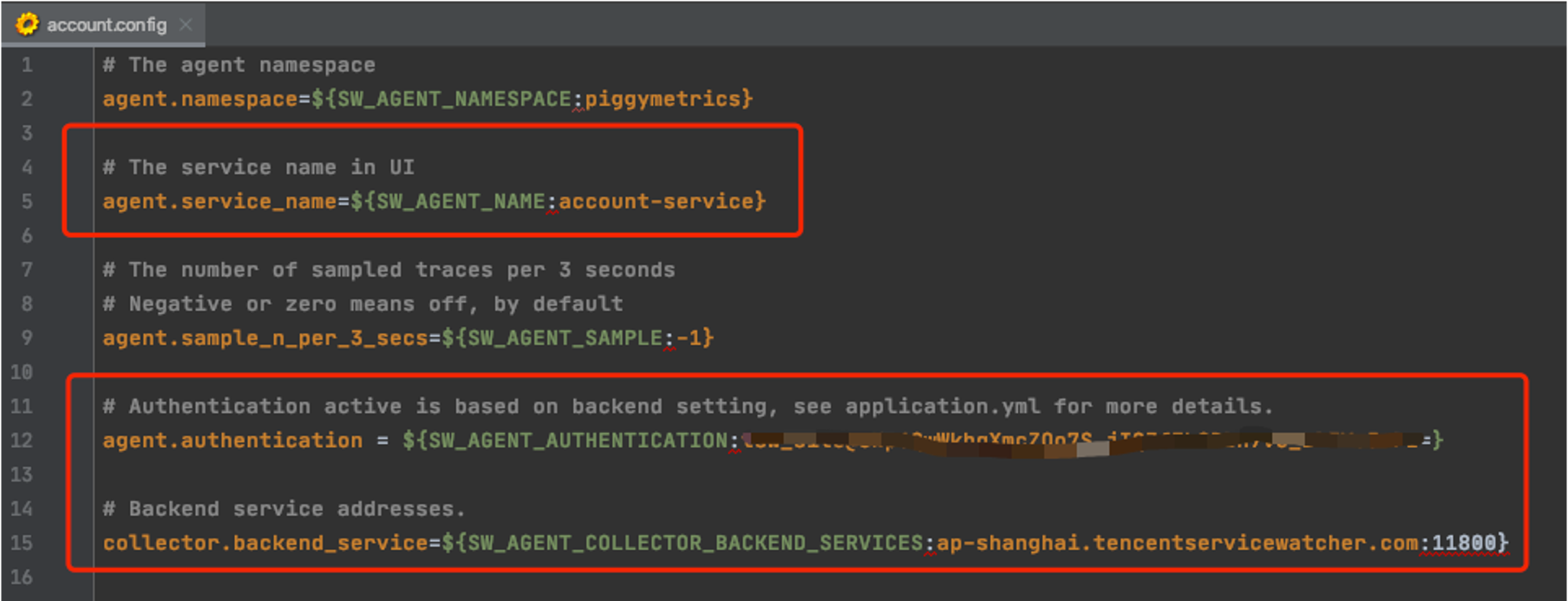
You can also configure SkyWalking Agent by using environment variables. PiggyMetrics uses the ConfigMap and Secret to configure environment variables:
- Use the ConfigMap to configure
SW_AGENT_COLLECTOR_BACKEND_SERVICES. - Use the Secret to configure
SW_AGENT_AUTHENTICATION.
As shown below: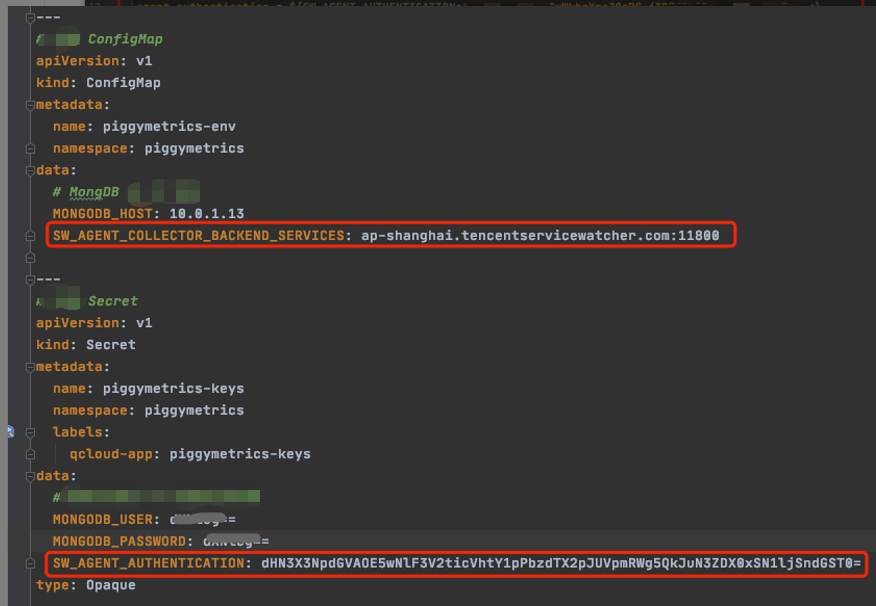
At this point, you have completed TSW access. After starting the container service, you can view the call chain, service topology, and SQL analysis in the TSW console.
Using TSW
Viewing call exception through service API or call chain
- Log in to the TSW console and click Service Observation > API Observation on the left sidebar.
- On the API Observation page, you can view the call status of all APIs under a service, including the number of requests, success rate, error rate, response time, and other metrics.
The figure shows that the gateway andaccount-serviceresponded too slowly and allstatistic-servicerequests failed in the past hour. - Click the service name
statistics-serviceto enter the information page. Click API Observation, and you can see that the API{PUT}/{accountName}throws aNestedServletExceptionexception, which makes the API unavailable. - Click the Trace ID to view the call chain details.
Viewing service topology
- Log in to the TSW console and click Chain Tracing > Distributed Dependency Topology on the left sidebar.
- On the Distributed Dependency Topology page, you can view the completed service dependencies as well as information such as the number of calls and average latency.

 Yes
Yes
 No
No
Was this page helpful?