Directly connecting TKE to the CLB of pods based on the ENI
Unduh
Mode fokus
Ukuran font
Terakhir diperbarui: 2024-12-13 19:37:08
Overview
Kubernetes designs and provides two types of native resources at the cluster access layer, 'Service' and 'Ingress', which are responsible for the network access layer configurations of layer 4 and layer 7, respectively. The traditional solution is to create an Ingress- or LoadBalancer-type service to bind Tencent Cloud CLBs and open services to the public. In this way, user traffic is loaded on the NodePort of the user node, and then forwarded to the container network through the KubeProxy component. This solution has some limitations in business performance and capabilities.
To address these limitations, the Tencent Cloud TKE team provides a new network mode for users who use independent or managed clusters. that is, TKE directly connects to the CLB of pods based on the ENI. This mode provides enhanced performance and business capabilities. This document describes the differences between the two modes and how to use the direct connection mode.
Solution Comparison
Comparison Item
Direct Connection
NodePort Forwarding
Local Forwarding
Performance
Zero loss
NAT forwarding and inter-node forwarding
Minor loss
Pod update
The access layer backend automatically synchronizes updates, so the update process is stable
The access layer backend NodePort remains unchanged
Services may be interrupted without update synchronization
Cluster dependency
Cluster version and VPC-CNI network requirements
-
-
Business capability restriction
Least restriction
Unable to obtain the source IP address or implement session persistence
Conditional session persistence
Analysis of Problems with the Traditional Mode
Performance and features
In a cluster, KubeProxy forwards the traffic from user NodePort through NAT to the cluster network. This process has the following problems:
NAT forwarding causes certain loss in request performance.
NAT operations cause performance loss.
The destination address of NAT forwarding may cause the traffic to be forwarded across nodes in a container network.
NAT forwarding changes the source IP address of the request, so the client cannot obtain the source IP address.
When the CLB traffic is concentrated on several NodePorts, the over-concentrated traffic will cause excessive SNAT forwarding by NodePorts, which will exhaust the traffic capacity of the port. This problem may also lead to conntrack insertion conflicts, resulting in packet loss and performance deterioration.
Forwarding by KubeProxy is random and does not support session persistence.
Each NodePort of KubeProxy has independent load-balancing capabilities. As such capabilities cannot be concentrated in one place, global load balancing is difficult to achieve.
To address the preceding problems, the technical suggestion previously provided to users was to adopt local forwarding to avoid the problems caused by KubeProxy NAT forwarding. However, due to the randomness of forwarding, session persistence remains unsupported when multiple replicas are deployed on a node. Moreover, when local forwarding coincides with rolling updates, services can be easily interrupted. This places higher requirements on the rolling update policies and downtime of businesses.
Service availability
When a service is accessed through NodePorts, the design of NodePorts is highly fault-tolerant. The CLB binds the NodePorts of all nodes in the cluster as the backend. When any node of the cluster accesses the service, the traffic will be randomly allocated to the workloads of the cluster. Therefore, the unavailability of NodePorts or pods does not affect the traffic access of the service.
Similar to local access, in cases where the backend of the CLB is directly connected to user pods, if the CLB cannot be promptly bound to the new pod when the service is processing a rolling update, the number of CLB backends of the service entry may be seriously insufficient or even exhausted as a result of rapid rolling updates. Therefore, when the service is processing a rolling update, the security and stability of the rolling update can be ensured if the CLB of the access layer is healthy.
CLB control plane performance
The control plane APIs of the CLB include APIs for creating, deleting, and modifying layer-4 and layer-7 listeners, creating and deleting layer-7 rules, and binding each listener or the rule backend. Most of these APIs are asynchronous APIs, which require the polling of request results, and API calls are time-consuming. When the scale of the user cluster is large, the synchronization of a large amount of access layer resources can impose high latency pressure on components.
Comparison of the New and Old Modes
Performance comparison
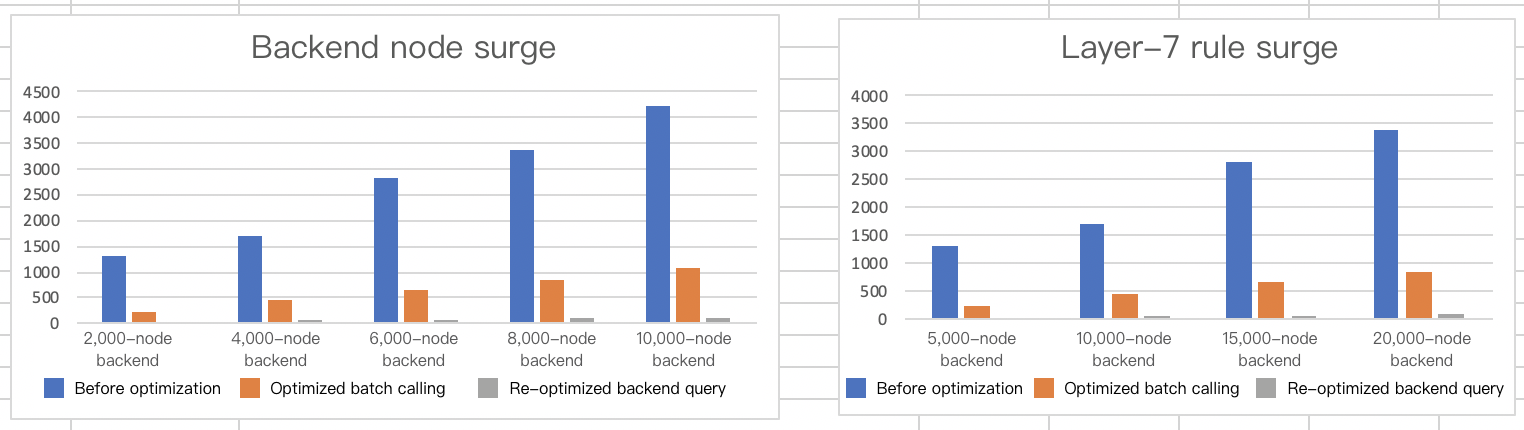
TKE has launched the direct pod connection mode, which optimizes the control plane of the CLB. In the overall synchronization process, this new mode mainly optimizes batch calls and backend instance queries where remote calls are relatively frequent. After the optimization, the performance of the control plane in a typical ingress scenario is improved by 95% to 97% compared with the previous version. At present, the synchronization time is mainly the waiting time of asynchronous APIs.
Backend node data surge
For cluster scaling, the relevant data is as follows:
Layer-7 Rule Quantity
Cluster Node Quantity
Cluster Node Quantity (Update)
Performance Before Optimization (s)
Optimized Batch Calling Performance (s)
Re-optimized Backend Instance Query Performance (s)
Time Consumption Reduction (%)
200
1
10
1313.056
227.908
31.548
97.597%
200
1
20
1715.053
449.795
51.248
97.011%
200
1
30
2826.913
665.619
69.118
97.555%
200
1
40
3373.148
861.583
90.723
97.310%
200
1
50
4240.311
1085.03
106.353
97.491%
Layer-7 rule data surge
For first-time activation and deployment of services in the cluster, the relevant data is as follows:
Layer-7 Rule Quantity
Layer-7 Rule Quantity (Update)
Cluster Node Quantity
Performance Before Optimization (s)
Optimized Batch Calling Performance (s)
Re-optimized Backend Instance Query Performance (s)
Time Consumption Reduction (%)
1
100
50
1631.787
451.644
68.63
95.79%
1
200
50
3399.833
693.207
141.004
95.85%
1
300
50
5630.398
847.796
236.91
95.79%
1
400
50
7562.615
1028.75
335.674
95.56%
The following figure shows the comparison:
In addition to control plane performance optimization, the CLB can directly access the pods of the container network, which is the integral part of component business capabilities. This not only prevents the loss of NAT forwarding performance, but also eliminates the impact of NAT forwarding on the business features in the cluster. However, the support for optimal access to the container network remains unavailable when the project is launched.
The new mode integrates the feature that allows pods to have an ENI entry under the cluster CNI network mode in order to implement direct access to the CLB. CCN solutions are already available for implementing direct CLB backend access to the container network.
In addition to the capability of direct access, availability during rolling updates must be ensured. To implement this, we use the official feature ReadinessGate, which was officially released in version 1.12 and is mainly used to control the conditions of pods.
By default, a pod has three possible conditions: PodScheduled, Initialized, and ContainersReady. When the state of all pods is Ready, Pod Ready also becomes ready. However, in cloud-native scenarios, the status of pods needs to be determined in combination with other factors. ReadinessGate allows us to add fences for pod status determination so that the pod status can be determined and controlled by a third party, and the pod status can be associated with a third party.
CLB traffic comparison
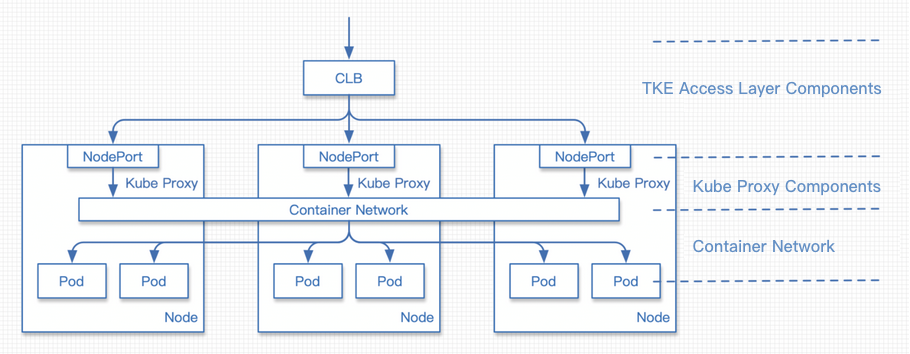
Traditional NodePort mode
The request process is as follows:
1. The request traffic reaches the CLB.
2. The request is forwarded by the CLB to the NodePort of a certain node.
3. KubeProxy performs NAT forwarding for the traffic from the NodePort, with the destination address being the IP address of a random pod.
4. The request reaches the container network and is then forwarded to the corresponding node based on the pod address.
5. The request reaches the node to which the destination pod belongs and is then forwarded to the pod.
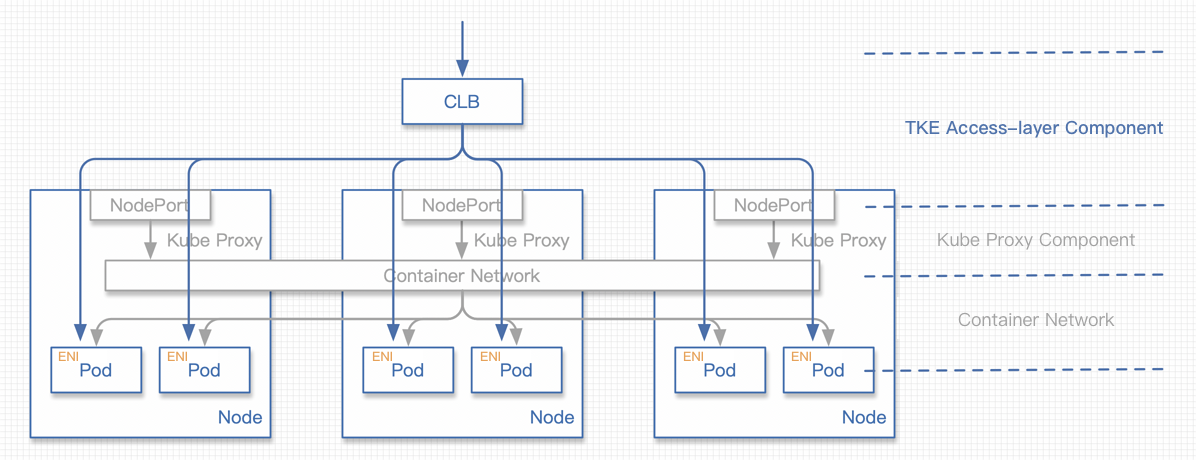
New direct pod connection mode
The request process is as follows:
1. The request traffic reaches the CLB.
2. The request is forwarded by the CLB to the ENI of a certain pod.
Differences between direct connection and local access
There is little difference in terms of performance. When local access is enabled, traffic is not subject to NAT operations or cross-node forwarding, and only another route to the container network is added.
The source IP address can be obtained correctly without NAT operations. The session persistence feature may be abnormal in this condition: when multiple pods exist on a node, traffic is randomly allocated to different pods. This mechanism may cause session persistence problems.
Introduction of ReadinessGate
Issues related to rolling updates
To introduce ReadinessGate, the cluster version must be 1.12 or later.
When users start the rolling update of an app, Kubernetes performs the rolling update according to the update policy. However, the identifications that it uses to determine whether a batch of pods has started only includes the statuses of the pods, but does not consider whether a health check is configured for the pods in the CLB and the pods have passed the check. If such pods cannot be scheduled in time when the access layer components experience a heavy load, the pods that have successfully completed the rolling update may not be providing services to external users, resulting in service interruption.
In order to associate the backend status of the CLB and rolling update, the new feature ReadinessGate, which was introduced in Kubernetes 1.12, was introduced into the TKE access-layer components. With this feature, only after the TKE access-layer components confirm that the backend binding is successful and the health check is passed, will the state of ReadinessGate be configured to enable the pods to enter the Ready state, thus facilitating the rolling update of the entire workload.
Using ReadinessGate in a cluster
Kubernetes clusters provide a service registration mechanism. With this mechanism, you only need to register your services to a cluster as MutatingWebhookConfigurations resources. When a pod is created, the cluster will deliver notifications to the configured callback path. At this time, the pre-creation operation can be performed for the pod, that is, ReadinessGate can be added to the pod.
Note:
This callback process must be based on HTTPS. That is, the CA that issues requests must be configured in MutatingWebhookConfigurations, and a certificate issued by the CA must be configured on the server.
Disaster recovery of the ReadinessGate mechanism
Service registration or certificates in user clusters may be deleted by users, but these system component resources should not be modified or destroyed by users. However, such problems will inevitably occur due to users’ exploration of clusters or improper operations.
The access layer components will check the integrity of the resources above during launch. If their integrity is compromised, the components will rebuild these resources to enhance the robustness of the system.
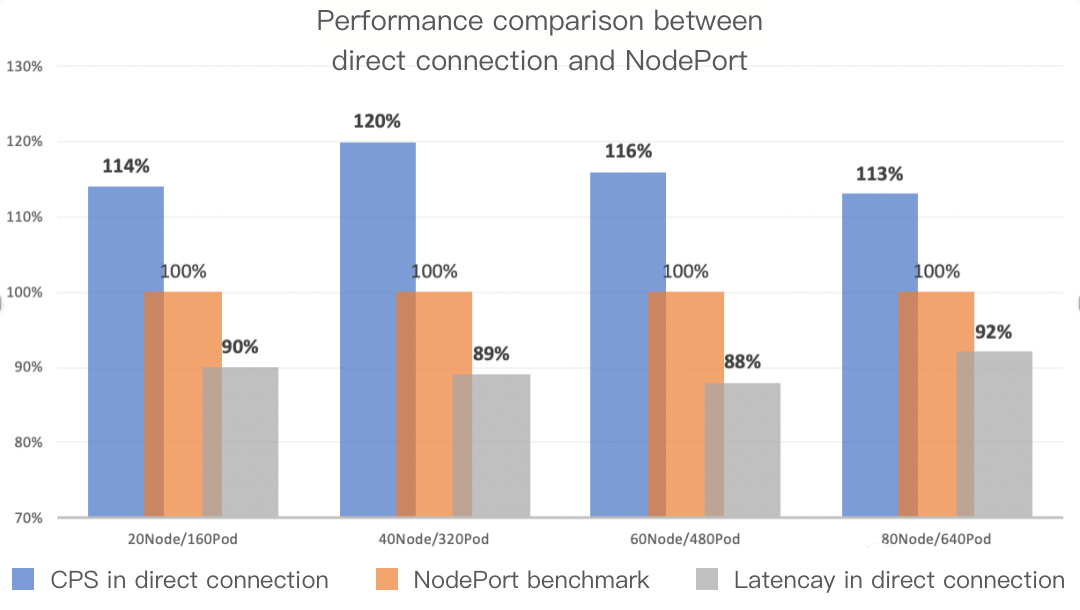
QPS and network latency comparison
Direct connection and NodePorts are the access layer solutions for service applications. In fact, the workloads deployed by users are the ultimate workers, and therefore the capabilities of user workloads directly determine the QPS and other metrics of services.
For these two access-layer solutions, we performed some comparative tests on network link latency under low workload pressure. The latency of direct connection on the network link of the access layer can be reduced by 10%, and traffic in the VPC network was greatly reduced. During the tests, the cluster size was gradually increased from 20 nodes to 80 nodes, and the wrk tool was used to test the network latency of the cluster. The comparison of QPS and network latency between direct connection and NodePorts is shown in the following figure:
KubeProxy design ideas
KubeProxy has some disadvantages, but based on the various features of CLB and VPC network, we have a more localized access layer solution. KubeProxy offers a universal and fault-tolerant design for the cluster access layer. It is basically applicable to clusters in all business scenarios. As an official component, this design is very appropriate.
New Mode Usage Guide
Prerequisites
The Kubernetes version of the cluster is 1.12 or later.
1. The VPC-CNI ENI mode is enabled for the cluster network mode.
2. The workloads used by a service in direct connection mode adopts the VPC-CNI ENI mode.
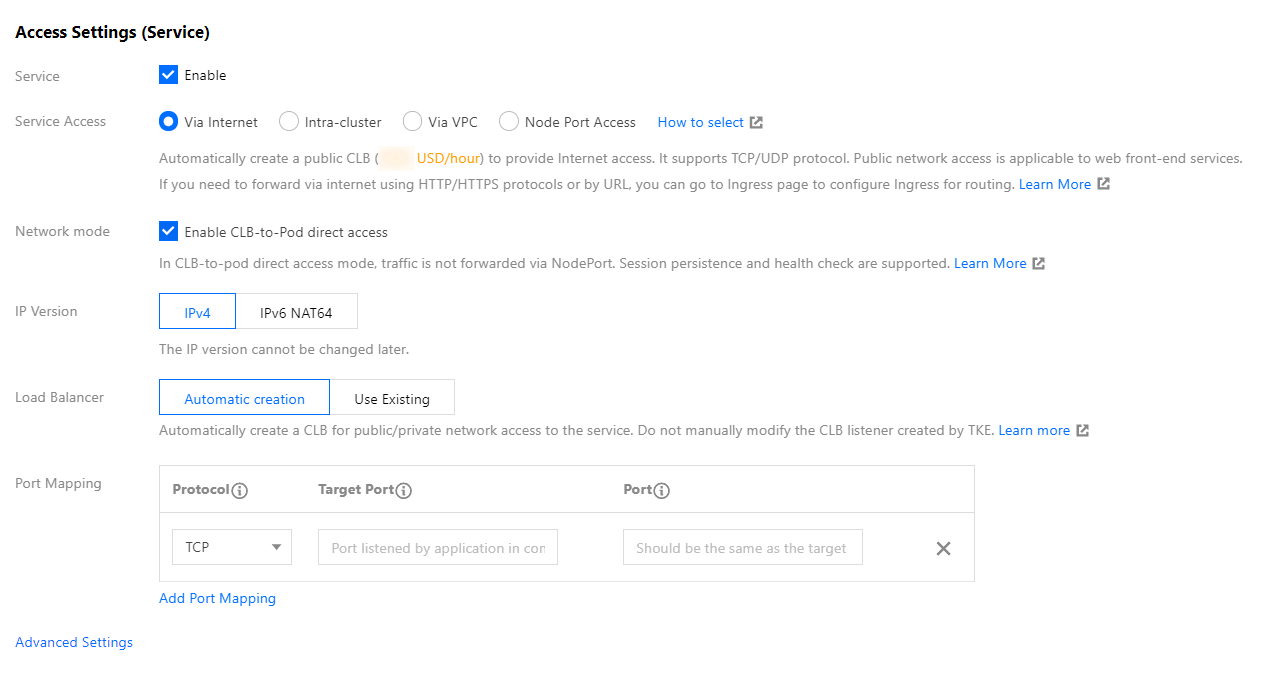
2. Refer to the steps of creating a service in the console and go to the "Create a Service" page to configure the service parameters as required.
Configure the main parameters, as shown in the following figure:
Service Access Mode: select Provide Public Network Access or VPC Access.
Network Mode: select Direct CLB-Pod Connection Mode.
Workload Binding: select Import Workload. In the window that appears, select the backend workload in VPC-CNI mode.
3. Click Create Service to complete the creation process.
Kubectl operation instructions
Workload example: nginx-deployment-eni.yaml
Note:
Note: spec.template.metadata.annotations declares tke.cloud.tencent.com/networks: tke-route-eni, meaning that the workload uses the VPC-CNI ENI mode.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
name: nginx-deployment-eni
spec:
replicas:3
selector:
matchLabels:
app: nginx
template:
metadata:
annotations:
tke.cloud.tencent.com/networks: tke-route-eni
labels:
app: nginx
spec:
containers:
-image: nginx:1.7.9
name: nginx
ports:
-containerPort:80
protocol: TCP
Service example: nginx-service-eni.yaml
Note:
metadata.annotations declares service.cloud.tencent.com/direct-access: "true", meaning that, when synchronizing the CLB, the service configures the access backend by using the direct connection method.
apiVersion: v1
kind: Service
metadata:
annotations:
service.cloud.tencent.com/direct-access:"true"
labels:
app: nginx
name: nginx-service-eni
spec:
externalTrafficPolicy: Cluster
ports:
-name: 80-80-no
port:80
protocol: TCP
targetPort:80
selector:
app: nginx
sessionAffinity: None
type: LoadBalancer
Deploying Cluster
Note:
In the deployment environment, you must first connect to a cluster (if you do not have a cluster, create one.) You can refer to the Help Document to configure kubectl to connect to a cluster.
➜ ~ kubectl apply -f nginx-deployment-eni.yaml
deployment.apps/nginx-deployment-eni created
➜ ~ kubectl apply -f nginx-service-eni.yaml
service/nginx-service-eni configured
➜ ~ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
Currently, TKE uses ENI to implement the direct pod connection mode. We will further optimize this feature, including in the following respects:
Implement direct pod connection under a common container network, without dependency on the VPC-ENI network mode.
Support the removal of the CLB backend before pod deletion.
Comparison with similar solutions in the industry:
AWS has a similar solution that implements direct pod connection through ENI.
Google Kubernetes Engine (GKE) has a similar solution that integrates the Network Endpoint Groups (NEG) feature of Google Cloud Load Balancing (CLB) to implement direct connection to pods at the access layer.