The fifth-generation Tencent Cloud CVM instances (including S6, S5, M5, C4, IT5, D3, etc.) all come with the 2nd generation Intel® Xeon® scalable processor Cascade Lake. These instances provides more instruction sets and features, which can accelerate the artificial intelligence (AI) applications. The integrated hardware enhancement technology, like Advanced Vector Extensions 512 (AVX-512), can boost the parallel computing performance for AI inference and produce a better deep learning result.
This document describes how to use AVX-512 on S5 and M5 CVM instances to accelerate AI application.
Recommended Models
Tencent Cloud provides various types of CVMs for different application development. The Standard S6, Standard S5 and Memory Optimized M5 instance types come with the 2nd generation Intel® Xeon® processor and support Intel® DL Boost, making them suitable for machine learning or deep learning. The recommended configurations are as follows:
Scenario
Instance Specifications
Deep learning training platform
84vCPU Standard S5 or 48vCPU Memory Optimized M5
Deep learning inference platform
8/16/24/32/48vCPU Standard S5 or Memory Optimized M5
Deep learning training or inference platform
48vCPU Standard S5 or 24vCPU Memory Optimized M5
Advantages
Running the workloads for machine learning or deep learning on Intel® Xeon® scalable processors has the following advantages:
Suitable for processing 3D-CNN topologies used in scenarios such as big-memory workloads, medical imaging, GAN, seismic analysis, gene sequencing, etc.
Flexible core support simply using the numactl command, and applicable to small-scale online inference.
Powerful ecosystem to directly perform distributed training on large clusters, without the need for a large-scale architecture containing additional large-capacity storage and expensive caching mechanisms.
Support for many workloads (such as HPC, BigData, and AI) in a single cluster to deliver better TCO.
Support for SIMD acceleration to meet the computing requirements of various deep learning applications.
The same infrastructure for direct training and inference.
Deploy an AI platform as instructed below to perform the machine learning or deep learning task:
Sample 1: optimizing the deep learning framework TensorFlow* with Intel®
PyTorch and IPEX on the 2nd generation Intel® Xeon® scalable processor Cascade Lake will automatically optimize AVX-512 instructions to maximize the computing performance.
TensorFlow* is a widely-used large-scale machine learning and deep learning framework. You can improve the instance training and inference performance as instructed in the sample below. More information about the framework, see Intel® Optimization for TensorFlow* Installation Guide. Follow these steps:
Deploying the TensorFlow* framework
1. Install Python in the CVM instance. This document uses Python 3.7 as an example.
2. Run the following command to install the Intel® optimized TensorFlow* intel-tensorflow.
Note:
The version 2.4.0 or later is recommended to obtain the latest features and optimization.
Batch inference: measures how many input tensors can be processed per second with batches of size greater than one. Typically, for batch inference, optimal performance is achieved by exercising all the physical cores on a CPU socket.
On-line Inference: (also called real-time inference) is a measurement of the time it takes to process a single input tensor, i.e. a batch of size one. In a real-time inference scenario, optimal throughput is achieved by running multiple instances concurrently.
Follow the steps below:
1. Run the following command to obtain the number of physical cores in the system.
lscpu |grep"Core(s) per socket"|cut -d':' -f2 |xargs
2. Set the optimization parameters using either method:
Set the runtime parameters. Add the following configurations in the environment variable file:
Latency performance:
We tested models of image classification and object detection at batch size one, and found improved inference performance of Intel Optimization for TensorFlow with AVX-512 instructions against the non-optimized version. For example, the latency performance of optimized ResNet 50 is reduced to 45% of the original version.
Throughput performance:
We tested models of image classification and object detection for throughput performance at large batch size, and found significant improvements. The throughput performance of optimized ResNet 50 is increased to 1.98 times of the original version.
Sample 2: deploying the learning framework PyTorch*
Deployment directions
1. Install Python 3.6 or a later version in the CVM instance. This document uses Python 3.7 as an example.
2. Compile and install PyTorch and Intel® Extension for PyTorch (IPEX) as intructed in Intel® Extension for PyTorch.
Setting runtime parameters
PyTorch and IPEX on the 2nd generation Intel® Xeon® scalable processor Cascade Lake will automatically optimize AVX-512 instructions to maximize the computing performance.
Batch inference: measures how many input tensors can be processed per second with batches of size greater than one. Typically, for batch inference, optimal performance is achieved by exercising all the physical cores on a CPU socket.
On-line Inference: (also called real-time inference) is a measurement of the time it takes to process a single input tensor at batch size one, i.e. a batch of size one. In a real-time inference scenario, optimal throughput is achieved by running multiple instances concurrently.
Follow the steps below:
1. Run the following command to obtain the number of physical cores in the system.
lscpu |grep"Core(s) per socket"|cut -d':' -f2 |xargs
2. Set the optimization parameters using either method:
Use GNU OpenMP* Libraries to set the runtime parameters. Add the following configurations in the environment variable file:
exportOMP_NUM_THREADS=physicalcores
exportGOMP_CPU_AFFINITY="0-<physicalcores-1>"
exportOMP_SCHEDULE=STATIC
exportOMP_PROC_BIND=CLOSE
Use Intel OpenMP* Libraries to set the runtime parameters. Add the following configurations in the environment variable file:
Inference and training optimizations in the PyTorch* deep learning model
Use Intel® Extension for PyTorch to improve performance of the model inference. The sample codes are as follows:
import intel_pytorch_extension
...
net = net.to('xpu')# Move model to IPEX format
data = data.to('xpu')# Move data to IPEX format
...
output = net(data)# Perform inference with IPEX
output = output.to('cpu')# Move output back to ATen format
Both inference and training can use jemalloc to improve performance. jemalloc is a general-purpose malloc(3) implementation that emphasizes fragmentation avoidance and scalable concurrency support. It is intended for use as the system-provided memory allocator. jemalloc provides much introspection, memory management, and tuning features beyond the standard allocator functionality. For more information, see jemalloc and sample codes.
Tested on the 2nd generation Intel® Xeon® scalable processor Cascade Lake with 2*CPU (28 cores per CPU) and 384 GB memory, different models obtain the performance data as shown in Intel and Facebook* collaborate to boost PyTorch* CPU performance. The performance result varies according to model and actual configurations.
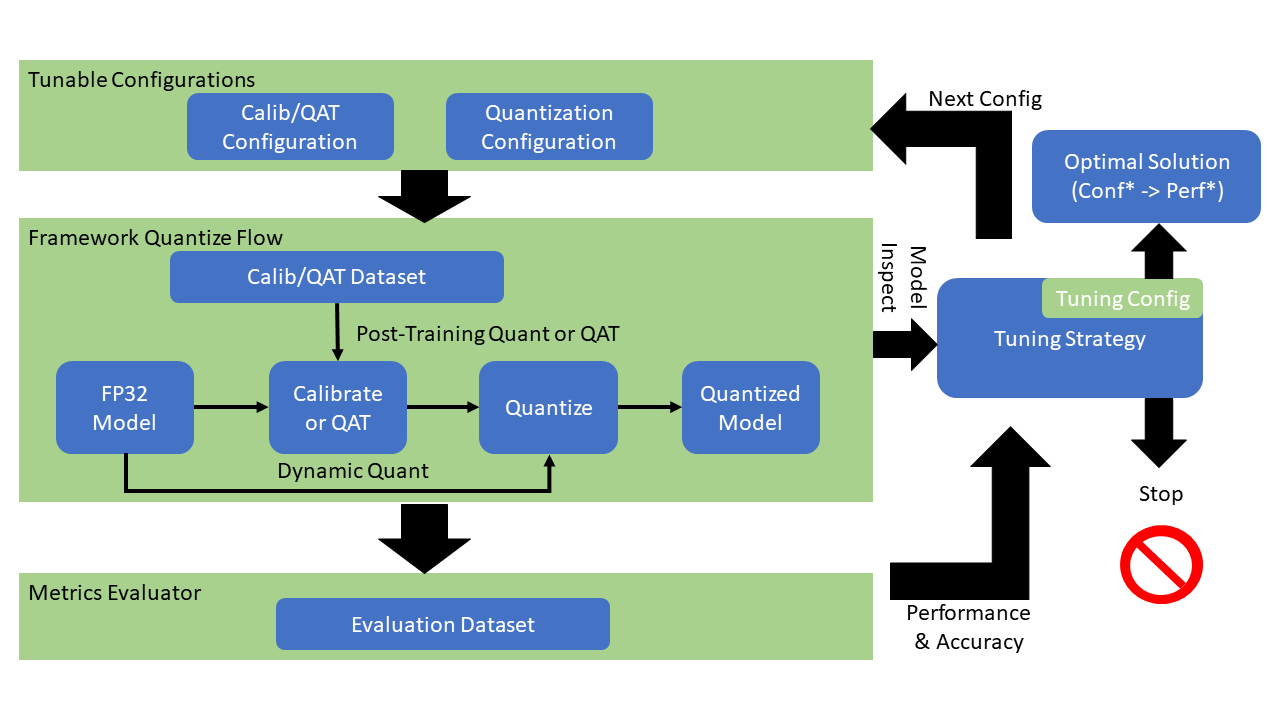
Sample 3: using Intel® AI Low Precision Optimization Tool for acceleration
The Intel® Low Precision Optimization Tool (Intel® LPOT) is an open-source Python library that delivers an easy-to-use low-precision inference interface across multiple neural network frameworks. It helps user quantify models, improve productivity, and accelerate the inference performance of low precision models on the 3rd generation Intel® Xeon® DL Boost scalable processor. For more information, see Intel® Low Precision Optimization Tool code repository.
Supported neural network frameworks
Intel® LPOT supports the following frameworks:
Intel® optimized TensorFlow*, including v1.15.0, v1.15.0up1, v1.15.0up2, v2.0.0, v2.1.0, v2.2.0, v2.3.0 and v2.4.0.
Intel® optimized PyTorch, including v1.5.0+cpu and v1.6.0+cpu.
Intel® optimized MXNet, including v1.6.0, v1.7.0; ONNX-Runtime: v1.6.0.
Implementation frameworks
The following figure shows the Intel® LPOT implementation frameworks:
Workflow
The following figure shows the Intel® LPOT workflow:
Performance and accuracy of quantized models
The table below shows the performance and accuracy achieved by Intel® LPOT optimized models on the 2nd Intel® Xeon® scalable processor Cascade Lake:
Framework
Version
Model
Accuracy
Performance speed up
INT8 Tuning Accuracy
FP32 Accuracy Baseline
Acc Ratio [(INT8-FP32)/FP32]
Realtime Latency Ratio[FP32/INT8]
tensorflow
2.4.0
resnet50v1.5
76.92%
76.46%
0.60%
3.37x
tensorflow
2.4.0
resnet101
77.18%
76.45%
0.95%
2.53x
tensorflow
2.4.0
inception_v1
70.41%
69.74%
0.96%
1.89x
tensorflow
2.4.0
inception_v2
74.36%
73.97%
0.53%
1.95x
tensorflow
2.4.0
inception_v3
77.28%
76.75%
0.69%
2.37x
tensorflow
2.4.0
inception_v4
80.39%
80.27%
0.15%
2.60x
tensorflow
2.4.0
inception_resnet_v2
80.38%
80.40%
-0.02%
1.98x
tensorflow
2.4.0
mobilenetv1
73.29%
70.96%
3.28%
2.93x
tensorflow
2.4.0
ssd_resnet50_v1
37.98%
38.00%
-0.05%
2.99x
tensorflow
2.4.0
mask_rcnn_inception_v2
28.62%
28.73%
-0.38%
2.96x
tensorflow
2.4.0
vgg16
72.11%
70.89%
1.72%
3.76x
tensorflow
2.4.0
vgg19
72.36%
71.01%
1.90%
3.85x
Framework
Version
Model
Accuracy
Performance speed up
INT8 Tuning Accuracy
FP32 Accuracy Baseline
Acc Ratio [(INT8-FP32)/FP32]
Realtime Latency Ratio[FP32/INT8]
pytorch
1.5.0+cpu
resnet50
75.96%
76.13%
-0.23%
2.46x
pytorch
1.5.0+cpu
resnext101_32x8d
79.12%
79.31%
-0.24%
2.63x
pytorch
1.6.0a0+24aac32
bert_base_mrpc
88.90%
88.73%
0.19%
2.10x
pytorch
1.6.0a0+24aac32
bert_base_cola
59.06%
58.84%
0.37%
2.23x
pytorch
1.6.0a0+24aac32
bert_base_sts-b
88.40%
89.27%
-0.97%
2.13x
pytorch
1.6.0a0+24aac32
bert_base_sst-2
91.51%
91.86%
-0.37%
2.32x
pytorch
1.6.0a0+24aac32
bert_base_rte
69.31%
69.68%
-0.52%
2.03x
pytorch
1.6.0a0+24aac32
bert_large_mrpc
87.45%
88.33%
-0.99%
2.65x
pytorch
1.6.0a0+24aac32
bert_large_squad
92.85
93.05
-0.21%
1.92x
pytorch
1.6.0a0+24aac32
bert_large_qnli
91.20%
91.82%
-0.68%
2.59x
pytorch
1.6.0a0+24aac32
bert_large_rte
71.84%
72.56%
-0.99%
1.34x
pytorch
1.6.0a0+24aac32
bert_large_cola
62.74%
62.57%
0.27%
2.67x
Note:
Both PyTorch and Tensorflow shown in the table are Intel-optimized frameworks.
Installing and using Intel® LPOT
1. Run the following commands sequentially to create a python3.x virtual environment named lpot in anaconda. This document uses python 3.7 as an example.
conda create -n lpot python=3.7
conda activate lpot
2. Install LPOT using either method:
Run the following command to install from a binary file.
pip install lpot
Run the following commands to install from source.
git clone https://github.com/intel/lpot.git
cd lpot
pip install -r requirements.txt
python setup.py install
3. Quantify TensorFlow ResNet50 v1.0, for example.
3.1 Prepare datasets.
Run the following commands to download and decompress the mageNet validation datasets.
3.3 Run the following commands to tune inference.
Modify the examples/tensorflow/image_recognition/resnet50_v1.yaml file so that the path of quantization\\calibration, evaluation\\accuracy and evaluation\\performance datasets point to your local actual path, i.e., the location of the TFrecord data generated in the dataset preparations. For more information, see ResNet50 V1.0.
The results are as follows, in which the performance data is only for reference:
accuracy mode benchmarkresult:
Accuracy is 0.739
Batch size =32
Latency: 1.341 ms
Throughput: 745.631 images/sec
performance mode benchmark result:
Accuracy is 0.000
Batch size =32
Latency: 1.300 ms
Throughput: 769.302 images/sec
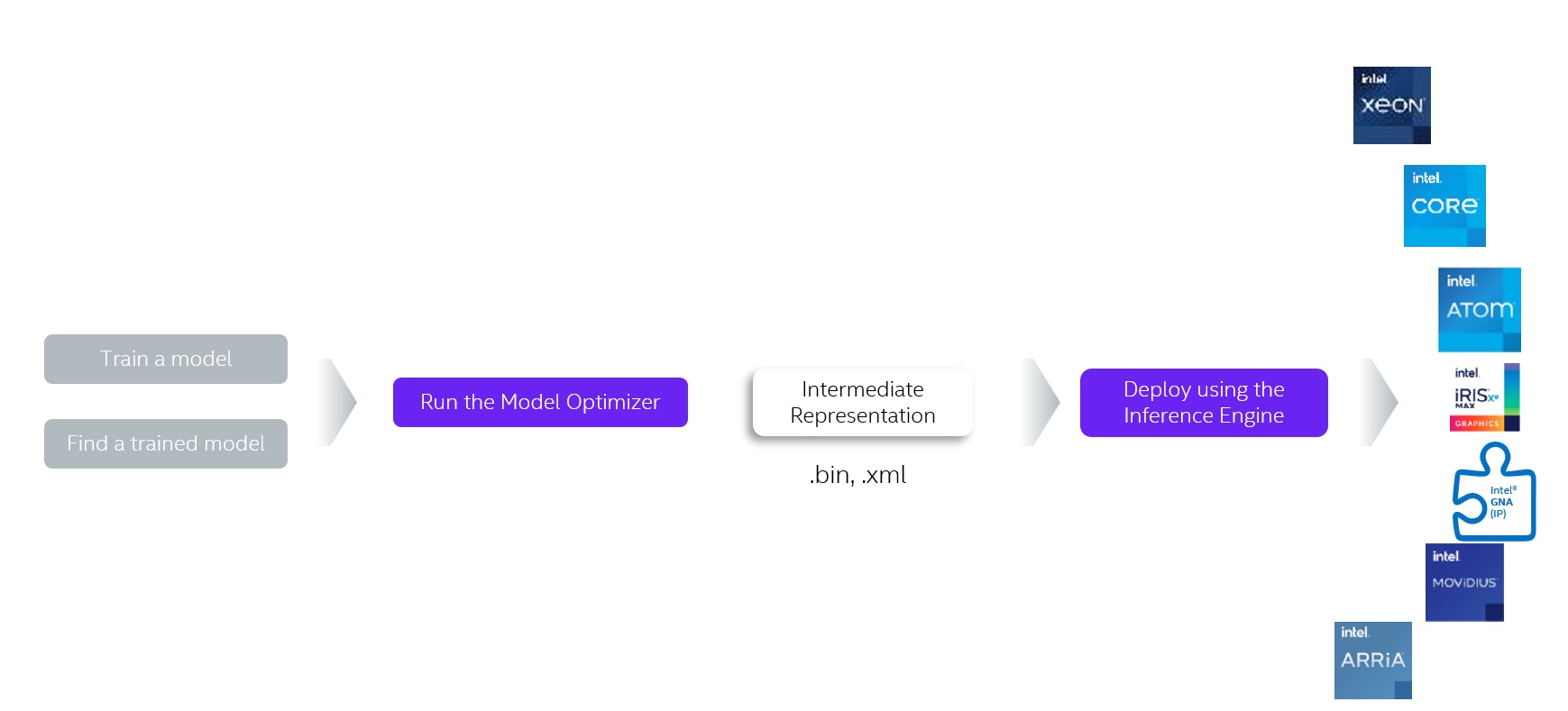
Sample 4: using Intel® Distribution of OpenVINO™ Toolkit for inference acceleration
Intel® Distribution of OpenVINO™ Toolkit is a comprehensive toolkit for quickly deploying computer vision and other deep learning applications. It supports various Intel accelerator including VPU for CPU, GPU, FPGA and Movidius, and also supports direct heterogeneous hardware execution.
Intel® Distribution of OpenVINO™ Toolkit optimizes models trained by TensorFlow* and PyTorch*. It includes Model Optimizer, Inference Engine, Open Model Zoo, Post-training Optimization Tool:
Model Optimizer: coverts models that were trained in frameworks such as Caffe*, TensorFlow*, PyTorch* and Mxnet* to intermediate representations (IRs).
Inference Engine: places the converted IRs on many hardware types including CPU, GPU, FPGA and VPU to enable inference acceleration with an automatic call to the hardware accelerator toolkit.
The following figure shows the workflow of Intel® Distribution of OpenVINO™ Toolkit:
Intel® Distribution of OpenVINO™ Toolkit inference performance
The Intel® Distribution of OpenVINO™ provides optimization implementations on multiple Intel processors and accelerator hardware. Based on the Intel® Xeon® scalable processor, it accelerates the inference network using Intel® DL Boost and AVX-512 instructions.
Using Intel® Distribution of OpenVINO™ Toolkit - Deep Learning Development Toolkit (DLDT)



 Yes
Yes
 No
No
Was this page helpful?