Hadoop 工具
Download
聚焦模式
字号
使用/咨询问题
什么是 Hadoop-COS 工具?
Hadoop-COS 为 Apache Hadoop、Spark 以及 Tez 等大数据计算框架集成提供支持,可以像访问 HDFS 一样读写存储在腾讯云 COS 上的数据。同时也支持作为 Druid 等查询与分析引擎的 Deep Storage。
自建 Hadoop 如何使用 Hadoop-COS jar 包?
更改 Hadoop-COS pom 文件保持版本与 Hadoop 版本相同进行编译,然后将 Hadoop-COS jar 包和 COS JAVA SDK jar 包放到 hadoop/share/hadoop/common/lib 目录下。具体配置可参考 Hadoop 工具 文档。
Hadoop-COS 工具中是否存在回收站机制?
HDFS 的回收站功能并不适用于 COS,使用 Hadoop-COS,通过
hdfs fs 命令删除 COS 数据,数据会被移动到 cosn://user/${user.name}/.Trash 目录下,并不会发生实际的删除行为,数据仍然会保留在 COS 上。另外您也可以使用 -skipTrash 参数来跳过回收站功能,直接删除数据。如需实现类似 HDFS 回收站定期删除数据的目的,请为对象前缀为 /user/${user.name}/.Trash/ 的对象配置生命周期规则,配置指引请参见 配置生命周期规则。找不到类 CosFileSystem 问题
加载的时候提示没有找到类 CosFileSystem?提示 Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.fs.CosFileSystem not found。
可能原因1
配置已经正确加载,但是 hadoop classpath 没有包含 Hadoop-COS jar 包位置。
解决办法
加载 Hadoop-COS jar 包位置到 hadoop classpath。
可能原因2
mapred-site.xml 这个配置文件中 mapreduce.application.classpath 里没有包含 Hadoop-COS jar 包位置。
解决办法
在 mapred-site.xml 这个配置文件中,mapreduce.application.classpath 里加上 cosn jar 所在路径,重启服务即可。
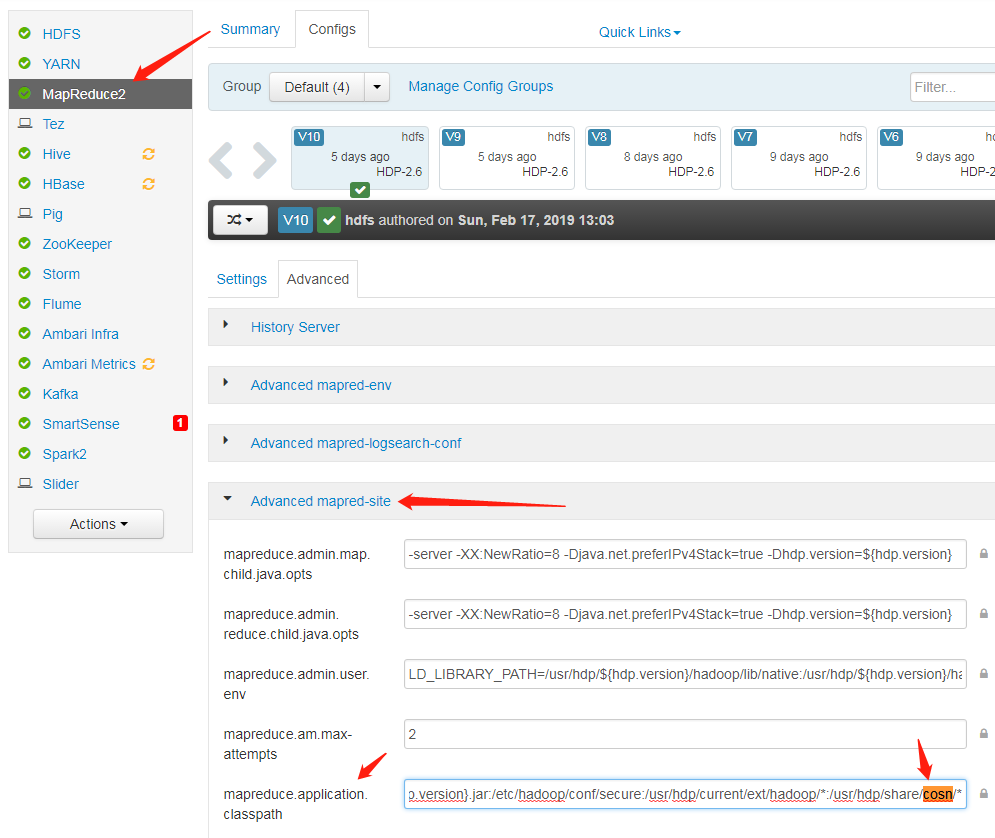
在使用官方 Hadoop 的时候提示没有找到类 CosFileSystem?
Hadoop-COS 维护了官方 Hadoop 版本和 Hadoop-COS 版本,对应的 fs.cosn.impl 和 fs.AbstractFileSystem.cosn.impl 配置不同。
官方 Hadoop 配置:
<property><name>fs.cosn.impl</name><value>org.apache.hadoop.fs.cosn.CosNFileSystem</value></property><property><name>fs.AbstractFileSystem.cosn.impl</name><value>org.apache.hadoop.fs.cosn.CosN</value></property>
tencent cos 配置:
<property><name>fs.cosn.impl</name><value>org.apache.hadoop.fs.CosFileSystem</value></property><property><name>fs.AbstractFileSystem.cosn.impl</name><value>org.apache.hadoop.fs.CosN</value></property>
频控和带宽问题
为什么会有503错误?
在大数据场景并发度较高的情况可能会触发 COS 的频控后会抛出503 Reduce your request rate 错误异常。您可以通过配置 fs.cosn.maxRetries 参数来对错误请求进行重试,该参数默认是200次。
为什么设置了带宽限速没有生效?
分块问题
如何合理设置 Hadoop-COS 上传的分块大小?
Hadoop-COS 内部通过分块并发上传来处理大文件,通过配置 fs.cosn.upload.part.size(Byte) 来控制 COS 上传的分块大小。
由于 COS 的分块上传最多只能支持10000块,因此需要预估最大可能使用到的单文件大小。例如,block size 为8MB时,最大能够支持78GB的单文件上传。 block size 最大可以支持到2GB,即单文件最大可支持19TB。超过10000块后会抛出400错误异常,可以通过检查该配置是否正确。
为什么在上传较大文件时查看 COS 上的文件可能会有延迟,不会实时地显示出来?
Hadoop-COS 对于大文件,即超过一个 blockSize(fs.cosn.upload.part.size) 的文件都采用分块上传,只有所有分块上传到 COS 完成后文件才可见。Hadoop-COS 暂时不支持 Append 操作。
Buffer 问题
如何选择上传的 Buffer 类型?他们的区别是什么?
Hadoop-COS 上传可选择 buffer 类型,使用 fs.cosn.upload.buffer 参数进行设置,可设置为以下3个中的一个。
mapped_disk 默认配置,需要将 fs_cosn.tmp.dir 设置到空间足够大的目录下,避免跑任务时打满磁盘。
direct_memory :使用 JVM 堆外内存(这部分不受 JVM 管控,所以不建议配置)。
non_direct_memory:使用 JVM 堆内存;建议配置128M。
buffer 类型为 mapped_disk 时提示创建 buffer 失败?提示 create buffer failed. buffer type: mapped_disk, buffer factory:org.apache.hadoop.fs.buffer.CosNMappedBufferFactory?
可能原因
当前用户对 Hadoop-COS 使用的临时目录没有读写访问权限。Hadoop-COS 默认使用的临时目录是:/tmp/hadoop_cos。也可由用户配置 fs.cosn.tmp.dir 来指定。
解决办法
为当前用户赋予 /tmp/hadoop_cos 或者 fs.cosn.tmp.dir 指定的临时文件目录赋予读写权限。
运行异常问题
在执行计算任务过程中抛出异常信息 java.net.ConnectException: Cannot assign requested address (connect failed) (state=42000,code=40000),该如何处理?
出现 Cannot assign requested address 错误一般是因为用户在短时间内建立了大量的 TCP 短连接,而连接关闭后,本地端口并不会被立即回收,而是默认经过一个60秒的超时阶段,因此导致客户端在这段时间内,没有可用端口用于与 Server 端建立 Socket 连接。
解决方法
修改
/etc/sysctl.conf 文件,调整如下内核参数进行规避:net.ipv4.tcp_timestamps = 1 #打开 TCP 时间戳的支持net.ipv4.tcp_tw_reuse = 1 #支持将处于 TIME_WAIT 状态的 socket 用于新的 TCP 连接net.ipv4.tcp_tw_recycle = 1 #启用处于 TIME-WAIT 状态的 socket 的快速回收net.ipv4.tcp_syncookies=1 #表示开启 SYN Cookies。当出现 SYN 等待队列溢出时,启用 cookie 来处理,可防范少量的 SYN 攻击。默认为0net.ipv4.tcp_fin_timeout = 10 #端口释放后的等待时间net.ipv4.tcp_keepalive_time = 1200 #TCP 发送 KeepAlive 消息的频度。缺省是2小时,改为20分钟net.ipv4.ip_local_port_range = 1024 65000 #对外连接的端口范围。默认是32768至61000,改为1024至65000net.ipv4.tcp_max_tw_buckets = 10240 #TIME_WAIT 状态 Socket 的数量限制,如果超过了这个数量,新来的 TIME_WAIT 套接字会被直接释放,默认值是180000。适当地降低该参数可以减小处于 TIME_WAIT 状态 Socket 的数量
在上传文件时有异常:java.lang.Thread.State: TIME_WAITING (parking),具体堆栈包含 org.apache.hadoop.fs.BufferPoll.getBuffer 和 java.util.concurrent.locks.LinkedBlockingQueue.poll被锁住的情况?
可能原因
上传文件时初始化了多次 buffer,但是没有触发实际的写操作。
解决方法
可以更改如下配置:
<property><name>fs.cosn.upload.buffer</name><value>mapped_disk</value></property><property><name>fs.cosn.upload.buffer.size</name><value>-1</value></property>
文档反馈